Migracja aplikacji do chmury Google Cloud Platform w praktyce

W poprzednim wpisie pt. “Migracja do chmury - czyli od czego zacząć?”
przedstawiłem etapy procesu migracji aplikacji do chmury, a także opisałem poszczególne strategie migracji.
W tym wpisie chciałbym przedstawić migrację do chmury Google Cloud Platform w praktyce. Na warsztat wezmę działającą aplikację demo, która w żaden sposób nie jest przystosowana do uruchomienia w chmurze, przedstawię architekturę docelową przy wykorzystaniu każdej z opisywanych wcześniej strategii oraz zaimplementuję jedną z nich.
Słowem wstępu
Kody źródłowe aplikacji demo są dostępne na GitHubie:
Dla przypomnienia, 4 etapy procesu migracji do chmury, opisane w poprzednim wpisie:

Szacowanie
Na etapie szacowania powinniśmy dokonać analizy istniejącego systemu/infrastruktury. Na potrzeby wpisu przygotowałem aplikację demo, która nie jest uruchomiona produkcyjnie, stąd trudno byłoby oszacować wykorzystywane zasoby. Nie chcąc wróżyć z fusów, na etapie szacowania przedstawię jedynie architekturę aplikacji oraz jej działanie.
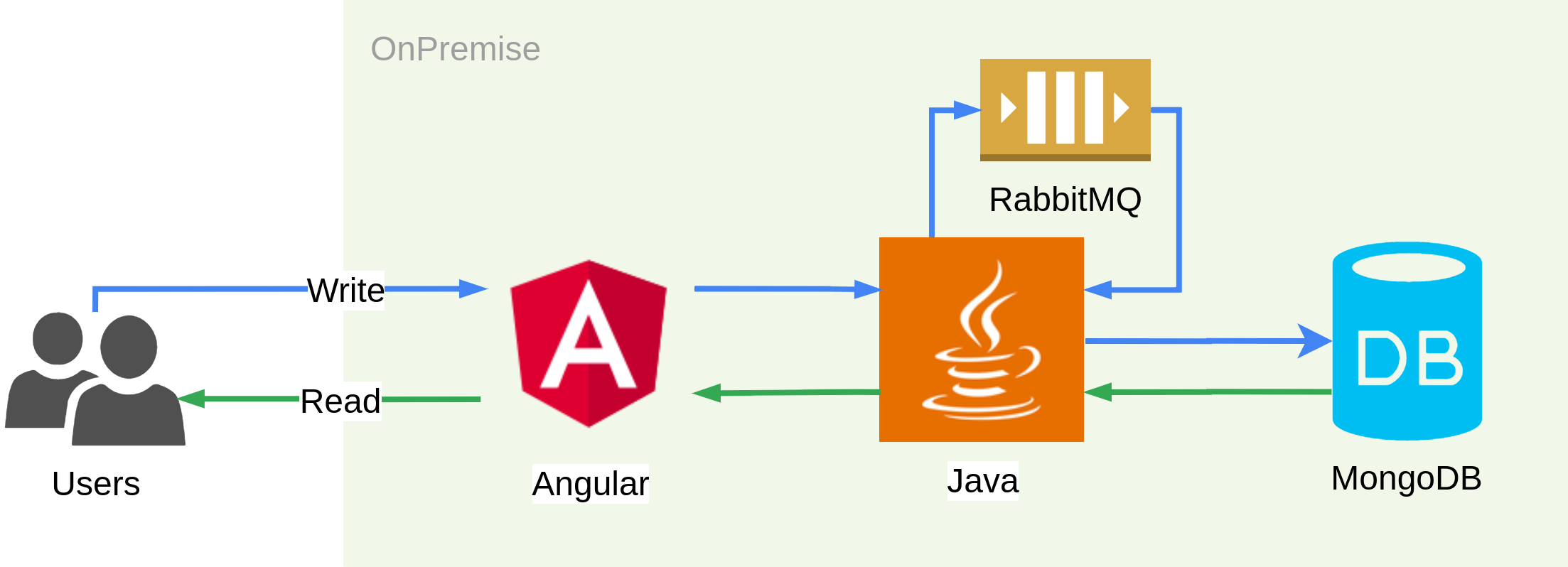
Zadaniem aplikacji jest przyjęcie danych od użytkownika za pomocą formularza, przetworzenie ich, utrwalenie w bazie danych oraz umożliwienie użytkownikowi odczytu tych danych. System składa się z kilku elementów:
- aplikacji frontendowej - napisanej w Angularze (TypeScript), której zadaniem jest przyjmowanie danych od użytkownika oraz ich prezentacja;
- aplikacji backendowej - napisanej w Javie (Spring Boot), której zadaniem jest przyjęcie danych z aplikacji frontendowej i przesłanie ich do kolejki oraz odczytanie z bazy danych;
- kolejki - opartej o RabbitMQ, której celem jest optymalizacja zapisu;
- bazy danych - w postaci nierelacyjnej bazy MongoDB, która przechowuje przesłane dane.
Wykorzystałem kolejkę, aby dane przesyłane przez użytkowników były od razu przyjmowane, a użytkownik otrzymywał potwierdzenie przyjęcia ich przez system. Przetwarzanie danych może być w teorii czasochłonnym procesem, dlatego dzięki wykorzystaniu kolejki, użytkownik nie musi czekać na przetworzenie danych, aby uzyskać odpowiedź.
Dane pobierane są z kolejki przez aplikację backendową, następnie przetwarzane (w przykładowej aplikacji pominąłem element przetwarzania - możemy wyobrazić sobie tutaj jakiś złożony i czasochłonny proces) i utrwalane w bazie danych. Odczyt danych z bazy wykonywany jest również przez aplikację backendową, za pośrednictwem sterownika bazy danych, a następnie dane te są przesyłane do aplikacji frontendowej w formacie JSON.
Infrastruktura systemu źródłowego może być oparta o maszyny fizyczne, wirtualne, kontenery (Docker, Kubernetes, OpenShift) lub o dowolne inne rozwiązanie. Na potrzeby wpisu wykorzystałem Docker Compose, co ułatwia uruchomienie całej aplikacji lokalnie.
Zakładając znajomość podstawowych usług oferowanych przez Google Cloud Platform, przejdźmy do kolejnego etapu migracji.
Planowanie
Planując architekturę systemu w chmurze, pierwszą czynnością, jaką należy wykonać, jest wybór strategii migracji. Od niej zależeć będzie to, jak będzie wyglądał system docelowy oraz jakie narzędzia i usługi zostaną wykorzystane.
Wybierając strategię migracji, przyjąłem kilka założeń:
- nie ma żadnych ograniczeń budżetowych oraz czasowych na wykonanie migracji;
- system musi być gotowy obsłużyć każdy ruch użytkowników (automatyczne skalowanie);
- utrzymanie infrastruktury powinno wymagać jak najmniejszego udziału człowieka (automatyzacja);
- koszt utrzymania powinien być możliwie jak najniższy, szczególnie w przypadku braku ruchu użytkowników.
Zanim podejmiemy ostateczną decyzją, zastanówmy się, jaka będzie architektura systemu docelowego, w zależności od wykorzystanej strategii. Zalety oraz wady każdej ze strategii opisałem już w poprzednim wpisie, a podane tutaj rozwiązania mają jedynie charakter przykładowy. To jak zaplanujemy architekturę docelową, zależy od wielu czynników, a strategie mają jedynie pomóc nam w podjęciu decyzji.
Strategia “Lift and shift”
Migracja strategią “Lift and shift” polega na wykorzystaniu maszyn wirtualnych (Compute Engine) na których uruchomione zostaną poszczególne elementy systemu. Wyjątek stanowi aplikacja frontendowa, której pliki statyczne będące wynikiem zbudowania aplikacji, umieszczone zostaną w buckecie (Cloud Storage).
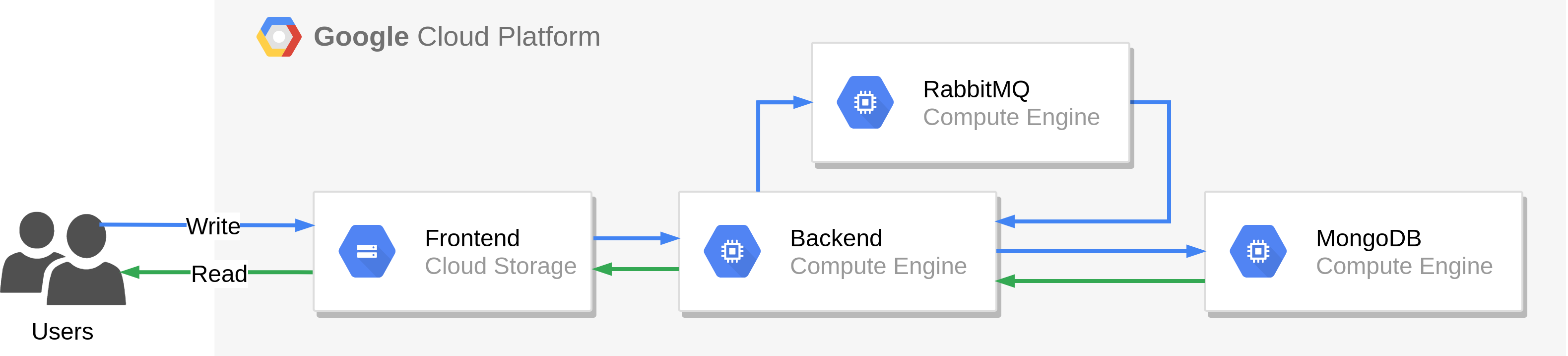
Plusy: Proces migracji w tym wypadku jest nieskomplikowany, wymaga od nas minimalnej znajomości platformy i zajmie stosunkowo niewiele czasu. W przypadku, gdy infrastruktura źródłowa oparta jest o VMware vSphere, chmurę AWS lub Azure, możemy zautomatyzować cały proces, wykorzystując do tego celu narzędzie Migrate for Compute Engine.
Minusy: Nie wykorzystujemy praktycznie wcale potencjału chmury, odpowiedzialność za system stoi w większości po naszej stronie, a kolejka oraz baza danych nie jest skalowana automatycznie. Musimy również z góry określić typ maszyn Compute Engine oraz skonfigurować ich skalowanie (managed instance groups).
