Dobór limitów pamięci w Javie (w kontenerach i nie tylko)


Geneza problemu
Słowem wstępu: nasz projekt działa na OpenShifcie, który jest niczym innym jak Kubernetesem z dodatkowymi bajerami. Z tego też tytułu wszystko tutaj dzieje się w kontenerach. Natomiast część wniosków, do których doszliśmy, aplikuje się nie tylko do procesów Javy chodzących w kontenerze, ale też Javy odpalonej “po staremu”, bez kontenerów.
A teraz do rzeczy: od pewnego czasu w tym projekcie obserwowaliśmy problemy z pamięcią - kontenery zaczęły być ubijane przez systemowy OOM Killer. Zwracam tutaj uwagę na różnicę pomiędzy standardowym javowym OOM Exception a systemowym OOM Killerem - to są dwie różne rzeczy. Kompletnie jednak nam się to nie spinało, tj. widzieliśmy kilka rozbieżności:
- W momencie ubijania kontenera przez systemowy OOM killer, większość znanych nam narzędzi do monitoringu (z samym OpenShiftem na czele) wskazywała, że ten kontener jeszcze nie dobił do limitu przydzielonej mu pamięci. Np. limit pamięci dla kontenera to 640MB, a systemowy OOM zabijał go w momencie, kiedy kontener teoretycznie bierze 600MB. Co się stało z tymi 40MB?
- W ramach kontenera chodzi wyłącznie jeden proces - Java. Posługując się poleceniem
ps aux, możemy sprawdzić, ile zajmuje rzeczywistej pamięci, patrząc na kolumnę RSS. Na ogół potrafi to być spore przybliżenie (albo i wprost - mało prawdziwa wartość) z uwagi na współdzielenie pamięci pomiędzy procesami, jednak w przypadku kontenera, na którym chodzi pojedynczy proces, jest to dobra metryka. I tutaj dochodzimy do drugiej rozbieżności: RSS procesu Javy wskazywał na zużycie pamięci większe o jakieś 100-150MB niż by to wynikało z sumy wartości Heapa oraz Off-Heapa podawanej przez JVM w Native Memory Tracking.
Analiza
Krótko mówiąc, ginęło nam w porywach kilkaset MB pamięci per kontener. Przy kilkuset kontenerach, które są odpalone na naszych środowiskach, sumuje się to do sporego problemu. Żeby się doliczyć tej zaginionej pamięci, musieliśmy znaleźć odpowiedzi na kilka pytań:
W jaki sposób faktycznie jest liczone zużycie pamięci przez kontener z punktu widzenia systemu operacyjnego?
Sprawa jest trochę bardziej zawiła niż w przypadku zwykłych procesów chodzących na hoście. Czym w ogóle są kontenery? Wyizolowanym procesem. Wbrew teoriom, na które można trafić, kontenery nie mają praktycznie nic wspólnego z maszynami wirtualnymi, nie ma w nich żadnej warstwy emulacji sprzętu, ani tym bardziej systemu. W szczególności, w kontenerze nie chodzi cały system operacyjny - kontenery współdzielą kernel z hostem, a procesy chodzące w ramach kontenera są niczym innym, jak zwykłymi procesami chodzącymi na hoście, jedynie w izolacji. I ta izolacja jest tutaj kluczowa. Bez wdawania się w zbyt duże szczegóły, za izolację (i tak w sumie za działanie kontenerów w ogóle) odpowiadają dwa mechanizmy kernela – namespaces oraz cgroups. W szczególności interesuje nas tutaj ten drugi - cgroups. Jest to mechanizm, który ogranicza zasoby (np. dostępną pamięć) procesom lub grupom procesów. W dużym uproszczeniu każdy kontener jest “zamknięty” w ramach własnej cgroupy. A ponieważ systemowy OOM killer patrzy właśnie na zużycie pamięci liczone z punktu widzenia cgroups, to kluczowe staje się ustalenie, jak zużycie pamięci kontenera wygląda z punktu widzenia cgroups.
