Event Tracking - finding a needle in a haystack

Systems based on Apache Kafka generally use more than one topic, with events that are part of a single process often flowing between them. In some cases the events remain unchanged but the records on consecutive topics can also be modified, e.g. by adding data that is needed at further steps of the process. Event Tracking enables monitoring and visualizing the path of a given event or process by means of Kafka topics.
As an example let’s look at the system for sending notifications to users. Before a given notification is ready to be sent, it might have to go through several topics where more information could be added, e.g. the notification’s content or channel that will be used to send it.
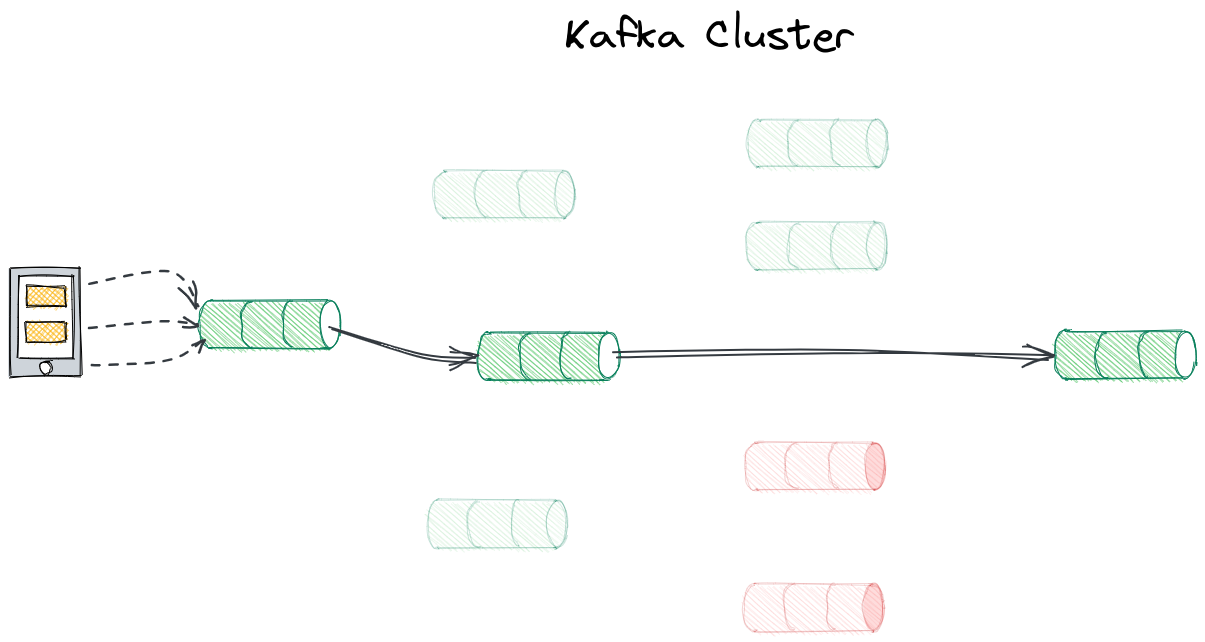 An example flow on Kafka
An example flow on Kafka
So how can you track the path of a single process among millions of them?
I have seen it somewhere
The problem is not new and goes back to the time of microservices. A scenario in which more than one microservice is involved in handling a given HTTP request requires an easy way to track logs related to the processing of the request irrespective of how many microservices are involved in this process. There is a well-known solution to this problem - when the request appears in the system, e.g. when it reaches the API Gateway, all you need is to generate a random string of characters, put it into the HTTP header and then make sure that the header is passed between the microservices as well as inject its values into the logging context.