Strategia “Improve and move”
Migracja strategią “Improve and move” polega na zastąpieniu bazy danych oraz kolejki usługami SaaS. Są to elementy, które najłatwiej jest zastąpić, przy jak najmniejszym nakładzie pracy. Bazę danych zastępuje w tym przypadku odpowiadająca jej usługa Cloud Firestore, a kolejkę usługa Cloud Pub/Sub.
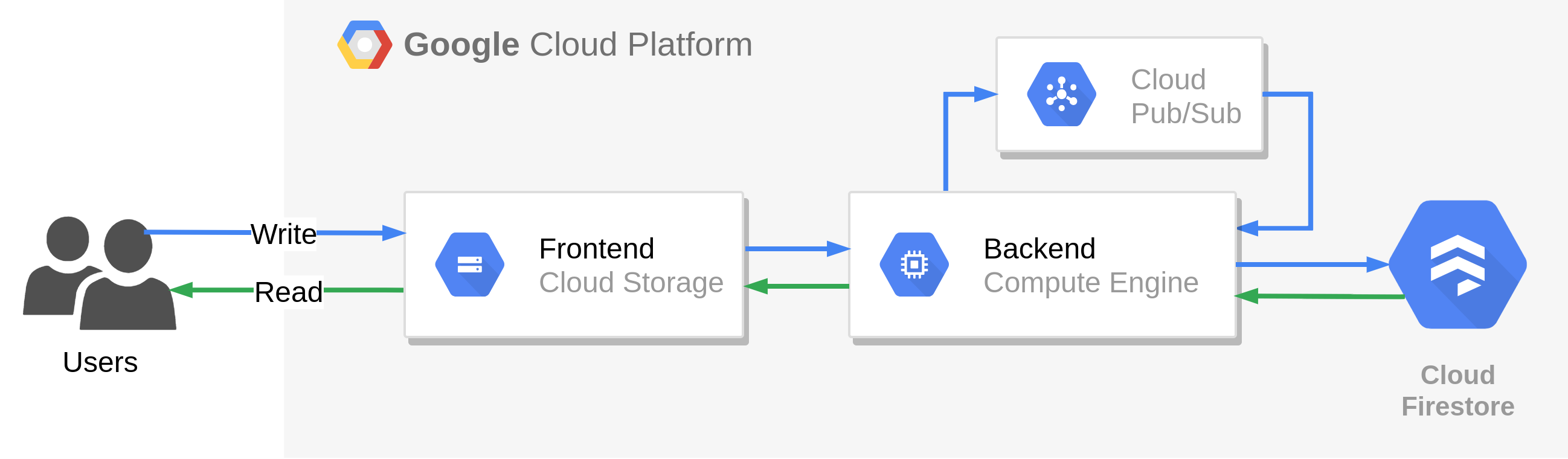
Plusy: Eliminujemy problem braku automatycznego skalowania bazy danych i kolejki, przesuwając również odpowiedzialność za te elementy na usługodawcę.
Minusy: Wymagana jest znajomość wykorzystywanych usług SaaS, a także ingerencja w kody źródłowe aplikacji (warstwa komunikacji z bazą/kolejką). Backend nadal oparty jest o maszyny wirtualne, ze wszelkimi tego konsekwencjami.
Strategia “Rip and replace”
Migracja strategią “Rip and replace” polega na całkowitym wykorzystaniu natywnych rozwiązań chmury. Oprócz usług SaaS, wykorzystujemy dodatkowo Cloud Functions, dzięki czemu eliminujemy minusy poprzednich dwóch strategii.
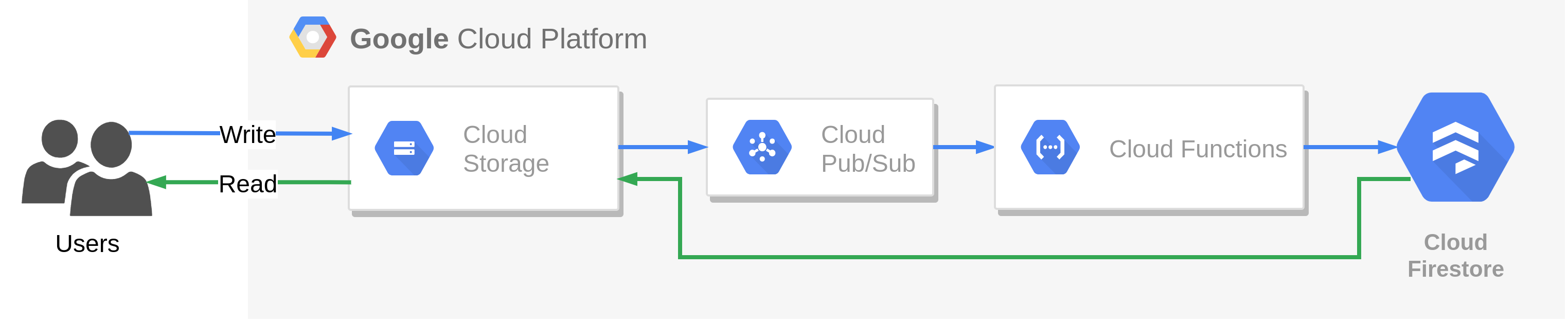
Plusy: Optymalizujemy architekturę systemu, przesuwając granicę odpowiedzialności prawie całkowicie na stronę usługodawcy. Cloud Functions umożliwia wywoływanie funkcji po pojawieniu się wiadomości w usłudze Cloud Pub/Sub, dzięki czemu aplikacja frontendowa może zapisywać dane przyjęte od użytkownika bezpośrednio do kolejki, bez pośrednictwa aplikacji backendowej. Przepisując aplikację backendową na funkcję można zrezygnować również z jej pośrednictwa w odczycie danych z Cloud Firestore, ponieważ usługa ta udostępnia REST API, które umożliwia odczyt danych bezpośrednio przez aplikację frontendową. Dzięki automatycznemu skalowaniu (również do zera), optymalizujemy koszty utrzymania infrastruktury, które w przypadku zerowego ruchu użytkowników, można ograniczyć całkowicie do zera (w ramach GCP Free Tier).
Minusy: Wykorzystanie natywnych rozwiązań wymaga od nas bardzo dobrej znajomości platformy, usług oraz komunikacji między nimi. Jak okaże się za chwilę, pojawiają się również nowe problemy, jak na przykład ograniczenia API usług, czy problem zimnego startu funkcji. Migracja z wykorzystaniem strategii “Rip and replace” jest również najbardziej czasochłonna, ponieważ wymaga całkowitego przepisania części systemu. Wykorzystując natywne rozwiązania platformy uzależniamy się również od usługodawcy (vendor lock-in).
Architektura systemu docelowego
Ponieważ złożoność systemu źródłowego jest niewielka i chciałbym w tym wpisie pokazać jak najwięcej, przeprowadzimy migrację z wykorzystaniem strategii “Rip and replace”. Architektura systemu docelowego będzie więc wyglądać następująco:
- aplikacja frontendowa (pliki statyczne) zostanie umieszczona w Cloud Storage i udostępniona publicznie, wykorzystując HTTP/S Load Balancer. Alternatywą jest wykorzystanie platformy Firebase, w praktyce jednak, Firebase przechowuje pliki statyczne również w Cloud Storage, przykrywając wszystko własnym interfejsem graficznym;
- aplikacja backendowa, z racji niskiej złożoności, zostanie przepisana całkowicie na Cloud Functions. Utracona zostanie walidacja danych wejściowych, ale dzięki temu użytkownik będzie mógł przesyłać dane do Cloud Pub/Sub bezpośrednio z aplikacji frontendowej. Dane te mogą być walidowane przez funkcję, która pobiera je z Cloud Pub/Sub, przetwarza i utrwala w Firestore. Gdyby walidacja była wymagana przed wrzuceniem danych do Cloud Pub/Sub, to pomiędzy aplikacją frontendową a Cloud Pub/Sub musiałaby znaleźć się dodatkowa funkcja, której zadaniem byłoby przyjęcie lub odrzucenie danych oraz przesłanie ich do Cloud Pub/Sub;
- kolejka RabbitMQ zostanie zastąpiona całkowicie przez usługę Cloud Pub/Sub;
- baza danych MongoDB zostanie zastąpiona całkowicie przez odpowiadającą jej usługę Cloud Firestore, która jest bazą nierelacyjną, przechowującą dane w formie dokumentów JSON.
W systemie docelowym, jako że jest on w infrastrukturze chmury (czyli dostępny publicznie przez Internet), w celu zabezpieczenia przed nieupoważnionym dostępem, musimy zaimplementować mechanizm uwierzytelniania (chyba, że nie obawiamy się rachunków od Google). W tym celu wykorzystamy Google Sign-In. Aby to zrobić, musimy w APIs & Services stworzyć credential OAuth client ID i skonfigurować w Cloud IAM przykładowego użytkownika, który posiadać będzie uprawnienia do korzystania z aplikacji (może to być nasze główne konto, które posiada rolę właściciela).
Dzięki wykorzystaniu Cloud Functions, zoptymalizujemy koszt utrzymania systemu. Funkcje generują koszt wyłącznie wtedy, kiedy działają - za liczbę wywołań oraz czas ich wykonywania. W przypadku bardzo niskiego ruchu (łapiącego się w darmowe limity wywołań funkcji), lub jego braku, opłaty mogą zostać zminimalizowane do zera. Funkcje skalują się automatycznie, dlatego cała odpowiedzialność za obsłużenie ruchu użytkowników i zapewnienie dostępności systemu leży po stronie usługodawcy.
Usługa Cloud Pub/Sub działa na zasadzie kolejki, więc idealnie zastąpi RabbitMQ. Zazwyczaj Cloud Pub/Sub dostarcza każdą wiadomość jeden raz oraz w takiej kolejności, w jakiej została opublikowana. Google w dokumentacji usługi informuje, że mogą zdarzyć się sytuacje, w których wiadomość zostanie dostarczona poza kolejnością lub więcej niż jeden raz. Wiedząc o tym, należy zaimplementować odbiorcę wiadomości w sposób idempotentny, czyli odporny na wielokrotne dostarczenie tej samej wiadomości. W przypadku aplikacji demo nie stanowi to problemu, ponieważ każda wiadomość posiadać będzie unikalny identyfikator, a wielokrotne zapisanie tej samej wiadomości do Cloud Firestore spowoduje jej nadpisanie. W systemie źródłowym, wykorzystanie RabbitMQ również wymagało idempotentnego odbiorcy wiadomości.