Wszelkie komendy w stylu htop, docker stats, itp. są tutaj niewystarczające. Istnieje natomiast coś w rodzaju odpowiednika htop, który pokazuje zużycie pamięci dla poszczególych cgroup: systemd-cgtop. Przykładowe wyjście cgtopa wygląda tak:
Control Group Procs %CPU Memory Input/s Output/s
/ 49 44.1 26.9G - -
kubepods.slice - 15.7 18.2G - -
kubepod…urstable.slice - 15.7 17.8G - -
system.slice 32 16.6 7.7G - -
system.…urnald.service 1 5.9 3.7G - -
system.…e/crio.service 4 1.3 3.4G - -
kubepod…d4422dd7.slice - 2.1 928.3M - -
kubepod…f83d3bc3.slice - 0.6 638.1M - -
kubepod…fb85c98b.slice - 0.5 637.5M - -
kubepod…07c41430.slice - 0.3 630.1M - -
Widzimy tutaj poszczególne cgroupy, które między innymi odpowiadają poszczególnym kontenerom lub podom, wraz z rzeczywiście zajętą przez nie pamięcią. W zależności od rozwiązania (czy są to np. gołe dockerowe kontenery, czy kubernetes) identyfikator cgroupy może - ale nie musi - odpowiadać identyfikatorowi kontenera. W przypadku gołego dockera będzie to ten sam identyfikator. Generalnie zachęcam, żeby teraz sobie każdy lokalnie odpalił byle jaki kontener dockerowy i podejrzał go w systemd-cgtop.
Natomiast w przypadku kubernetesa to nie będzie ten sam identyfikator - przede wszystkim z tego powodu, że na podzie może chodzić więcej niż jeden kontener, a cgroupa jest tworzona dla całego poda, a nie każdego kontenera z osobna (choć to też, ale o tym za chwilę). Najprościej ten identyfikator poda, odpowiadający identyfikatorowi cgroupy, pobrać z yamla, np.:
oc get pod myapp-289-prt6s -o yaml | grep uid
(ewentualnie kubectl zamiast oc) Z tak pobranym identyfikatorem możemy w systemd-cgtop namierzyć realne zużycie pamięci poda, np:
systemd-cgtop | grep ed9802cc
I tutaj jak na dłoni będzie widać pierwszy rozjazd, pomiędzy tym, co pokazuje np. monitoring OpenShifta, a realnym zużyciem pamięci poda z punktu widzenia cgroupsów. A jako, że systemowy OOM killer patrzy dokładnie na tę samą wartość, którą zgłaszają cgroupy, to jest to pierwsze miejsce, gdzie w końcu można podejrzeć, ile tak naprawdę pamięci, z punktu widzenia systemu operacyjnego, zajmuje pod.
Skąd zatem bierze się ten rozjazd, gdzie uciekają nam te dodatkowe megabajty powodujące OOM? Stoją za tym co najmniej dwie rzeczy.
Cache dyskowy
cgroupy do zużycia pamięci liczą też cache dyskowy. Innymi słowy, jeśli proces uruchomiony w danym kontenerze wykonuje dużo zapisów/odczytów z dysku, to cgroupy będą liczyły rozmiar cache’a dyskowego tego procesu do ogólnego zużycia pamięci przez kontener. To jest szczególnie niebezpieczne w przypadku odpalania baz danych w kontenerach (pomijam tutaj całą ważną dyskusję nt. tego, czy odpalanie baz w kontenerach to dobry czy zły pomysł ;)). Może dojść do sytuacji, w której realnie zużyta pamięć przez kontener będzie kilkukrotnie wyższa niż ta, którą widać np. w docker stats. Natomiast w przypadku “zwykłych” kontenerów, gdzie mamy odpalonego, powiedzmy, spring boota, na ogół nie stanowi to większego problemu lub są to pomijalne wartości.
Dodatkowe kontenery w ramach pojedynczej cgroupy
cgroupy są w rzeczywistości strukturą drzewiastą, tj. w ramach istniejących cgroup mogą istnieć kolejne, zagnieżdżone cgroupy. Tę strukturę można obejrzeć poleceniem systemd-cgls. Szczególnie ma to znaczenie w przypadku limitu zasobów. Aktualne zużycie np. pamięci przez cgroupę jest równe sumie zużyć potomnych cgroup. Wyszukując w wyjściu systemd-cgls naszego poda, prawdopodobnie traficie na sytuację, że w ramach cgroupy odpowiadającej waszemu podowi będzie istniało jeszcze kilka innych cgroup.
