Algorytmy rekomendacyjne - przykład implementacji w Pythonie

Gdy robimy zakupy w internecie, często zdarza się, że przez kolejne dni pokazują nam się propozycje produktów, podobnych do tych, które wcześniej oglądaliśmy. Atrakcyjne ceny powodują, iż czasem ulegamy presji reklamy, decydujemy się na zapoznanie się z ofertą i…dokonujemy zakupu. Jak to się dzieje, że przeglądarka wie, co chcemy kupić, zobaczyć czy posłuchać? Za to wszystko odpowiadają systemy rekomendacyjne.
Systemy rekomendacyjne widzimy wszędzie tam, gdzie użytkownik ma styczność z ogromnymi katalogami danych, np. Amazon podpowiada nam, jakie produkty powinniśmy kupić, Netflix - jakie filmy oglądać, a Spotify - które utwory na pewno nam się spodobają. Wykorzystywane są przez coraz większą ilość usług, a ich popularność stale rośnie. Odpowiada za to koncepcja “Long Tail”.
W 1988 roku brytyjski alpinista Joe Simpson napisał książkę pod tytułem „Touching the Void”, w której opisał swoje zmagania w peruwiańskich Alpach. Publikacja cieszyła się zainteresowaniem, wkrótce jednak zostałaby zapomniana, gdyby nie Jon Krakauer, który dekadę później napisał „Into Thin Air”, czyli kolejną pozycję o wspinaczkowych starciach. Po jej wydaniu książka Joe Simspona nagle wróciła do sprzedaży, nastąpiły dodruki, aby nadążyć za popytem. Co więcej, przez czternaście tygodni znajdowała się na liście bestsellerów NewYork Times i sprzedano jej dwukrotnie więcej niż dzieło Krakauera! Dlaczego tak się stało? Otóż Amazon zarekomendował książkę „Touching the Void” podczas zakupu „Into Thin Air”, jako książkę, która również może spodobać się kupującemu. Teoria Long Tail sugeruje, że na rynku internetowym sumaryczny dochód ze sprzedaży pojedynczych towarów niszowych, może generować wyższe zyski, niż oferowane masowo produkty popularne, tzw. bestsellery.
Najciekawszym rodzajem rekomendacji są te bazujące na danych o konkretnych użytkownikach. Możemy tu wyróżnić dwa podejścia:
- Content Based Filtering, który opiera się na cechach, typach produktów, szukając podobnych do tych, które użytkownik już ocenił pozytywnie lub kupił,
- Collaborative Filtering, czyli rekomendacje na podstawie ocen i zakupów użytkownika. Gdy dwóch użytkowników kupuje podobne produkty, możemy stwierdzić, że mają zbliżone upodobania i polecać im wzajemnie sprawdzone dla nich artykuły.
Collaborative Filtering – przykład implementacji
Collaborative Filtering dzieli się na jeszcze dwa rodzaje:
- Item-based, który bazując tylko na ocenach, wyszukuje podobne przedmioty i je rekomenduje,
- User-based, którego przykład implementacji szerzej omówimy.
Zasada jest prosta. Wyobraźmy sobie, że mamy użytkownika X. Dla tego użytkownika znajdujemy grupę innych użytkowników, którzy są do siebie podobni, np. zgodnie oceniają te same filmy. Jest to tzw. sąsiedztwo użytkownika X. W tej grupie znajdujemy zbiór filmów, które również są przez nią wysoko oceniane, a użytkownik X ich nie oglądał i rekomendujemy mu je. Dane, z których skorzystałam, pochodzą ze strony MovieLens. W zbiorze danych znajduje się m.in. 100.000 ocen użytkowników w skali 1-5.
import pandas as pd
ratings_columns = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_csv('u.data', sep='\t', names=ratings_columns, encoding='latin-1')
ratings.drop( "timestamp", inplace = True, axis = 1 )
print ratings.shape
ratings.head(10)
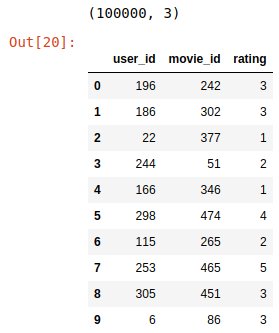
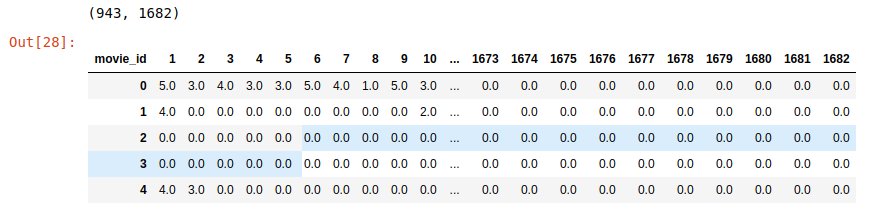
Na podstawie tej tabelki utworzymy macierz ocen filmów userId x movieId.
user_movies = ratings.pivot( index='user_id', columns='movie_id', values = "rating" ).reset_index(drop=True)
user_movies.fillna( 0, inplace = True )
user_movies=pd.DataFrame(user_movies)
print user_movies.shape
user_movies.head()
Kolejnym krokiem jest wyznaczenie n-tego sąsiedztwa użytkownika X, czyli grupy najbardziej podobnych mu osób. Aby to zrobić, potrzebujemy miary podobieństwa między użytkownikami, których istnieje mnogość, m.in. miarę cosinusową, współczynnik Jaccarda. Ja użyję współczynnika korelacji Pearsona. Miara ta mieści się w przedziale zamkniętym [-1, 1], gdzie 1 będzie oznaczała stuprocentowe podobieństwo.
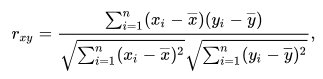
Nie pokuszę się jednak o implementację tego wzoru, a wykorzystam gotową funkcję z biblioteki SciPy.
from sklearn.metrics.pairwise import pairwise_distances
users_similarity = 1 - pairwise_distances( user_movies.as_matrix(), metric="correlation" )
users_similarity_df = pd.DataFrame( users_similarity )
print users_similarity.shape
users_similarity_df.head()