Pojawienie się wiadomości w Cloud Pub/Sub triggerować będzie wywołanie funkcji odpowiedzialnej za przetworzenie wiadomości i utrwalenie jej w Cloud Firestore. Zrezygnujemy z funkcji pomiędzy aplikacją frontendową a Cloud Pub/Sub, ponieważ zakładamy, że nie ma potrzeby walidacji danych przed wysłaniem ich do Cloud Pub/Sub. W aplikacji źródłowej taka walidacja była wykonywana przez aplikację backendową, zanim wiadomość została wysłana do kolejki RabbitMQ. Dzięki temu, podczas migracji zoptymalizujemy system, upraszczając jego architekturę. Oczywiście taka optymalizacja byłaby możliwa również w systemie źródłowym, ponieważ RabbitMQ umożliwia dostarczanie wiadomości poprzez REST API, wykorzystując w tym celu dodatkową wtyczkę.
Odpowiednikiem bazy MongoDB jest usługa Cloud Firestore. Umożliwia ona zapis i odczyt za pomocą REST API, dzięki czemu odczyt może być wykonywany w samej aplikacji frontendowej, bez udziału aplikacji backendowej (nie jest potrzebny sterownik do bazy danych). To upraszcza jeszcze bardziej architekturę systemu docelowego.
Wdrażanie
Wszystkie elementy zostaną wdrożone ręcznie, za pomocą Cloud CLI (które umożliwia wykonywanie poleceń GCP w lokalnym terminalu) oraz Cloud Console.
Aplikacja frontendowa
Migracja aplikacji frontendowej wymaga drobnych zmian. Po pierwsze, musimy zaimplementować uwierzytelnianie, wykorzystujące Google Sign-In. W tym celu, w pliku environment.ts musimy skonfigurować Client ID, który wygenerowaliśmy wcześniej. Po drugie, główne zmiany zajdą w serwisie odpowiedzialnym za zapis oraz odczyt danych (w systemie źródłowym, wszystko odbywa się przez aplikację backendową). Przykładowy zapis oraz odczyt w aplikacji frontendowej (w systemie źródłowym), wygląda następująco:
upsertData(data: Data): Observable<Object> {
console.log(`Sending ${JSON.stringify(data)}`);
return this.http.post(`${environment.apiUrl}/api`, data);
}
findByUuid(uuid: string): Observable<Object> {
console.log(`Find by uuid: ${uuid}`);
return this.http.get(`${environment.apiUrl}/api/${uuid}`);
}
Funkcja upsertdata przesyła dane do aplikacji backendowej, za pomocą żądania HTTP POST. Odczyt danych za pośrednictwem aplikacji backendowej wykonywany jest przez funkcję findByUuid, za pomocą żądania HTTP GET.
W systemie docelowym, zapis wykonywany jest bezpośrednio z aplikacji frontendowej do usługi Cloud Pub/Sub, a odczyt bezpośrednio z Cloud Firestore:
upsertData(data: Data): Observable<Object> {
console.log(`Sending ${JSON.stringify(data)}`);
let dataToSend = Object.assign({}, data);
dataToSend.uuid = uuid.v4();
return this.http.post(environment.pubSubUrl, {
"messages": [
{
"data": btoa(JSON.stringify(dataToSend))
}
]
}).pipe(map(response => ({
messageId: response['messageIds'][0],
uuid: dataToSend.uuid
})));
}
findByUuid(documentUuid: string): Observable<Data> {
console.log(`Find by uuid: ${documentUuid}`);
return this.http.get<any>(`${environment.firestoreUrl}/${documentUuid}`)
.pipe(map(object =>
({
uuid: object.fields.uuid.stringValue,
manufacturer: object.fields.manufacturer.stringValue,
model: object.fields.model.stringValue
})));
}
Funkcja upsertData przygotowuje obiekt do wysłania do usługi Cloud Pub/Sub, dodając do niego unikalny identyfikator UUID i kodując wiadomość do formatu Base64. Odpowiedź z usługi jest mapowana na odpowiedni model.
Funkcja findByUuid pobiera dane z usługi Cloud Firestore i mapuje je na odpowiedni model.
Główna różnica w zapisie, to nadanie unikalnego identyfikatora UUID, który wcześniej był nadawany przez aplikację backendową, przygotowanie wiadomości Cloud Pub/Sub oraz przemapowanie odpowiedzi.
Odczyt różni się natomiast tym, że z odpowiedzi usługi Cloud Firestore, wyciągane są jedynie potrzebne dane (oryginalna odpowiedź zawiera wiele dodatkowych informacji, takich jak znaczniki czasowe zapisu/aktualizacji itp., które nie są prezentowane użytkownikowi).
Cała logika odpowiedzialna za przemapowanie żądania/odpowiedzi, która do tej pory była zaimplementowana w aplikacji backendowej, musi zostać zaimplementowana po stronie aplikacji frontendowej. Dzięki temu architektura znacząco się upraszcza.
Aby uruchomić aplikację w chmurze, potrzebny jest bucket w Cloud Storage oraz usługa HTTP(S) Load Balancer. Po zbudowaniu aplikacji frontendowej, wygenerowane pliki statyczne (JS oraz CSS) umieszczamy w buckecie.
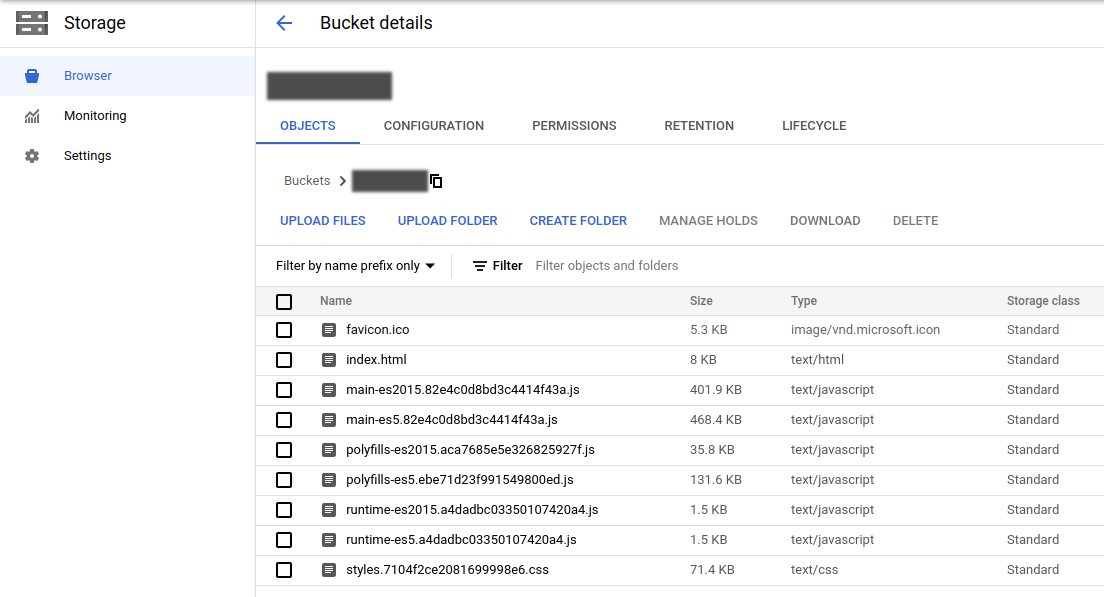
Musimy pamiętać jeszcze o skonfigurowaniu go w taki sposób, aby pliki były dostępne publicznie. W tym celu, należy dodać w konfiguracji bucketu użytkownika o nazwie allUsers oraz nadać mu uprawnienie Storage Object Viewer.
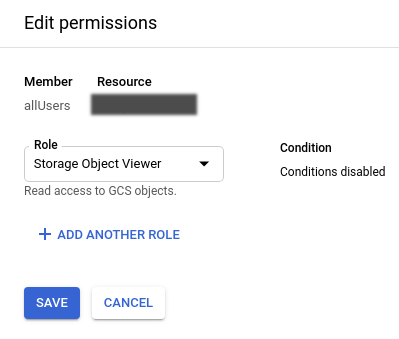
Po umieszczeniu plików w Cloud Storage, będą one dostępne publicznie, np. plik index.html będzie dostępny pod adresem:
https://storage.googleapis.com/BUCKET_NAME/index.html
Aplikacja nie będzie jednak działać, gdyż do jej uruchomienia potrzebna będzie jeszcze usługa Cloud Load Balancing. Bez niej, po wejściu na podany wyżej adres, zostanie wyświetlona jedynie zawartość pliku index.html, a zawarte w nim skrypty JavaScript nie zostaną w żaden sposób zinterpretowane przez przeglądarkę, w efekcie czego wyświetli się jedynie pusta strona.
Podczas konfiguracji usługi Cloud Load Balancing, jako backend musimy skonfigurować bucket zawierający pliki statyczne oraz musimy nadać statyczny adres IP. Dodatkowo możemy wykorzystać usługę Cloud CDN. Więcej na ten temat znajdziemy w dokumentacji: Setting up a load balancer with backend buckets.
Dzięki temu, aplikacja będzie działać poprawnie pod adresem IP:
http://LOAD_BALANCER_IP/index.html
Do pełni szczęścia potrzebna jest jeszcze domena, która musi zostać skonfigurowana w usłudze Cloud Load Balancing. Google Sign-In, które zostało wykorzystane do uwierzytelniania, wymaga skonfigurowania adresu Origin dla wygenerowanego Client ID, czyli adresu, pod którym będzie dostępna aplikacja internetowa. Nie może to być adres IP, ponieważ mimo możliwości wpisania w tym miejscu adresu IP, podczas próby zalogowania się otrzymamy błąd redirect_uri_mismatch:
The JavaScript origin in the request, does not match the ones authorized for the OAuth client,
czyli taki sam, jak w przypadku braku adresu Origin.