Mogliście słyszeć, że Kubernetes porzucił Dockera jako runtime kontenerów (w skrócie, wciąż można używać obrazów zbudowanych dockerem na kubernetesie/openshifcie, ale do samego uruchamiania kontenerów wykorzystywany będzie już np. CRI-O). Jeśli chodzi o CRI-O (z którego korzystamy w naszym projekcie), razem z podem tworzonych jest jeszcze kilka dodatkowych kontenerów, które zajmują się przede wszystkim monitorowaniem “głównych” kontenerów należących do poda. Wszystkie te kontenery - te zdefiniowane przez nas w podzie oraz te dołożone przez CRI-O - żyją w ramach tej samej cgroupy.
Dlaczego to jest problem?
Po pierwsze, te dodatkowe kontenery też zajmą zasoby, a w szczególności pamięć! I to właśnie stąd bierze się rozjazd pomiędzy tym, co pokazuje np. monitoring OpenShifta w kontekście zużycia pamięci przez poda, a tym, co realnie pokazuje cgtop. OpenShift pokazuje zużycie pamięci jedynie “naszych” kontenerów, zupełnie pomijając kontenery CRI-O.
Jak sprawdzić, ile zasobów wciągają bonusowe kontenery CRI-O? Jako że wiemy już, że cgroupy są strukturą drzewiastą, to pora wrócić do systemd-cgtop. Domyślnie pokazuje on cgroupy do trzeciego poziomu zagnieżdżenia. Wykonując systemd-cgtop –depth=5, zobaczymy też nasze bonusowe kontenery wraz z ich konsumpcją zasobów. Empirycznie doszliśmy do tego, że na ogół zajmują one kilkadziesiąt MB (choć potrafią spuchnąć nawet do około 100MB). Naturalnie pojawia się pytanie, czy dla tych kontenerów istnieją jakieś limity? Otóż… nie. Jak w ogóle sprawdzić limit pamięci dla cgroupy? Słyszeliście o tym, że na linuksach wszystko jest plikiem? No to trzeba namierzyć odpowiedni plik. Informacje o cgroupach zapisane są w /sys/fs/cgroup/. Struktura plików odpowiada drzewiastej strukturze cgroup. Chcąc poznać limit pamięci dla cgroupy/kontenera (nieważne, czy “naszego”, czy bonusowego od CRI-O), wystarczy puścić:
cat /sys/fs/cgroup/memory/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-poded9802cc_105e_4114_8e97_0d580d361e15.slice/crio-cd168e1ea893458a8f414fe4742d9d266087b3366f4b0f8c0ce9e00810be651d.scope/memory.limit_in_bytes
gdzie poszczególne identyfikatory katalogów odpowiadają identyfikatorom cgroup na kolejnych poziomach zagnieżdżenia.
Sprawdźmy zatem, jak wygląda ten limit dla jednego z kontenerów CRI-O (w bajtach):
9223372036854771712
Trochę sporo. Innymi słowy, kontenery CRI-O nie mają ustawionego limitu pamięci!
I tu dochodzimy do sedna. Otóż limit zasobów cgroupy dla poda jest liczony jako suma limitów bezpośrednio zdefiniowanych kontenerów. Przykładowo, mam zdefiniowane dwa kontenery w podzie, każdy ma limit 256 MB pamięci. Sumarycznie limit pamięci dla poda (a więc i dla całej cgroupy) będzie wynosił 512MB. Nigdzie w tym limicie nie są uwzględnione dodatkowe kontenery CRI-O. I to właśnie z tego powodu systemowy OOM killer potrafi uwalić kontener, mimo że wcale nie doszedł do zdefiniowanego na nim limitu pamięci. Po prostu sumaryczne zużycie pamięci przez cgroupę poda (a więc pamięć zużyta przez nasz kontener/y oraz dodatkowa pamięć zjadana przez kontenery CRI-O) przekracza zdefiniowany na niej limit, który był policzony wyłącznie na bazie naszych kontenerów. W tym momencie system operacyjny odpala OOM killera, który ubije proces zabierający najwięcej pamięci. Praktycznie zawsze będzie to nasz kontener. Dla przykładu, mamy poda, którego limit pamięci to 640MB. Nasz kontener zajmuje 620MB, i w tym momencie odpala się OOM killer, ponieważ pamięć zajęta przez nasz kontener + kontenery CRI-O przekroczyła 640MB, a nasz kontener był pierwszy do odstrzału.