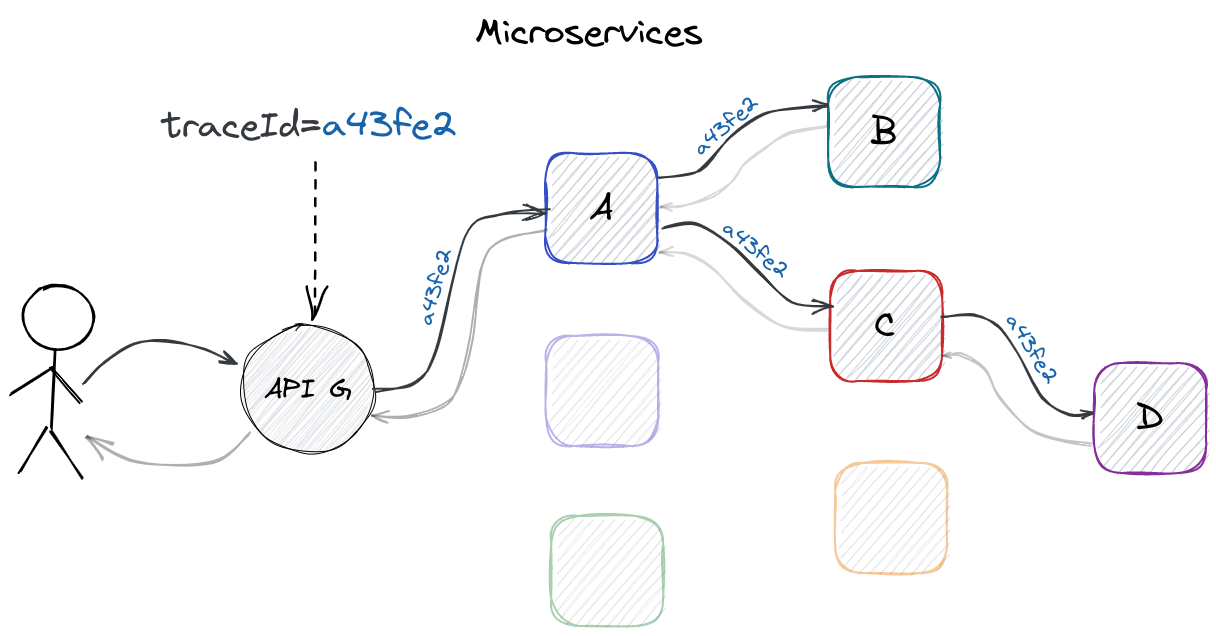 Tracking logs between microservices
Tracking logs between microservices
Thanks to this solution all logs related to the request will be related by means of the identifier generated at the beginning. All you need to do is to search for this identifier in one of the popular logs aggregators, such as Splunk (as long as this kind of tool is available to you), and as a result you will get logs related with the searched request.
But what does it have to do with Kafka?
Headers to the rescue
It turns out that the experience from correlating logs from the realm of microservices will come in handy for event tracking on Kafka. Similarly to HTTP messages, records on Kafka can be tied to headers, which are key-value metadata.
Using the pattern known from microservices where a record appears in the system for the first time, you generate a unique identifier and place it in the header. Next, analogically to how it is done in the case of microservices, when the event is travelling from one topic onto another you also pass the correlation header that is tied to it. Ideally, the value of the header is injected into the logging context as well.
 Passing the header between topics on Kafka
Passing the header between topics on Kafka
However, it is clear that mere passing of the headers between topics is still far from the result we are trying to achieve here.
So how should you go about it? Answering the following questions will be a good starting point:
- What? - What are you really looking for? What header and with what values?
- Where? - Which topics are you going to consider? Searching all topics might be too much, as usually you can limit the search to those with a particular functionality or flow.
- When? - If there are millions of records on Kafka, searching all of them would take ages. However, in many cases the processes need a couple of seconds or minutes to fully go through Kafka, which means that generally you can narrow down the searching scope to 5, 15 minutes or e.g. an hour.
Naturally, the narrower the search scope, the faster it will execute.
So how can you use these three questions and practically track the path of a process through Kafka?
Event Tracking in practice
There are no out-of-the-box mechanisms in Kafka that would allow you to do that in a simple way. However, the tool that we have developed - Kouncil - provides this exact functionality as well as additional features and optimizations. By going to the Track tab, you will find filters that will give you answers to the three questions above.
- First of all, you can specify what content in a header you are looking for. You can also select the way of matching the headline value with the actual value - it doesn’t have to be a 1-to-1 match. You can choose from operators such as equal to, not equal to, is included, is not included, and even regular expressions.