Po skonfigurowaniu domeny, możemy skonfigurować odpowiednio Client ID:
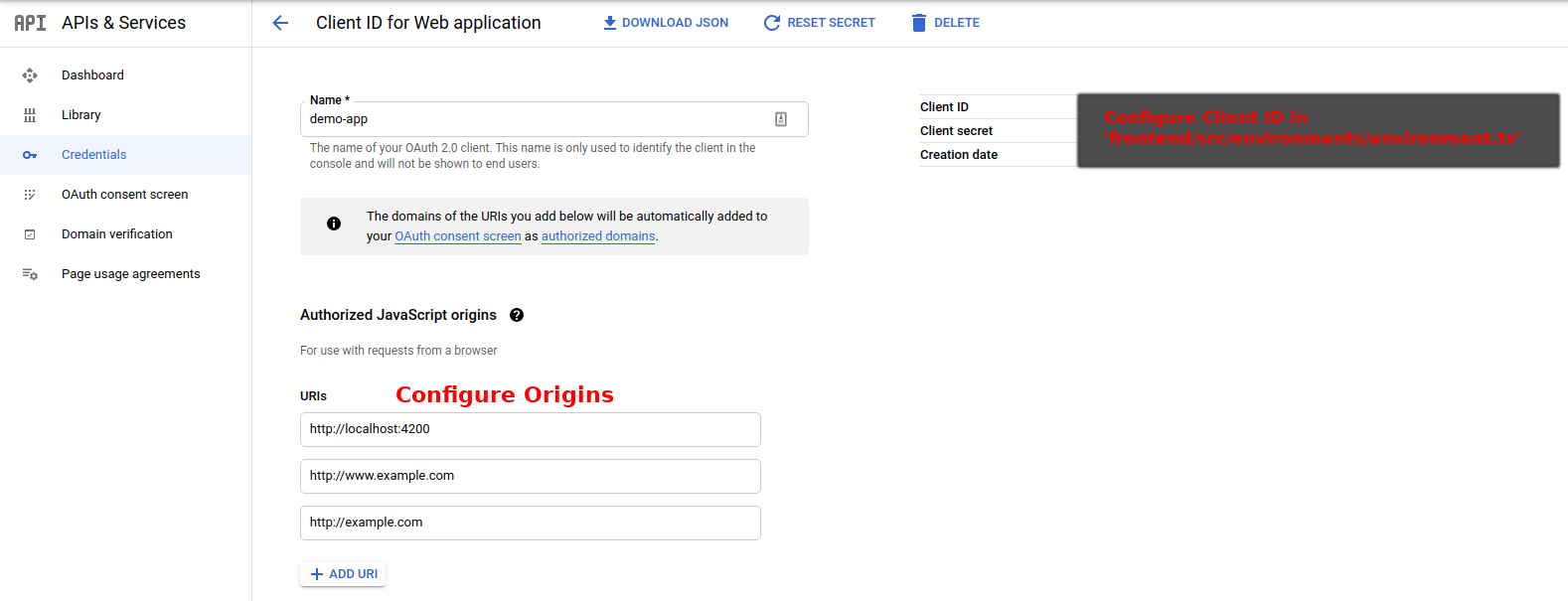
Kolejka
W konsoli usługi Cloud Pub/Sub musimy skonfigurować nowy topic, którego identyfikator zostanie przekazany do aplikacji frontendowej, ponieważ adres na który są wysyłane wiadomości (environment.pubSubUrl) musi wskazywać, na jaki topic wiadomość jest wysyłana (a także musi zawierać id projektu):
https://pubsub.googleapis.com/v1/projects/PROJECT_ID/topics/TOPIC_NAME:publish
Konfiguracja kolejki w zasadzie na tym się kończy, ponieważ usługa Cloud Pub/Sub nie wymaga żadnych dodatkowych konfiguracji.
Aplikacja backendowa
Aplikacja backendowa, która odpowiedzialna jest za komunikację aplikacji frontendowej z kolejką RabbitMQ oraz bazą danych MongoDB, zostanie zastąpiona krótką funkcją.
Zapis danych do usługi Cloud Pub/Sub oraz odczyt z Cloud Firestore odbywa się bezpośrednio przez REST API, dlatego jedyną odpowiedzialnością funkcji jest pobieranie danych pojawiających się w Cloud Pub/Sub, przetwarzanie ich (jak już wspomniałem, pominąłem przetwarzanie) oraz utrwalenie w Cloud Firestore.
Funkcję napiszemy w jednym z dostępnych w Cloud Functions języków, a dokładnie w JavaScript, który wykorzystuje środowisko uruchomieniowe Node.js (w wersji 10).
Aplikacja źródłowa składa się z kilku klas Javy, z których najważniejszą jest klasa DataService:
public class DataService {
private final RabbitService rabbitService;
private final MongoService mongoService;
Data saveInQueue(Data data) {
log.info("> saveInQueue [data={}]", data);
data.setId(UUID.randomUUID().toString());
data.setTimestamp(LocalDateTime.now());
rabbitService.send(data);
log.info("< saveInQueue [data={}]", data);
return data;
}
Data findByUuid(String uuid) {
log.info("> findByUuid [uuid={}]", uuid);
Data data = mongoService.findByUuid(uuid);
log.info("< findByUuid [data={}]", data);
return data;
}
List<Data> findAll() {
log.info("> findAll");
List<Data> data = mongoService.findAll();
log.info("< findAll [data={}]", data);
return data;
}
void deleteAll() {
log.info("> deleteAll");
mongoService.deleteAll();
log.info("< deleteAll");
}
}
Składa się ona z metody saveInQueue, która zapisuje dane przesłane przez aplikację frontendową do kolejki RabbitMQ, za pomocą serwisu RabbitService oraz metod odczytujących dane z bazy MongoDB (metody findByUuid oraz findAll) za pomocą serwisu MongoService. Oprócz tego, zawiera ona metodę deleteAll, która usuwa wszystkie dane zapisane w bazie.
Implementacja serwisu RabbitService wygląda następująco:
public class RabbitService {
private final RabbitTemplate rabbitTemplate;
private final MongoService mongoService;
@RabbitListener(queues = RabbitConfig.QUEUE_NAME)
void listen(Data data) {
log.info("Received data from queue [queue={}, data={}]", RabbitConfig.QUEUE_NAME, data);
mongoService.saveInDatabase(data);
}
void send(Data data) {
log.info("Send data to queue [queue={}, data={}]", RabbitConfig.QUEUE_NAME, data);
rabbitTemplate.convertAndSend(RabbitConfig.QUEUE_NAME, data);
}
}
Składa się ona z metody send, z której korzysta serwis DataService. Zapisuje ona dane w kolejce RabbitMQ za pomocą klasy RabbitTemplate, która jest częścią biblioteki spring-boot-starter-amqp. Druga metoda (listen), odpowiada za pobieranie wiadomości pojawiających się w kolejce i zapisywanie ich w bazie danych za pomocą serwisu MongoService.
Serwis MongoService wygląda następująco:
public class MongoService {
private final MongoOperations mongoOperations;
void saveInDatabase(Data data) {
try {
mongoOperations.insert(data);
log.info("Saved data in database");
} catch (DuplicateKeyException ignore) {
log.warn("Duplicated data from queue ignored");
} catch (Exception e) {
log.error("Error saving data in database", e);
throw e;
}
}
Data findByUuid(String uuid) {
return mongoOperations.findById(uuid, Data.class);
}
List<Data> findAll() {
return mongoOperations.findAll(Data.class);
}
void deleteAll() {
mongoOperations.dropCollection(Data.class);
}
}
Wykorzystuje on klasę MongoOperations do komunikacji z bazą danych MongoDB, za pomocą odpowiedniego sterownika. Klasa ta jest częścią biblioteki spring-boot-starter-data-mongodb. Implementacja serwisu składa się z 4 metod, odpowiedzialnych za zapis danych w bazie (saveInDatabase), odczyt (findByUuid oraz findAll) oraz usunięcie wszystkich danych (deleteAll).
W celu komunikacji aplikacji backendowej z aplikacją frontendową za pomocą REST API, zaimplementowany został kontroler DataController, wystawiający metody serwisu DataService jako endpointy REST API. Jego implementacja wygląda następująco:
@RestController
@RequestMapping("/api")
@RequiredArgsConstructor
public class DataController {
private final DataService dataService;
@PostMapping
public ResponseEntity<Data> save(@RequestBody @Valid Data data) {
log.debug("> save [data={}]", data);
Data savedData = dataService.saveInQueue(data);
log.debug("< save [savedData={}]", savedData);
return ResponseEntity.status(HttpStatus.ACCEPTED).body(savedData);
}
@GetMapping("/{uuid}")
public ResponseEntity<Data> getById(@PathVariable String uuid) {
log.debug("> getById [uuid={}]", uuid);
Data dataFromDb = dataService.findByUuid(uuid);
log.debug("< getById [dataFromDb={}]", dataFromDb);
if (dataFromDb == null) {
return ResponseEntity.notFound().build();
}
return ResponseEntity.ok(dataFromDb);
}
@GetMapping
public ResponseEntity<List<Data>> getAll() {
log.debug("> getAll");
List<Data> dataFromDb = dataService.findAll();
log.debug("< getAll [resultSize={}]", dataFromDb.size());
if (dataFromDb.isEmpty()) {
return ResponseEntity.notFound().build();
}
return ResponseEntity.ok(dataFromDb);
}
@DeleteMapping
@ResponseStatus(code = HttpStatus.ACCEPTED)
public void deleteAll() {
log.debug("> deleteAll");
dataService.deleteAll();
log.debug("< deleteAll");
}
@ResponseStatus(HttpStatus.BAD_REQUEST)
@ExceptionHandler(MethodArgumentNotValidException.class)
public Map<String, String> handleValidationExceptions(
MethodArgumentNotValidException ex) {
Map<String, String> errors = new HashMap<>();
ex.getBindingResult().getAllErrors().forEach(error -> {
String fieldName = ((FieldError) error).getField();
String errorMessage = error.getDefaultMessage();
errors.put(fieldName, errorMessage);
});
return errors;
}
}
Oprócz wystawienia metod serwisu DataService jako endpointy REST API, kontroler obsługuje również błędy (np. wynikające z niepoprawnego wywołania lub niepoprawnego modelu przekazywanych danych do zapisu) za pomocą metody handleValidationExceptions.