Reasumując, aby poznać faktyczne zużycie pamięci przez poda należy zajrzeć do sysemd-cgtop -–depth=5. W ten sposób dowiemy się nie tylko, ile w rzeczywistości zajmują nasze kontenery, ale też ile w bonusie dorzuciło od siebie CRI-O. I to tłumaczy pierwszy z rozjazdów wymienionych na samej górze - cache dyskowy oraz dodatkowe kontenery CRI-O nie są nigdzie uwzględnione i praktycznie żadne monitoringi ich nie wychwytują, a potrafią rozdmuchać pamięć kontenerów oraz poda.
Pora na drugi rozjazd, związany już wyłącznie z Javą.
Jak policzyć pamięć zużytą przez Javę?
Wszyscy słyszeli o heapie, ale potencjalnie nie wszyscy wiedzą o off-heapie. W największym uproszczeniu: heap to obszar pamięci, gdzie trafiają tworzone obiekty (te tworzone przez nas przy użyciu new, np. new ImportantService(), ale też te tworzone zakulisowo przez framework czy kontener aplikacji) i obszar ten podlega czyszczeniu przez GC. Z kolei off-heap to miejsce, gdzie trafiają rzeczy, którymi zarządza JVM, a nie my - skompilowane klasy, stack wywołań wątku i tym podobne. Off heap nie łapie się na GC. Istnieją też co prawda sposoby, aby z poziomu kodu władować nasze własne obiekty do off-heapa, ale w kontekście tego artykułu niewiele to zmienia.
Posumowany rozmiar tych dwóch obszarów powinien nam powiedzieć, ile pamięci sumarycznie zajmuje nasz proces Javy. Jak zatem to sprawdzić? Metod jest kilka, ale polecamy jedną: native memory tracking. Jest to narzędzie, które pozwala na zrzucenie dosyć niskopoziomowego raportu z pamięci HotSpota. Żeby stało się dostępne, trzeba dorzucić dodatkowy parametr podczas uruchamiania: -XX:NativeMemoryTracking=detail. Tylko uwaga - literatura twierdzi, że włączenie native memory trackingu może mieć około dziesięcioprocentowy narzut na wydajność.
Kiedy mamy już włączony NMT, pora na wykonanie zrzutu. Robi się to tak:
jcmd <PID> VM.native_memory
Przykładowy zrzut z jednej aplikacji naszego projektu wygląda tak:
Native Memory Tracking:
Total: reserved=1943037KB, committed=610501KB
- Java Heap (reserved=327680KB, committed=265820KB)
(mmap: reserved=327680KB, committed=265820KB)
- Class (reserved=1196453KB, committed=167509KB)
(classes #28683)
( instance classes #27130, array classes #1553)
(malloc=6565KB #106806)
(mmap: reserved=1189888KB, committed=160944KB)
( Metadata: )
( reserved=141312KB, committed=140720KB)
( used=135131KB)
( free=5589KB)
( waste=0KB =0.00%)
( Class space:)
( reserved=1048576KB, committed=20224KB)
( used=17072KB)
( free=3152KB)
( waste=0KB =0.00%)
- Thread (reserved=102239KB, committed=12863KB)
(thread #99)
(stack: reserved=101764KB, committed=12388KB)
(malloc=361KB #596)
(arena=114KB #196)