- Also, there is an option to specify the set of topics to be searched - in case there are hundreds or thousands of topics on the cluster, there is no need to search for them manually in the list - the topic selection component supports filtering.
- On top of that, it is possible to specify the time interval you are interested in.
 Filters on the Track tab
Filters on the Track tab
Filling those boxes manually each time might prove inconvenient but there’s a solution to this, which I will describe using the example of sending notifications from the beginning of the article. Let’s assume that there are topics on the cluster which are responsible for the process of sending notifications: notification-input, where the notifications are generated, as well as other topics, through which events pass depending on the use case. These topics could be notification-content, -channel, -template, -delivery etc., on which events could be complemented with the required data. For example, events for which a notification channel needs to be set will go onto the notification-channel topic.
Let’s have a look inside the notification-input topic:
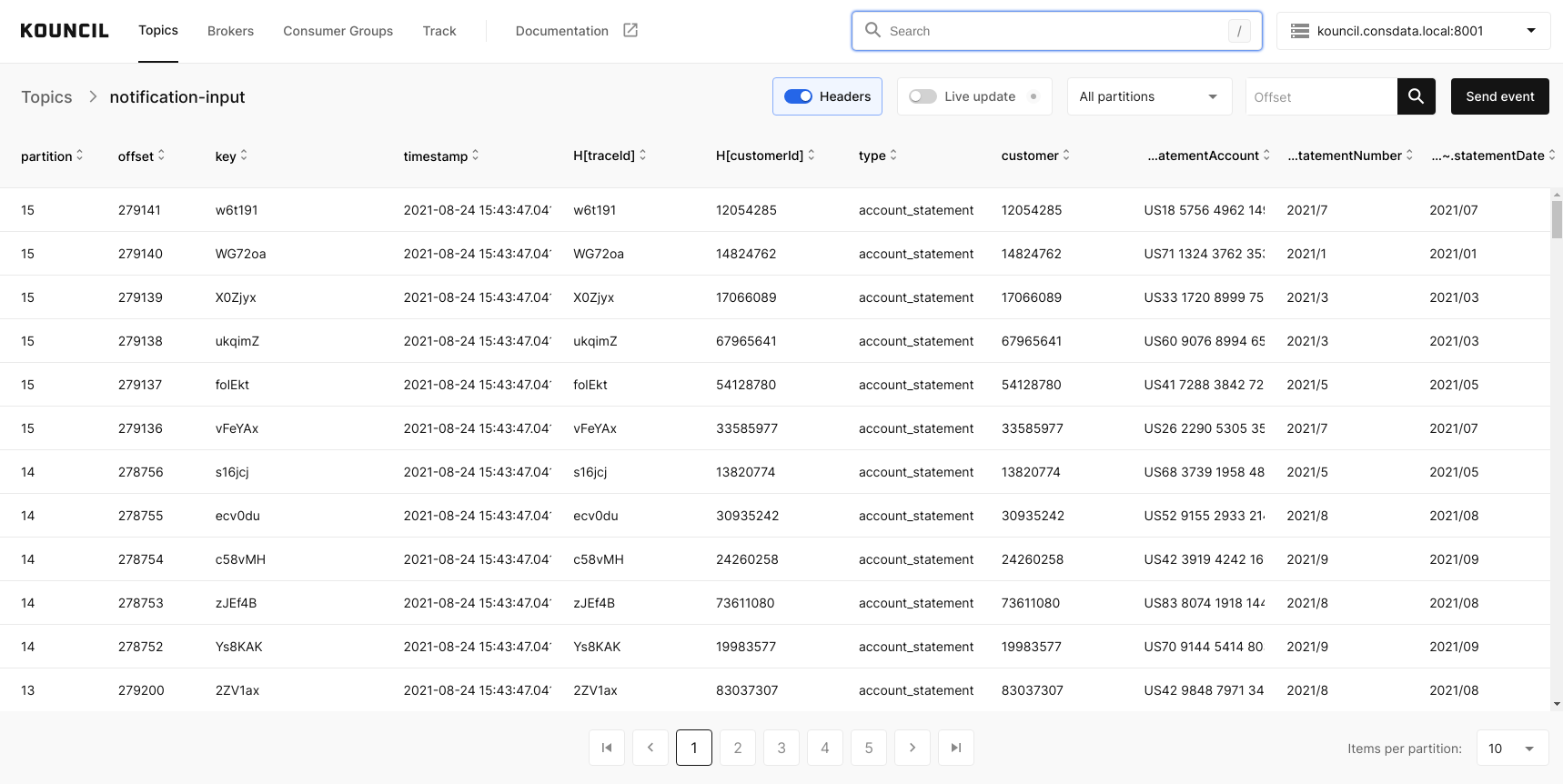 Notification-input topic
Notification-input topic
Let’s assume that you want to track the path of a record with a vFeYAx key. What you need to do is simply click the record to view its details and then click the header that you are interested in.