Oprócz wyżej wymienionych klas, aplikacja backendowa składa się dodatkowo z konfiguracji kolejki RabbitMQ (klasa RabbitConfig - 24 linie kodu), konfiguracji CORS (klasa WebConfig - 19 linii kodu), modelu danych (klasa Data - 26 linii kodu) oraz głównej klasy BackendApplication, odpowiedzialnej za uruchomienie aplikacji (12 linii kodu). Cała aplikacja składa się z 8 klas Javy oraz pliku konfiguracyjnego application.yml.
Implementacja funkcji, zastępująca aplikację backendową wygląda następująco:
const Firestore = require('@google-cloud/firestore');
const firestore = new Firestore({
projectId: process.env.GCP_PROJECT
});
exports.main = (event, context) => {
const message = JSON.parse(Buffer.from(event.data, 'base64').toString());
console.log(`Save Pub/Sub message in db [data=${JSON.stringify(message)}, context=${JSON.stringify(context)}]`);
const document = firestore.collection(process.env.COLLECTION_NAME).doc(message.uuid);
document.set({
uuid: message.uuid,
manufacturer: message.manufacturer,
model: message.model
}).then(doc => {
console.log(`Data saved [doc=${JSON.stringify(doc)}]`);
}).catch(err => {
console.error(err);
throw new Error(`Error saving data...`);
});
};
Składa się ona z jednej funkcji main, której zadaniem jest zdekodowanie wiadomości z usługi Cloud Pub/Sub z formatu Base64 oraz zapisanie danych w usłudze Cloud Firestore.
Funkcja wykorzystuje do komunikacji z usługą Cloud Firestore bibliotekę @google-cloud/firestore, a samo wywołanie funkcji wyzwalane jest przez usługę Cloud Pub/Sub, w momencie pojawienia się wiadomości w odpowiednim topicu.
Ilość kodu została drastycznie zmniejszona. Aplikacja backendowa została całkowicie zastąpiona przez funkcję, składającą się z 21 linii kodu JavaScript. Dzięki migracji z wykorzystaniem strategii “Rip and replace”, udało się znacząco uprościć architekturę i zredukować tzw. boilerplate code, który często występuje w aplikacjach napisanych w języku Java.
Funkcję możemy wdrożyć z poziomu GUI (Cloud Console), lub za pomocą polecenia:
gcloud functions deploy demo-function \
--entry-point main \
--runtime nodejs10 \
--trigger-topic demo-topic \
--region europe-west3 \
--timeout 10 \
--memory 128MB \
--max-instances 1 \
--set-env-vars COLLECTION_NAME=demo-collection \
--project PROJECT_ID
Niezależnie od sposobu wdrażania, musimy odpowiednio skonfigurować funkcję:
- entry-point - nazwa metody (w języku JavaScript zwanej funkcją), która jest wywoływana przy triggerowaniu funkcji;
- runtime - środowisko uruchomieniowe;
- trigger-topic - topic w Cloud Pub/Sub, w którym pojawienie się wiadomości triggeruje wywołanie funkcji;
- region - region, w który funkcja fizycznie będzie uruchamiana;
- timeout - maksymalny czas wykonywania funkcji, po przekroczeniu którego funkcja jest automatycznie zakańczana błędem;
- memory - rozmiar pamięci, jaka będzie przydzielona funkcji w trakcie wywołania;
- max-instances - maksymalna liczba instancji, które mogą zostać utworzone (automatyczne skalowanie);
- set-env-vars - zmienne środowiskowe, które będą wykorzystane w funkcji, w naszym wypadku jest to nazwa kolejki w Cloud Firestore, do której będą zapisywane dane;
- project - id projektu.
Dodatkowo moglibyśmy skonfigurować ponawianie przetwarzania wiadomości, w przypadku błędu wywołania funkcji, ale nie będziemy tego robić.
Baza danych
Konfiguracja Cloud Firestore jest jeszcze łatwiejsza, niż konfiguracja Cloud Pub/Sub, ponieważ nie wymaga absolutnie żadnych czynności do jej uruchomienia.
Dane zapisywane i odczytywane są poprzez REST API, wskazując w adresie url identyfikator projektu, domyślną bazę danych oraz strukturę w której dane mają być utrwalone. Zapis danych nie wymaga istnienia struktury, ponieważ zostanie ona utworzona przy pierwszym zapisie.
Adres url do zapisu oraz odczytu (environment.firestoreUrl) danych do kolekcji o nazwie demo-collection wygląda następująco:
https://firestore.googleapis.com/v1/projects/PROJECT_ID/databases/(default)/documents/demo-collection
Zamiana bazy danych MongoDB, z którą komunikacja odbywała się poprzez sterownik bazodanowy w aplikacji backendowej, na usługę Cloud Firestore, niesie ze sobą pewne ograniczenia. Wynikają one z interfejsu REST API, który udostępnia usługa, przez co pewne operacje mogą być niemożliwe.
W przypadku bazy MongoDB, można było wykonać dowolne zapytanie, na przykład usuwające wszystkie dane z bazy (w przykładzie wykorzystałem wysokopoziomowy interfejs MongoOperations, ale można również wywołać dowolne polecenie na bazie danych):
void deleteAll() {
mongoOperations.dropCollection(Data.class);
}
Według dokumentacji REST API usługi Cloud Firestore, nie ma możliwości usunięcia wszystkich danych jednym żądaniem HTTP. Aby usunąć wszystkie dane z poziomu aplikacji, należałoby najpierw pobrać ich identyfikatory, a następnie usuwać je pojedynczo lub w paczkach, co byłoby mało wydajne. Zakładamy jednak, że usuwanie wszystkich danych przez aplikację, jest raczej mało realnym przypadkiem użycia, dlatego nie będziemy implementować takiej operacji. Chciałem jedynie na jej przykładzie przedstawić problemy, na jakie możemy trafić w przypadku usług SaaS i ich interfejsów.
Gdybyśmy chcieli jednak zaimplementować taką operację, moglibyśmy na przykład utworzyć dodatkową funkcję, która przyjmowałaby polecenie z aplikacji frontendowej, a następnie pobierała dokumenty w paczkach z Cloud Firestore i usuwała je. Taka operacja powinna być wykonywana asynchronicznie i w sposób umożliwiający ponawianie, ponieważ w przypadku dużej ilości danych, proces ten może być czasochłonny.
Uprawnienia
Aby umożliwić komunikację z usługami (zapis danych do usługi Cloud Pub/Sub oraz odczyt z usługi Cloud Firestore), należy skonfigurować uprawnienie dla użytkownika w usłudze Cloud IAM. Komunikacja z usługami odbywa się bezpośrednio z aplikacji frontendowej, dlatego do uwierzytelnienia wykorzystywane jest konto zalogowanego użytkownika. W przypadku, kiedy operacje te byłyby wykonywane przez inną usługę GCP, np. Compute Engine, to musielibyśmy utworzyć odpowiednie konto serwisowe (service account) i nadać mu odpowiednie uprawnienia. Konta serwisowe są wykorzystywane przez usługi GCP, w celu uwierzytelniania przed innymi usługami.
W celach demonstracyjnych, możemy wykorzystać nasze konto, które posiada uprawnienie właściciela projektu. Gdybyśmy chcieli umożliwić korzystanie z systemu innym użytkownikom, powinniśmy utworzyć odpowiednią rolę, posiadającą wymagane uprawnienia oraz nadać tę rolę każdemu użytkownikowi. Jest wiele sposobów na zarządzanie użytkownikami w Google Cloud. Można zaimportować ich z pliku CSV, utworzyć ręcznie, wykorzystać rozwiązania zewnętrzne takie jak Okta czy Ping lub skorzystać z zalecanego rozwiązania, czyli narzędzia Google Cloud Directory Sync.
Optymalizacja
Etap optymalizacji polega na monitorowaniu aplikacji w poszukiwaniu błędów, optymalizacji wydajności oraz wykonywaniu zmian, na które nie było czasu lub budżetu przed wdrożeniem.
Poprawa błędów
Monitorowanie logów aplikacji w usłudze Cloud Monitoring pozwoliło na wykrycie błędu w kodzie funkcji.
Podczas jednego z zapisów, w logach zabrakło informacji o pomyślnym zapisaniu danych w Cloud Firestore, nie było również żadnego błędu. W efekcie, po wykonaniu trzech zapisów, utrwalone zostały jedynie dane z dwóch ostatnich:
2020-08-12T18:29:51 g8xx0fyvsqhl Function execution started
2020-08-12T18:29:51 g8xx0fyvsqhl Save Pub/Sub message in db
2020-08-12T18:29:51 g8xx0fyvsqhl Function execution took 217 ms, finished with status: 'ok'
2020-08-12T18:50:15 2kcnvesdjzpp Function execution started
2020-08-12T18:50:16 2kcnvesdjzpp Save Pub/Sub message in db
2020-08-12T18:50:16 2kcnvesdjzpp Function execution took 413 ms, finished with status: 'ok'
2020-08-12T18:51:18 2kcnvesdjzpp Data saved
2020-08-12T18:52:59 2kcnvlflowql Function execution started
2020-08-12T18:52:59 2kcnvlflowql Save Pub/Sub message in db
2020-08-12T18:52:59 2kcnvlflowql Function execution took 19 ms, finished with status: 'ok'
2020-08-12T18:53:00 2kcnvlflowql Data saved
Jak widać w powyższym logu, w pierwszym z trzech wywołań funkcji, brakuje informacji Data saved. Fakt, że informacja ta jest w pozostałych przypadkach logowana po informacji o zakończeniu wywołania funkcji sugeruje, że zapis do Cloud Firestore jest wykonywany asynchronicznie, czyli może trwać dłużej niż czas wykonywania samej funkcji. Przeglądając kod funkcji, szybko udaje się znaleźć błąd, w postaci brakującego słowa kluczowego return, dzięki któremu funkcja będzie czekała na zakończenie się wywołania asynchronicznej metody document.set:
exports.main = (event, context) => {
const message = JSON.parse(Buffer.from(event.data, 'base64').toString());
console.log(`Save Pub/Sub message in db [data=${JSON.stringify(message)}, context=${JSON.stringify(context)}]`);
const document = firestore.collection(process.env.COLLECTION_NAME).doc(message.uuid);
return document.set({
uuid: message.uuid,
manufacturer: message.manufacturer,
model: message.model
}).then(doc => {
console.log(`Data saved [doc=${JSON.stringify(doc)}]`);
}).catch(err => {
console.error(err);
throw new Error(`Error saving data...`);
});
};
Usprawnienia
Na etapie optymalizacji można również wykonywać zmiany, które są wynikiem dalszego zdobywania wiedzy po wdrożeniu lub pojawiania się nowych możliwości w Google Cloud. Jednym z nich jest na przykład możliwość utworzenia konfiguracji strony www w Cloud Storage.