- Code (reserved=255775KB, committed=103615KB)
(malloc=8087KB #29935)
(mmap: reserved=247688KB, committed=95528KB)
- GC (reserved=2104KB, committed=1908KB)
(malloc=1032KB #4341)
(mmap: reserved=1072KB, committed=876KB)
- Compiler (reserved=1046KB, committed=1046KB)
(malloc=914KB #2701)
(arena=133KB #5)
- Internal (reserved=1198KB, committed=1198KB)
(malloc=1166KB #2425)
(mmap: reserved=32KB, committed=32KB)
- Other (reserved=302KB, committed=302KB)
(malloc=302KB #39)
- Symbol (reserved=28055KB, committed=28055KB)
(malloc=25969KB #368221)
(arena=2086KB #1)
- Native Memory Tracking (reserved=8867KB, committed=8867KB)
(malloc=509KB #7225)
(tracking overhead=8358KB)
- Shared class space (reserved=17148KB, committed=17148KB)
(mmap: reserved=17148KB, committed=17148KB)
- Arena Chunk (reserved=179KB, committed=179KB)
(malloc=179KB)
- Logging (reserved=4KB, committed=4KB)
(malloc=4KB #192)
- Arguments (reserved=19KB, committed=19KB)
(malloc=19KB #531)
- Module (reserved=1365KB, committed=1365KB)
(malloc=1365KB #6576)
- Synchronizer (reserved=594KB, committed=594KB)
(malloc=594KB #5027)
- Safepoint (reserved=8KB, committed=8KB)
(mmap: reserved=8KB, committed=8KB)
Najbardziej interesujące są tutaj wartości commited, pokazujące faktycznie używaną pamięć.
Co możemy z tego zrzutu wyczytać? Przede wszystkim, że z punktu widzenia samego JVMa, proces zajmuje 610501KB, czyli około 596MB pamięci.
Ciekawymi wartościami są też te dotyczące heapa oraz wszystkich pozostałych rzeczy składających się na off-heap. Warto zdawać sobie sprawę, że offheap bez problemu potrafi wciągnąć kilkaset MB i trzeba to wziąć pod uwagę w trakcie strojenia pamięci. Nie będziemy się tu jednak wgłębiać we wszystkie składowe off heapa.
Spójrzmy natomiast na wyjście ps aux dotyczące tej samej aplikacji.
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
1000630+ 1 0.8 2.0 2283920 721032 ? Ssl Nov22 12:27 Java -Dspring.config.location=classpath:/applic....
I tutaj widzimy drugi rozjazd - według NMT proces bierze niecałe 600MB RAMu, podczas gdy według systemu operacyjnego jest to około 700MB. Gdzie podziało się 100MB?
Musimy zejść na poziom niżej niż JVM, żeby pokazać, gdzie leży problem. Alokacją pamięci na linuksie domyślnie zajmuje się malloc() pochodzący z glibc (a tak na serio, to malloc() w glibc wywołuje aktualnie podlinkowaną implementację alokatora, domyślnie ptmalloc2). Do glibc należy też zwalnianie do systemu nieużywanej pamięci. Zacznijmy od tego, jak alokowana jest pamięć przez glibc - proces ten generalnie należy do skomplikowanych i ma trochę niuansów, ale tutaj go uprościmy i skupimy się na ogólnej zasadzie działania.