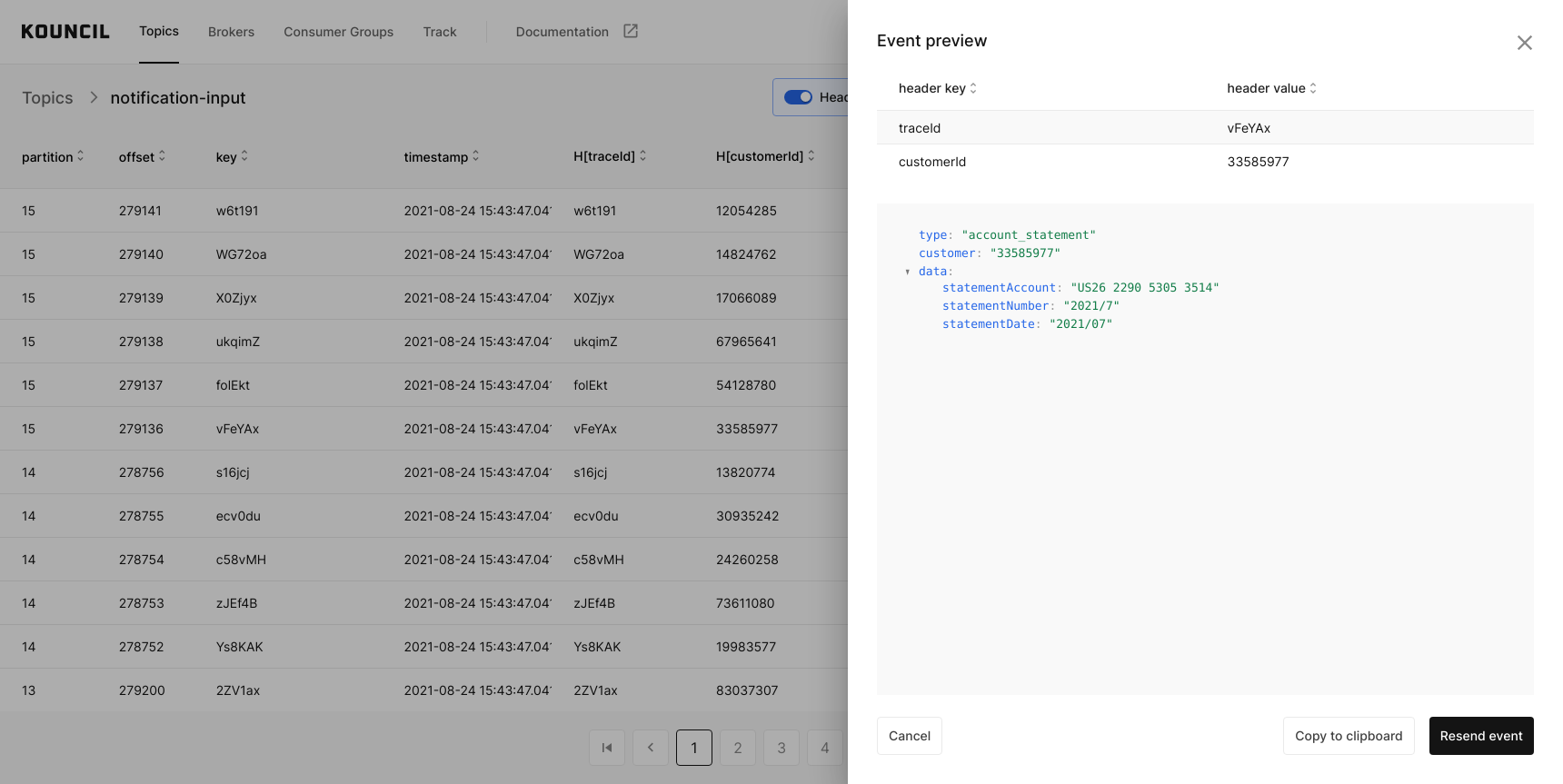 Selecting header
Selecting header
You will be automatically redirected to the Event Tracking tab where the filter boxes will be already filled in on the basis of the selected record. You only have to add the required topics because by default only the one with the event whose path you want to track will be selected.