Otrzymaliśmy macierz userId x userId z wyliczonymi wartościami podobieństwa między każdym użytkownikiem. Możemy też z niej zauważyć, że użytkownicy są najbardziej podobni do… samych siebie (wartość 1 po przekątnej macierzy). Do dalszych obliczeń wypełnilibyśmy przekątną macierzy zerami, aby nie zakłamywać wyników. Tak to wygląda krok po kroku. Tak naprawdę Python ułatwia nam obliczenia jeszcze bardziej, oferując metodę NearestNeighbors z biblioteki sklearn, w której to możemy podać np. wielkość szukanego sąsiedztwa, czy metodę obliczania podobieństwa.
from sklearn.neighbors import NearestNeighbors
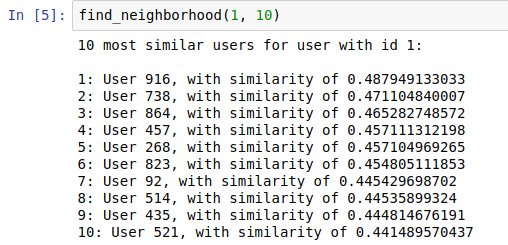
def find_neighborhood(user_id, n):
model_knn = NearestNeighbors(metric = "correlation", algorithm = "brute")
model_knn.fit(user_movies)
distances, indices = model_knn.kneighbors(user_movies.iloc[user_id-1, :].values.reshape(1, -1), n_neighbors = n+1)
similarities = 1-distances.flatten()
print '{0} most similar users for user with id {1}:\n'.format(n, user_id)
for i in range(0, len(indices.flatten())):
# pomiń, jeśli ten sam użytkownik
if indices.flatten()[i]+1 == user_id:
continue;
else:
print '{0}: User {1}, with similarity of {2}'.format(i, indices.flatten()[i]+1, similarities.flatten()[i])
return similarities,indices
Powyższa funkcja posłuży nam do wylistowania sąsiedztwa danego użytkownika. Przyjmuje ona id użytkownika, którego sąsiedztwa szukamy oraz jego rozmiar. Wykorzystując współczynnik korelacji Pearsona, na podstawie naszej pierwszej tabelki z ocenami użytkowników otrzymamy odległości między użytkownikiem „wejściowym” a każdym pozostałym oraz odpowiadające im id userów. Następnie w pętli możemy wylistować sąsiedztwo użytkownika, pomijając przy tym jego samego.
 Następnym krokiem będzie przywidywanie ocen użytkownika.
Następnym krokiem będzie przywidywanie ocen użytkownika.
import numpy as np
def predict_rate(user_id, item_id, n):
similarities, indices=find_neighborhood(user_id, n)
neighborhood_ratings =[]
for i in range(0, len(indices.flatten())):
if indices.flatten()[i]+1 == user_id:
continue;
else:
neighborhood_ratings.append(user_movies.iloc[indices.flatten()[i],item_id-1])
weights = np.delete(indices.flatten(), 0) #delete weight for input user
prediction = round((neighborhood_ratings * weights).sum() / weights.sum())
print '\nPredicted rating for user {0} -> item {1}: {2}'.format(user_id,item_id,prediction)
Za pomocą funkcji find_neighborhood znajdziemy dla niego sąsiedztwo n użytkowników, którzy ocenili film, którego ocenę będziemy przewidywać. Z taką wiedzą, w pętli tworzymy listę ocen danego filmu przez podobnych mu użytkowników. Jak teraz obliczyć prawdopodobną ocenę? Najprostszym z rozwiązań jest policzenie średniej ocen całego sąsiedztwa użytkownika dla tego filmu i zaprezentować to jako nasze przewidywanie. Niestety to rozwiązanie ignoruje wartość podobieństwa między użytkownikami, więc lepszym podejściem policzenie średniej ważonej. Jako wagi przyjmiemy „odległości” między użytkownikami, które zwróciła nam funkcja w zmiennej indices. Otrzymując spodziewany oceny użytkowników dla danych filmów, możemy zarekomendować mu listę filmów, które będą bliskie jego upodobaniom.

Podsumowanie
Powyższy przykład implementacji jest oczywiście bardzo podstawowym. Duże portale korzystają raczej z hybrydowych rozwiązań, próbując jak najbardziej trafnie oszacować nasze upodobania. Ich metody rekomendacji bazują na tak dużych danych i są tak czasochłonne, że rekomendacje nie są obliczane na bieżąco, po każdej ocenie użytkownika, czy po każdym zakupie, a są uaktualniane raz na kilka dni.
Podobne wpisy