W aplikacji jednowątkowej sprawa jest prosta - ponieważ nie może dojść do sytuacji, w której dwa wątki naraz poproszą o pamięć, to może istnieć jeden worek pamięci, z którego pobierana jest pamięć. Sytuacja się komplikuje w aplikacjach wielowątkowych, czyli takich, z którymi przede wszystkim mamy do czynienia. Kilka wątków naraz może poprosić o pamięć, w związku z czym jeden worek z pamięcią staje się niewystarczający, ponieważ na moment alokowania pamięci trzeba założyć locka na worek, aby dwa wątki nie próbowały zaalokować tego samego obszaru pamięci. Ale kiedy pojawiają się locki, to istnieje też ryzyko czekania i zagłodzenia wątku, który czeka na pamięć, co może się mocno odbić wydajnościowo na aplikacji. Z tego też tytułu, dla aplikacji wielowątkowych tworzonych jest więcej worków, tak zwanych Aren (rzeczywistość jest tu bardziej zawiła, Areny składają się z Heapów, które z kolei są podzielone na Chunki, ale dla uproszczenia będziemy traktować Areny jako worki ciągłej pamięci). Kiedy wątek prosi o pamięć, to najpierw sprawdzana jest ostatnio użyta przez ten wątek Arena, a jeśli ona okaże się być zablokowana przez inny wątek, to odnajdywana jest pierwsza niezablokowana Arena, i z niej alokowana jest pamięć. Jeśli natomiast nie uda się znaleźć niezablokowanej Areny, to tworzona jest nowa. Dzięki temu, że istnieje więcej niż jeden worek (aka Arena), ryzyko czekania na locka jest zdecydowanie niższe, co pozytywnie wpływa na wydajność alokowania pamięci, a tym samym wydajność aplikacji ogólnie.
Póki co brzmi to rozsądnie.
Problem pojawia się w momencie zwalniania pamięci. W dużym uproszczeniu, areny działają trochę jak stos - zalokowane kawałki pamięci umieszczane są na górze tego stosu. Wyobraźmy sobie więc, że trzy wątki alokują trzy kawałki pamięci - nazwijmy je A, B i C - w tej właśnie kolejności. Najpierw A, potem B, na końcu C. Na górze stosu będzie leżało C. Dwa pierwsze wątki zwalniają pamięć, a więc kawałki A oraz B. Czy pamięć zajęta przez kawałki A oraz B zostaje oddana do systemu operacyjnego? Nie. Pomimo tego, że aplikacja przestała już używać tej pamięci, to z punktu widzenia systemu ona wciąż należy do aplikacji. Dzieje się tak, ponieważ domyślna implementacja glibc oddaje do systemu operacyjnego pamięć wyłącznie z samej góry stosu! Innymi słowy, kawałki pamięci A oraz B zostaną zwrócone systemowi operacyjnemu dopiero w momencie, kiedy aplikacja zwolni kawałek C - dopiero wtedy na górze stosu znajdzie się nieużywana pamięć, a glibc odda całą nieużywaną pamięć z góry stosu do systemu. Taki model zarządzania pamięcią powoduje, że z łatwością dochodzi do sytuacji, kiedy w głębi stosu znajduje się sporo nieużywanek pamięci, której nie da się oddać do systemu operacyjnego, ponieważ jakiś wątek aplikacji wciąż używa pamięci znajdującej się “wyżej” na stosie. Co prawda glibc podejmuje próby defragmentacji Aren, i w pewien sposób mityguje to problem, to jednak go nie rozwiązuje - przeciętnie obciążona aplikacja zawsze będzie chomikowała pewną ilość pamięci, z której w żaden sposób już nie korzysta. W skrócie, ten algorytm jest nastawiony na poprawę wydajności działania aplikacji, kosztem zwiększonego zużycia pamięci.
I to właśnie tutaj uciekło nam 100MB pamięci z powyższego przykładu - jest to pamięć nieużywana już przez aplikację, ale wciąż niezwrócona do systemu.
Jak można temu zaradzić?
Pierwsza opcja to w ogóle tego nie ruszać - tego rodzaju nadwyżka w wielu aplikacjach może być po prostu akceptowalna. Natomiast im większa aplikacja, im więcej wątków, tym ten rozjazd będzie większy. W trakcie prowadzenia tego śledztwa widzieliśmy w internecie przypadki, kiedy ta niezwrócona do systemu pamięć szła w gigabajty.
Druga opcja to wymiana domyślnego alokatora pamięci. Trochę tego jest do wyboru, np. jemalloc albo tcmalloc. Każdy alokator ma własne algorytmy związane z alokowaniem i zwalnianiem pamięci, i oczywiście każdy twierdzi, że ich algorytmy są najlepsze. ;) Udało nam się przetestować aplikację z jemalloc i wyniki były obiecujące - rozmiar niezwróconej pamięci do systemu spadł mniej więcej o połowę, do około 50MB. Natomiast wymiana domyślnych alokatorów może być nieco karkołomną opcją, albo wręcz nie wszędzie możliwą.