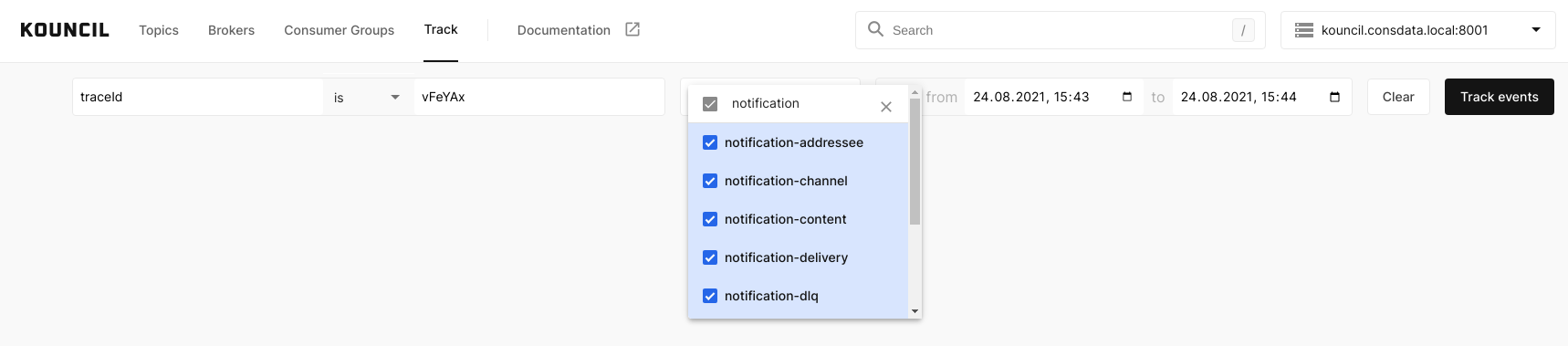 Automatically filled Event Tracking filter
Automatically filled Event Tracking filter
Now you need to click Track events and monitor in real time how Kouncil is retrieving records with a given header. By sorting the results by time you can not only see when and through which topics a given process was passed, but you can also view the record at every stage of the process.
![]() Event Tracking results
Event Tracking results
This way of analyzing the process flow on Kafka enables you to save a lot of time, especially in the case of more complex processes where records can return to a topic that they were located on before, or while analyzing erroneous scenarios in which a process could have found itself on topics that serve errors. Searching analogous information in application logs is possible but usually turns out more time-consuming, especially if a given process involves modules belonging to various systems, with no easy way of a collective search of their logs.
What’s important is that you can start event tracking at any point of the process - it could be its beginning, as in the case of the notification-input topic, as well as the very end of the topic’s flow - the result will be exactly the same.
Kouncil
Kouncil is free and its sources along with instructions are available on our GitHub. It is very easy to run and boils down to a single command, i.e. docker run, where you just need to point to any of the Kafka cluster nodes. The only thing Kouncil requires to support the Event Tracking is to ensure the existence of headers in the messages, while everything else related to searching the topics will be taken care of by our tool.
Translation by Piotr ŻurawskiSimilar posts