W dokumentacji usługi Cloud Storage znajduje się informacja o tym, że w przypadku nadania bucketowi nazwy, będącej poprawnym adresem URL, pojawi się dodatkowa opcja konfiguracji dla witryny internetowej. Dzięki temu, można skonfigurować plik, który ma być udostępniany użytkownikowi po wejściu na adres www.
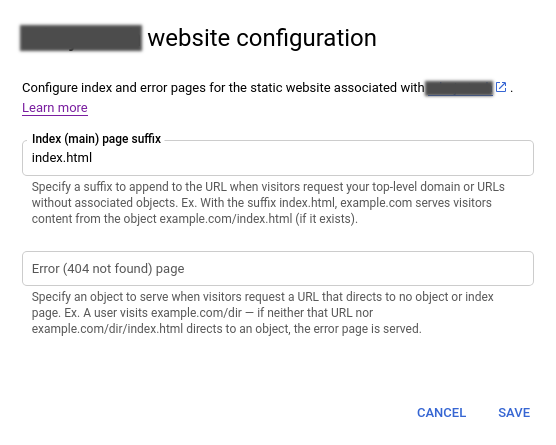
Aby nadać bucketowi nazwę domeny, należy wcześniej wykonać weryfikację własności domeny (pod tym adresem). Konfigurując w ten sposób bucket, nie potrzebujemy HTTP/S Load Balancera do działania aplikacji. Nie jest to jednak dobre rozwiązanie w przypadku środowiska produkcyjnego, ponieważ bez usługi Cloud Load Balancing nie ma możliwości skonfigurowania certyfikatu HTTPS, a wykorzystywanie nieszyfrowanego połączenia pomiędzy użytkownikiem a aplikacją internetową, jest złą praktyką.
Dodatkowo, w konfiguracji domeny, zamiast podawać adres IP w rekordzie typu A, należy podać adres c.storage.googleapis.com, w rekordzie typu CNAME.
Więcej informacji znajdziemy tutaj: Hosting a static website, Static website examples and tips.
Automatyzacja
Innym elementem etapu optymalizacji mogą być na przykład usprawnienia w procesie wdrażania aplikacji. Stwórzmy zatem proste CI/CD, wykorzystując do tego celu repozytorium GitHub, usługę Cloud Build oraz infrastrukturę jako kod (IaC), opartą o Terraform. Jako alternatywę dla Terraform moglibyśmy wykorzystać Cloud Deployment Manager, ale wtedy uzależnilibyśmy się od chmury Google (vendor lock).
Przed implementacją, musimy jeszcze:
- utworzyć bucket w usłudze Cloud Storage, który przechowywać będzie stan infrastruktury, wykorzystywany przez Terraform:
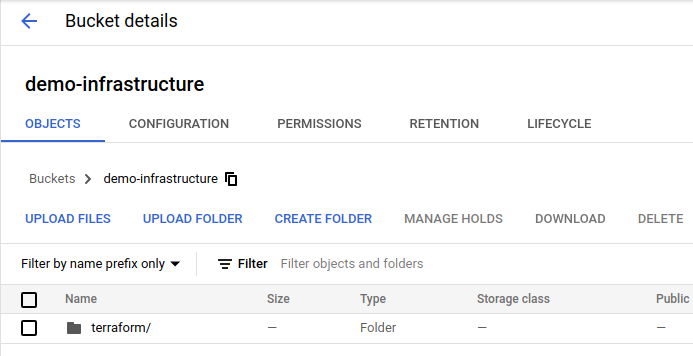
- połączyć repozytorium GitHub, zawierające kody aplikacji, z usługą Cloud Build. W celu integracji, w repozytorium GitHub należy zainstalować aplikację Google Cloud Build, a następnie połączyć repozytorium z usługą Cloud Build:
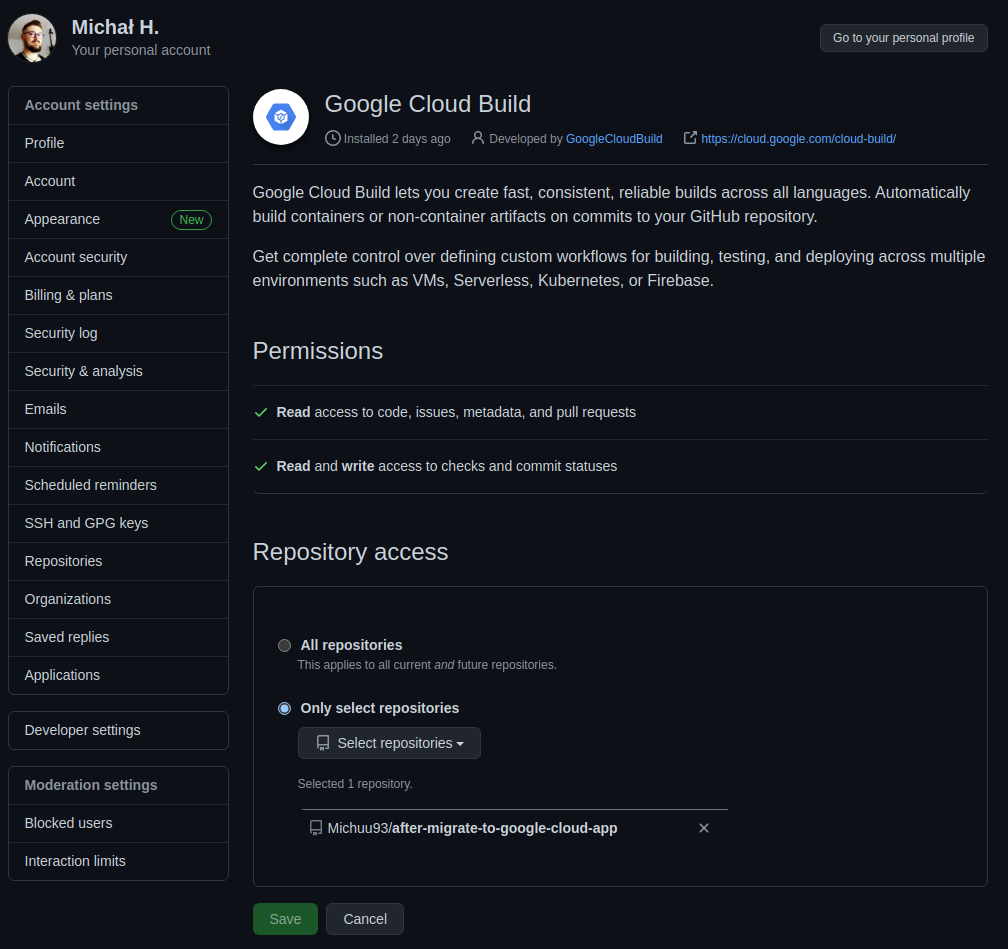
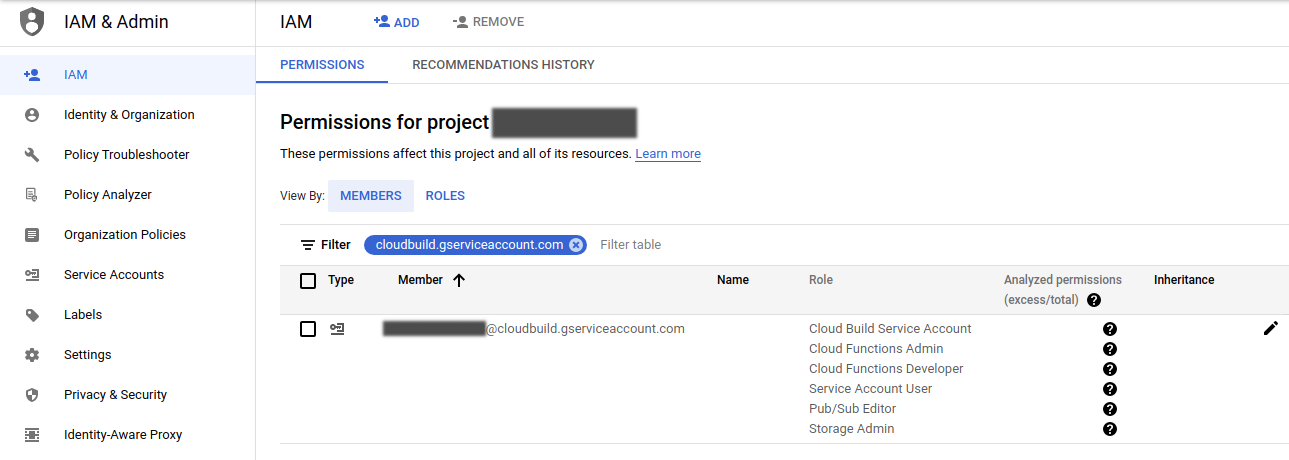
- w Cloud IAM przydzielić uprawnienia do konta serwisowego, z którego korzysta Cloud Build: Cloud Build Service Account, Cloud Functions Admin, Cloud Functions Developer, Service Account User, Pub/Sub Editor, Storage Admin:
- nadać uprawnienie do zweryfikowanej domeny dla konta serwisowego Cloud Build (pod tym adresem):
Konfiguracja automatyzująca tworzenie infrastruktury oraz wdrażanie aplikacji składa się z dwóch części:
- konfiguracji Terraform, definiującej infrastrukturę, np. trigger w Cloud Build, który na podstawie zmian kodu w repozytorium uruchamia zadanie;
- konfiguracji Cloud Build, czyli definicji zadań do wykonania, które są uruchamiane przez triggery utworzone przez Terraform.