Trzecią opcją jest zatem strojenie domyślnego malloca. Najważniejszą opcją, która pozwala na sterowanie zachowaniem malloca pod kątem zwalniania nieużywanej pamięci, jest maksymalna liczba Aren dostępnych dla procesu. Domyślnie maksymalna liczba Aren wynosi 8 * liczba core’ów. Czyli dla 8 core’ów procesy będą miały do dyspozycji 64 Areny - sporo. Im więcej aren, tym większa szansa na chomikowanie pamięci. Z drugiej strony, im mniej aren tym większa szansa na zagłodzenie wątku czekającego na pamięć, co odbije się na ogólnej wydajności aplikacji. Ustawiając zmienną środowiskową MALLOC_ARENA_MAX, możemy kontrolować maksymalną liczbę aren. W przypadku Javy, wiele artykułów w internecie poleca ścięcie tego parametru do 2 lub 4. Wykonaliśmy próbę, ścinając tę wartość do 2. Aplikacja, która wcześniej chomikowała ponad 100MB pamięci, zaczęła chomikować jedynie kilkanaście MB. Natomiast nie istnieje tutaj ścisła matematyka - ograniczenie liczby aren zmniejsza rozmiar chomikowanej pamięci, jednak nie da się uniwersalnie przeliczyć tego na konkretnie zaoszczędzone megabajty - będzie to indywidualne dla każdej aplikacji. Manewrowanie tym parametrem powinno też zakończyć się testami wydajnościowymi, które potwierdzą, że rozwiązując problem pamięci, nie wywołaliśmy problemu z wydajnością.
Mimo tego ewidentnego tradeoffu, jest to dobra informacja - dzięki temu udało się nam finalnie doliczyć całej pamięci oraz wyjaśnić drugi rozjazd z samego początku tego artykułu. A to z kolei pozwala świadomie dobierać takie parametry jak maksymalny rozmiar heapa czy limit pamięci dla kontenera.
Rozkład zużycia pamięci
Poniższy diagram pokazuje, co faktycznie składa się na zużycie pamięci dla przeciętnej javowej aplikacji odpalonej na kubernetesie. Schodząc wgłąb diagramu można też wyczytać, jak wygląda rozkład pamięci w przypadku uruchomienia aplikacji javowej na “zwykłych” kontenerach (ramka “Application container”) oraz w przypadku uruchomienia aplikacji zupełnie z pominięciem kontenerów (ramka “JVM”).
Elementy narysowane przerywaną linią są elementami raczej logicznymi i same w sobie nie konsumują ramu (ewentualnie ich narzut jest pomijalny). Elementy z ciągłym obramowaniem konsumują fizyczną pamięć i należy ją wziąć pod uwagę podczas strojenia pamięci.
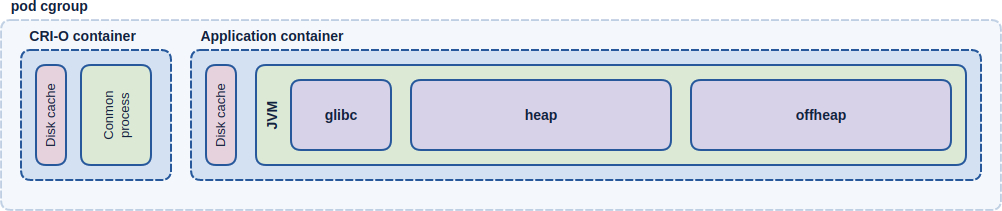
Jak dobrać parametry pamięci?
W świecie kontenerów sprowadza się to w praktyce do wyboru dwóch wartości - limitu pamięci dla kontenera i maksymalnego rozmiaru heapa. I to właśnie sumaryczny rozmiar heapa oraz offheapa jest tutaj najważniejszą metryką, która powinna determinować limit kontenera, nigdy na odwrót.
Oczywiście rozmiar heapa i offheapa pozostaje kwestią specyficzną dla każdej aplikacji. Niewielkie aplikacje spring bootowe, które nie wykorzystują za bardzo zewnętrznych libów (poza spring bootem oczywiście ;)), np. będące jedynie prostą przelotką do innych serwisów, spokojnie poradzą sobie z heapem ściętym do 32MB. Natomiast nawet tak proste aplikacje na dzień dobry mogą wciągnąć około 100MB off heapa, głównie na klasy i wątki. Im większa aplikacja, im więcej zależności, tym bardziej obie te wartości będą rosnąć. W przypadku spring bootowych aplikacji naszego projektu standardem jest off heap wahający się pomiędzy 300 a 400MB. Trzeba też brać poprawkę na to, że rozmiar offheapa nie będzie stały, a w szczególności może rosnąć z czasem, wraz z wątkami czy kompilowaniem do kodu maszynowego kolejnych partii bytecode’u. Wydaje się, że ciężko poznać optymalny rozmiar heapa oraz docelowy rozmiar offheapa inaczej niż empirycznie. Można się oczywiście podpierać doświadczeniem, ale ostatecznie każda aplikacja jest inna, a wciągnięcie choćby jednej dodatkowej zależności może w skrajnym przypadku kompletnie zmienić obraz tych wartości.
Wiedząc, ile pamięci potrzebujemy na heapa oraz offheapa, pozostała matematyka sprowadza się do podliczenia narzutów. Jeśli mówimy o prostych aplikacjach bezstanowych lub kiedy aplikacja nie chodzi w kontenerze, możemy właściwie zignorować kwestię cache’a dyskowego. Pozostaje zatem kwestia pamięci kiszonej przez glibc oraz w przypadku kubernetesa, kontenerów CRI-O. W przypadku CRI-O wydaje się, że warto zostawić co najmniej kilkadziesiąt MB zapasu, w porywach do 100. W przypadku pamięci kiszonej przez glibc, dla aplikacji, które zużywają średnio w okolicy 300MB heapa, konfiguracyjnie (zmienną środowiskową MALLOC_ARENA_MAX) da się zejść znacznie poniżej 100MB kiszonej pamięci, do około kilkunastu-kilkudziesięciu MB. Jednak dla większych aplikacji, utylizujących więcej pamięci, ta zakiszona pamięć będzie odpowiednio większa. Po doliczeniu narzutów otrzymamy limit pamięci dla kontenera.
Można się więc pokusić o taki wzór:
limit kontenera = heap + offheap + glibc + disk cache (dla kontenerów) + crio (dla kubernetesa)
Sporą karierę ostatnimi czasy zrobiło procentowe ustawianie rozmiaru heapa, w zależności od rozmiaru pamięci dostępnej dla kontenera, przy pomocy flagi XX:MaxRAMPercentage. Sami zresztą użyliśmy jej w naszym projekcie. Motywacja jest oczywista - znacznie wygodniej zarządzać jedną wartością niż dwiema. Uzbrojeni jednak w powyższą wiedzę twierdzimy, że w większości przypadków jest zbyt duże uproszczenie, ponieważ zmieniając limit kontenera, wpływamy w ten sposób na właściwie wszystkie obszary pamięci, które warto wziąć pod uwagę - heap, offheap, glibc, crio-o. Co więcej, chcąc zwiększyć dostępną pamięć, np. na “wyciek” glibc, musimy też zmienić procentowy udział heapa w pamięci kontenera, żeby przy okazji nie rozszerzyć heapa, co w praktyce i tak oznacza przeliczanie od nowa procentowych wartości heapa. Przy okazji uniezależniając rozmiar heapa od rozmiaru kontenera, prościej analizuje się problemy związane generalnie z OOM - czy to systemowym, czy javowym, dzięki temu, że wszystkie obszary pamięci naraz nie zmieniają rozmiaru. Ostatecznie więc znalezienie uniwersalnej wartości XX:MaxRAMPercentage wydaje się na tyle trudne, że przychylamy się do staroświeckiego Xmx. No chyba, że mamy tyle RAMu, że każdy kontener może mieć sporą górkę pamięci - ale wtedy cały ten artykuł mija się z celem. ;)
Podobne wpisy