Konfiguracja Terraform
Konfiguracja Terraform jest umieszczona w folderze infrastructure i składa się z:
- konfiguracji tzw. backendu, który w Terraform jest abstrakcją, określającą m.in. w jaki sposób ładowany jest stan infrastruktury (infrastructure/backend.tf):
terraform {
backend "gcs" {
bucket = "demo-infrastructure"
prefix = "terraform/state"
}
}
W drugiej linii definiujemy typ backendu, w tym przypadku gcs, który przechowuje stan w usłudze Cloud Storage. Następnie definiujemy nazwę utworzonego wcześniej bucketu, w którym będzie przechowywany stan, oraz prefix, będący ścieżką folderów, w których stan będzie się znajdował,
- konfiguracji providera (infrastructure/main.tf):
provider "google-beta" {
project = var.gcp-project
region = var.gcp-region
zone = var.gcp-zone
}
Terraform udostępnia dwóch dostawców dla Google Cloud: google, google-beta. W pierwszej linii definiujemy dostawcę google-beta, który umożliwia wykorzystywanie API, które w GCP jest w wersji beta. W kolejnych liniach definiujemy projekt, region oraz strefę, które w tym przypadku są pobierane ze zmiennych,
-
definicji zmiennych, wykorzystywanych przez konfigurację Terraform (infrastructure/variables.tf i infrastructure/terraform.tfvars) (niektóre ze zmiennych są również przekazywane przez Terraform do Cloud Build);
-
konfiguracji triggera Cloud Build, który na podstawie zmian kodów konfiguracji infrastruktury w repozytorium (folder infrastructure), uruchamia zdefiniowane zadanie w Cloud Build:
resource "google_cloudbuild_trigger" "deploy-demo-infrastructure" {
provider = google-beta
name = "deploy-demo-infrastructure"
description = "[demo] Deploy main: infrastructure"
filename = "infrastructure/build/deploy.cloudbuild.yaml"
included_files = [
"infrastructure/**"
]
github {
owner = var.github-owner
name = var.github-repository
push {
branch = "^main$"
}
}
}
W pierwszej linii określamy rodzaj tworzonego zasobu (google_cloudbuild_trigger - trigger w usłudze Cloud Build). W kolejnych liniach definiujemy providera, nazwę triggera, jego opis, ścieżkę pod którą znajduje się definicja zadań do wykonania przez Cloud Build, ścieżkę w której zmiana plików spowoduje uruchomienie zadania oraz konfigurację repozytorium GitHub. W konfiguracji repozytorium definiujemy jego położenie (parametr owner i name) oraz sposób triggerowania zadania Cloud Build, w tym przypadku jest to wypushowanie zmian kodów do brancha main (dostępne są m.in. opcje triggerowania na push taga lub utworzenie pull requesta w aplikacji GitHub),
- konfiguracji tworzącej buckety w Cloud Storage (infrastructure/frontend-bucket.tf i infrastructure/yarn-cache.storage.tf), które wykorzystywane są m.in. do przechowywania plików statycznych aplikacji frontendowej oraz kopii podręcznej zależności, wykorzystywanych przez aplikację frontendową i funkcję (w dalszej części wyjaśnię o co chodzi);
- konfiguracji topicu w usłudze Cloud Pub/Sub (infrastructure/pubsub.tf);
- konfiguracji triggerów w usłudze Cloud Build, które na podstawie zmian w repozytorium GitHub, uruchamiają zdefiniowane zadania (o tym też za chwilę).
Konfiguracja Cloud Build
Drugą z konfiguracji, jest konfiguracja usługi Cloud Build, czyli definicja wykonania zadań, potrzebnych do zbudowania i wdrożenia poszczególnych elementów systemu. Definicja wdrażania dla każdego elementu systemu znajduje się w folderze zawierającym jego kody źródłowe. Składa się ona z:
- konfiguracji wdrażania infrastruktury (infrastructure/build/deploy.cloudbuild.yml):
steps:
- name: 'hashicorp/terraform:0.12.26'
entrypoint: 'sh'
args:
- '-c'
- |
terraform init && terraform apply -auto-approve
dir: 'infrastructure'
Składa się ona z jednego kroku, który za pomocą powłoki systemu Linux (sh), wykonuje w folderze infrastructure następujące polecenia: terraform init (inicjalizujące Terraform), terraform apply -auto-approve (tworzące infrastrukturę za pomocą konfiguracji Terraform),
- konfiguracji budowania i wdrażania aplikacji frontendowej (frontend/deploy.cloudbuild.yml);
- konfiguracji wdrażania funkcji (function/deploy.cloudbuild.yml).
Dependency cache
Kopia podręczna zależności, wykorzystywanych przez aplikację frontendową oraz funkcję, przechowywana jest w przeznaczonym do tego celu buckecie.
Aplikacje JavaScript (a więc te oparte o framework Angular, jak i funkcje napisane w czystym JavaScript) wykorzystują zewnętrzne zależności (biblioteki, moduły), które przechowują w folderze node_modules. Za każdym razem, kiedy aplikacja lub funkcja są budowane, muszą one pobrać wszystkie zależności z których korzystają. Bardzo często, zależności liczone są w dziesiątkach, a nawet setkach, a pobranie wszystkich za każdym razem, powoduje niepotrzebne wykorzystywanie łącza internetowego oraz dłuższy czas wykonywania zadania w usłudze Cloud Build (która posiada darmowy limit w postaci 120 minut, za które w ciągu dnia nie trzeba dodatkowo płacić).
Chcąc zoptymalizować czas budowania i wdrażania, a także koszty z tym związane, utworzone zostały skrypty (w folderze yarn-cache-builder), które przed pobraniem zależności z Internetu, sprawdzają najpierw, czy nie istnieje już paczka (plik .zip), zawierająca te zależności w Cloud Storage. Jeśli tak, to zależności te pobierane są z bucketu i wypakowywane, co zajmuje o wiele mniej czasu, niż pobieranie ich ponownie.
Kopia podręczna tworzona jest na podstawie sumy kontrolnej MD5 pliku yarn.lock, który zawiera listę wymaganych zależności. Jeśli zależności te się nie zmieniły (np. nie dodano nowych lub nie zmieniono wersji którejś z nich), to można wykorzystać zależności przechowywane w buckecie. Jeśli jednak coś się zmieniło, to zostaną one pobrane z Internetu, a następnie spakowane do archiwum .zip, zawierającego w nazwie sumę kontrolną i umieszczone w buckecie.
Konfiguracja Terraform (infrastructure/yarn-cache.storage.tf) tworząca bucket, przeznaczony na kopie podręczne zależności, wygląda następująco:
resource "google_storage_bucket" "demo-yarn-cache" {
provider = google-beta
name = var.cache-bucket-name
location = var.gcp-region
lifecycle_rule {
condition {
age = "7"
}
action {
type = "Delete"
}
}
}
W pierwszej linii określamy rodzaj tworzonego zasobu (google_storage_bucket - bucket w usłudze Cloud Storage). W kolejnych liniach definiujemy providera, nazwę tworzonego bucketu, region w którym będzie utworzony oraz regułę cyklu życia plików. Reguła definiuje akcję usunięcia plików starszych niż 7 dni.
Skrypt tworzący kopię podręczną zależności (yarn-cache-builder/yarn-cache-push.sh) wygląda następująco:
lockChecksum=$(md5sum yarn.lock | cut -d' ' -f1)
cacheArchive=$(basename "$PWD").node_modules.${lockChecksum}.tar.gz
if gsutil -q stat ${1}/"$cacheArchive"; then
echo "cache archive already exists (${cacheArchive})"
else
tar -czf "$cacheArchive" node_modules
gsutil -m cp "$cacheArchive" ${1}/
fi
W pierwszej linii tworzy on sumę kontrolną MD5 pliku yarn.lock. W drugiej definiuje nazwę archiwum .zip, zawierającą sumę kontrolną. W kolejnych liniach definiuje warunek sprawdzający, czy plik o takiej nazwie już istnieje (co sugeruje brak potrzeby odkładania do bucketu kopii podręcznej zasobów), w przeciwnym wypadku tworząc archiwum zawierające folder node_modules i umieszczając je w buckecie. Do komunikacji z usługą Cloud Storage wykorzystywane jest narzędzie gsutil, a nazwa bucketu przekazywana jest do skryptu w parametrze ${1}.
Skrypt pobierający kopię podręczną zależności (yarn-cache-builder/yarn-cache-push.sh) wygląda następująco:
lockChecksum=$(md5sum yarn.lock | cut -d' ' -f1)
cacheArchive=$(basename "$PWD").node_modules.${lockChecksum}.tar.gz
if gsutil -q stat ${1}/"$cacheArchive"; then
gsutil -m cp ${1}/"$cacheArchive" .
tar -xzf "$cacheArchive"
fi
Pierwsze dwie linie są identyczne, jak w skrypcie tworzącym. W kolejnych liniach zdefiniowany jest warunek, sprawdzający czy plik o odpowiedniej nazwie istnieje. W przypadku istnienia pliku z odpowiednią sumą kontrolną, archiwum .zip pobierane jest za pomocą narzędzia gsutil, a następnie wypakowywane. Dzięki temu, zależności w trakcie budowania aplikacji, będą już istnieć w folderze node_modules i nie będą pobierane z Internetu.
Konfiguracja frontendu
Konfiguracja aplikacji frontendowej składa się z:
- konfiguracji Terraform (infrastructure/frontend.deploy.tf):
resource "google_cloudbuild_trigger" "deploy-main-demo-frontend" {
provider = google-beta
name = "deploy-main-demo-frontend"
description = "[demo] Deploy main: frontend"
filename = "frontend/deploy.cloudbuild.yaml"
included_files = [
"frontend/**"
]
github {
owner = var.github-owner
name = var.github-repository
push {
branch = "^main$"
}
}
substitutions = {
_CACHE_BUCKET = "gs://${var.cache-bucket-name}"
_FRONTEND_BUCKET = "gs://${var.frontend-bucket-name}"
}
}
Konfiguracja Terraform aplikacji frontendowej nie różni się za bardzo od konfiguracji infrastruktury, ponieważ również tworzy trigger w usłudze Cloud Build. Różnicą jest tutaj inna ścieżka do definicji zadań Cloud Build oraz inna ścieżka do folderu, w którym zmiany wyzwolą uruchomienie zadania, a także przekazanie zmiennych do konfiguracji Cloud Build,
- konfiguracji Cloud Build (frontend/deploy.cloudbuild.yaml):
steps:
- id: fetch-dependencies-cache
name: gcr.io/cloud-builders/gsutil
entrypoint: bash
args: ['../yarn-cache-builder/yarn-cache-fetch.sh', '${_CACHE_BUCKET}']
dir: 'frontend'
- id: yarn-install
name: node:12.13.1
entrypoint: yarn
args: ['install']
dir: 'frontend'
- id: yarn-build
name: node:12.13.1
entrypoint: yarn
args: ['build']
dir: 'frontend'
- id: copy-dist
name: gcr.io/cloud-builders/gsutil
args: ['cp','-r','frontend/dist/frontend-app/*', '${_FRONTEND_BUCKET}']
waitFor:
- yarn-build
- id: push-dependencies-cache
name: gcr.io/cloud-builders/gsutil
entrypoint: bash
args: ['../yarn-cache-builder/yarn-cache-push.sh', '${_CACHE_BUCKET}']
dir: 'frontend'
Konfiguracja Cloud Build składa się z kolejnych kroków, których wykonanie zbuduje i wdroży aplikację frontendową. W kroku fetch-dependencies-cache pobierana jest kopia podręczna zależności (jeśli taka istnieje), następnie wykonywane są polecenia yarn-install oraz yarn-build, które budują aplikację. Po zbudowaniu aplikacji, pliki statyczne są kopiowane do bucketa w usłudze Cloud Storage, a po zakończeniu, tworzona jest nowa kopia podręczna zależności. Wszystkie kroki są wykonywane w katalogu frontend (parametr dir), a nazwy bucketów przekazane są w postaci zmiennych: ${_FRONTEND_BUCKET} (bucket przeznaczony na pliki statyczne), ${_CACHE_BUCKET} (bucket zawierający kopię podręczną zależności). Do komunikacji z usługą Cloud Storage wykorzystywane jest narzędzie gsutil,
- konfiguracji Terraform, tworzącej bucket na pliki statyczne (infrastructure/frontend-bucket.tf):
resource "google_storage_bucket" "frontend-website-bucket" {
provider = google-beta
name = var.frontend-bucket-name
location = var.gcp-region
force_destroy = true
website {
main_page_suffix = "index.html"
}
}
resource "google_storage_bucket_iam_member" "frontend-website-bucket-public-permissions" {
bucket = google_storage_bucket.frontend-website-bucket.name
role = "roles/storage.objectViewer"
member = "allUsers"
}
Składa się ona z dwóch części. W pierwszej tworzony jest bucket w Cloud Storage. Konfiguracja jest podobna do tej, która tworzy bucket przeznaczony na kopię podręczną zależności. Główną różnicą jest tutaj parametr force_destroy, który umożliwia usunięcie bucketu, nawet jeśli zawiera on pliki, a także konfiguracja witryny internetowej (opisana wcześniej). W drugiej części nadawane są uprawnienia publiczne do bucketu (rola roles/storage.objectViewer dla allUsers).
Konfiguracja funkcji
Konfiguracja funkcji składa się z:
- konfiguracji Terraform (infrastructure/function.deploy.tf):
resource "google_cloudbuild_trigger" "deploy-main-demo-function" {
provider = google-beta
name = "deploy-main-demo-function"
description = "[demo] Deploy main: function"
filename = "function/deploy.cloudbuild.yaml"
included_files = [
"function/**"
]
github {
owner = var.github-owner
name = var.github-repository
push {
branch = "^main$"
}
}
substitutions = {
_CACHE_BUCKET = "gs://${var.cache-bucket-name}"
_PUBSUB_TOPIC = var.pubsub-topic
_FIRESTORE_COLLECTION = var.firestore-collection
_GCP_REGION = var.gcp-region
}
}
Konfiguracja Terraform funkcji jest podobna do konfiguracji aplikacji frontendowej. Jedynymi różnicami są inne ścieżki, a także przekazywane zmienne.
- konfiguracji Cloud Build (function/deploy.cloudbuild.yaml):
steps:
- id: fetch-dependencies-cache
name: gcr.io/cloud-builders/gsutil
entrypoint: bash
args: ['../yarn-cache-builder/yarn-cache-fetch.sh', '${_CACHE_BUCKET}']
dir: 'function'
- id: yarn-install
name: node:12.13.1
entrypoint: yarn
args: ['install']
dir: 'function'
- id: deploy-function
name: gcr.io/cloud-builders/gcloud
args: [
'beta', 'functions', 'deploy', 'demo-function',
'--runtime', 'nodejs10',
'--trigger-topic', '${_PUBSUB_TOPIC}',
'--region', '${_GCP_REGION}',
'--timeout', '10',
'--memory', '128MB',
'--max-instances', '1',
'--entry-point', 'main',
'--set-env-vars', 'COLLECTION_NAME=${_FIRESTORE_COLLECTION}'
]
dir: 'function'
- id: push-dependencies-cache
name: gcr.io/cloud-builders/gsutil
entrypoint: bash
args: ['../yarn-cache-builder/yarn-cache-push.sh', '${_CACHE_BUCKET}']
dir: 'function'
Konfiguracja Cloud Build składa się z kolejnych kroków, których efektem będzie działająca funkcja, wyzwalana za pomocą Cloud Pub/Sub. Kroki związane z kopią podręczną zależności są analogiczne do konfiguracji aplikacji frontendowej. Ponieważ funkcja jest napisana w czystym JavaScript, to nie wymaga budowania z TypeSript do JavaScript (jak w przypadku aplikacji frontendowej), dlatego pominięty został krok wykonujący polecenie yarn-build. W linii 7 wykonywane jest jedynie polecenie yarn-install, które pobiera wymagane przez funkcję zależności. W kroku deploy-function tworzona jest funkcja na podstawie kodów źródłowych, zawartych w folderze function. Do konfiguracji zostały przekazane zmienne: ${_PUBSUB_TOPIC} (zawierająca nazwę topicu, który triggeruje funkcję), ${_GCP_REGION} (zawierająca nazwę regionu, w którym zostanie uruchomiona funkcja), ${_FIRESTORE_COLLECTION} (zawierająca nazwę kolekcji w Cloud Firestore, w której funkcja będzie utrwalać dane) oraz zmienna zawierająca nazwę bucketu przechowującego kopię podręczną zależności.
Ponieważ triggery uruchamiające Cloud Build po zmianach konfiguracji infrastruktury (w folderze infrastructure) są tworzone przez ten sam kod, to za pierwszym razem trzeba utworzyć je ręcznie. W tym celu, w folderze infrastructure należy wykonać polecenia:
- terraform init - inicjalizuje Terraform, tworząc folder .terraform zawierający stan i wykorzystywane wtyczki;
- terraform plan - wykonuje plan działania Terraform, dzięki czemu można zweryfikować konfigurację pod kątem błędów, jeszcze przed uruchomieniem narzędzia;
- terraform apply - akceptuje zmiany wynikające ze stanu aktualnego oraz wynikającego z konfiguracji, czyli wdraża infrastrukturę do chmury. W efekcie tego polecenia, utworzone zostaną wszystkie zasoby (triggery Cloud Build, buckety Cloud Storage, topic Cloud Pub/Sub).
Kolejne zmiany kodu infrastruktury będą uruchamiać zadanie w Cloud Build, dzięki czemu zmiany infrastruktury będą automatycznie nanoszone w chmurze.
Utworzone triggery Cloud Build można również wyzwolić ręcznie, za pomocą Cloud Console. Można tam znaleźć historię wykonywanych zadań oraz logi zawierające ich przebieg.

W przedstawionym rozwiązaniu, kody aplikacji przechowywane są w repozytorium GitHub i zawierają wrażliwe dane (konfigurację w plikach frontend/src/environments/environment.ts oraz infrastructure/terraform.tfvars). Jeśli chcemy wykorzystać takie rozwiązanie, powinniśmy utworzyć prywatne repozytorium GitHub, w przeciwnym wypadku, nasza konfiguracja wycieknie do sieci. Do przechowywania konfiguracji możemy wykorzystać np. usługę Cloud Secret Manager lub zaimplementować własne rozwiązanie, oparte chociażby o Cloud Storage.
Zaletą IaC, oprócz automatyzacji tworzenia infrastruktury, jest również wersjonowanie. Każda zmiana infrastruktury wiąże się ze zmianą kodu Terraform i może wymagać np. pull requesta, lub napisania testów, sprawdzających poprawność konfiguracji. Dzięki temu, proces wdrażania infrastruktury jest powtarzalny oraz bardziej odporny na błędy, niż ręczne tworzenie zasobów z poziomu GUI, czy konsoli.
Migracja do chmury - podsumowanie
Opisany przeze mnie proces migracji do chmury Google Cloud Platform, jest jedynie przykładem, zawierającym minimalną ilość wiedzy, potrzebnej do rozpoczęcia przygody z chmurą Google. Nie powinniśmy podejmować się takiego procesu nie posiadajac wcześniej wiedzy na temat usług GCP, ponieważ w najgorszym wypadku, może się to skończyć bardzo wysokimi rachunkami.
Przed rozpoczęciem zabawy z GCP, proponuję zapoznać się z materiałami od Google, np. w formie kursów wideo, dostępnych na platformach Coursera czy Pluralsight. Bardzo dużo informacji znajdziemy również w oficjalnej dokumentacji GCP - od specyfikacji i API usług, po gotowe rozwiązania w formie “best practices” czy “how to”.
Warto pamiętać również o GCP Free Tier, w ramach którego otrzymujemy na start $300, które w połączeniu z darmowymi limitami, w zupełności wystarczą do zapoznania się z platformą. Kursy wideo zawierają również zadania techniczne (Qwiklabs), które wykonujemy na prawdziwej chmurze, wykorzystując do tego wygenerowane na potrzeby zadania konta - z tego również warto skorzystać.
Podobne wpisy
Czy wiesz, jak wykonać profilowanie aplikacji za pomocą JDK Flight Recorder?




