Java Stream - przetwarzanie elementów

Java Stream
Strumienie zostały dodane do Javy w wersji 8, wzbogacając język o namiastkę programowania funkcyjnego oraz alternatywę dla dobrze znanych pętli. Pierwsze pytania jakie się nasuwają, to czy warto stosować strumienie oraz jak robić to świadomie. Artykuł ma na celu analizę kilku podstawowych właściwości strumieni oraz porównanie ich z pętlami pod względem wydajności.
Intermediate vs Terminal
Java Stream API definiuje dwa rodzaje operacji, jakie możemy wykonać w trakcie przetwarzania strumieni, operacje pośrednie – intermediate, oraz operacje końcowe - terminal. Operacje pośrednie w sposób deklaratywny opisują, jak dane powinny być przetworzone, a dodatkowo zawsze zwracają obiekt typu Stream, co daje możliwość łączenia ich z kolejnymi operacjami pośrednimi. Jak widać na przykładzie strumień danych stworzony z listy filtruje te, które zaczynają się na literę “a”, następnie zamienia wszystkie litery na litery wielkie, a na koniec wyświetla przetworzone elementy. Niestety uruchamiając taki kod nic się nie zadzieje, a konsola nie wypisze żadnego elementu ponieważ w naszym strumieniu brakuje operacji końcowej - czyli takiej, która kończy strumień i sprawia, że nie można go już więcej przetwarzać.
private static final List<String> LIST = Arrays.asList("aab", "aab",
"aac", "aac",
"bbb", "ccc", "ddd",
"eee", "fff", "ggg");
public static void main(String[] args) {
LIST.stream()
.filter(e -> e.startsWith("a"))
.map(String::toUpperCase)
.peek(System.out::println);
}
Po dodaniu do kodu metody collect, dostajemy zamierzony efekt i mimo, że stworzona z przetworzonych danych lista nie jest przypisana do zmiennej, to strumień miał powód aby się wykonać. Listę metod pośrednich oraz końcowych znajdziemy tutaj.
private static final List<String> LIST = Arrays.asList("aab", "aab",
"aac", "aac",
"bbb", "ccc", "ddd",
"eee", "fff", "ggg");
public static void main(String[] args) {
LIST.stream()
.filter(e -> e.startsWith("a"))
.map(String::toUpperCase)
.peek(System.out::println)
.collect(Collectors.toList());
}
Kolejność przetwarzania
Kod prezentuje przykładowe przetwarzanie danych oparte o metodę filter oraz map.
private static final List<String> LIST = Arrays.asList("aab", "aab",
"aac", "aac",
"bbb", "ccc", "ddd");
public static void main(String[] args) {
List<String> a = LIST.stream()
.filter(e -> {
System.out.println("Stream - filter: " + e);
return e.startsWith("a");
})
.map(e -> {
System.out.println("Stream - map:" + e);
return e.toUpperCase();
})
.collect(Collectors.toList());
}
Z logów wyświetlonych w konsoli widzimy, że operacje wykonywane są horyzontalnie, to znaczy dla każdego elementu od początku do końca. Dzięki temu, sekwencja skończy się na pierwszym niespełnionym warunku a nadmiarowy kod nie jest wykonywany.
Stream - filter: aab
Stream - map:aab
Stream - filter: aab
Stream - map:aab
Stream - filter: aac
Stream - map:aac
Stream - filter: aac
Stream - map:aac
Stream - filter: bbb
Stream - filter: ccc
Stream - filter: ddd
Przetwarzanie równoległe
Wartościowym mechanizmem, który został dodany do Java Stream API jest możliwość równoległego przetwarzania strumieni, co daje możliwość wykorzystania większej liczby rdzeni procesora do wykonania zadania. Jak widać na załączonym kodzie wystarczy, że skorzystamy z metody parallelStream zamiast stream i nasze dane zostaną odpowiednio podzielone i przetworzone równolegle z użyciem wielu wątków. Stream tworzony w domyślny sposób korzysta ze wspólnej puli wątków, więc przetwarzanie w taki sposób większej ilości danych może zmniejszyć zasoby przeznaczone na inne procesy w aplikacji. Warto zwrócić uwagę na to, że samo dzielenie danych wymaga dodatkowej pracy, dlatego przeliczanie równoległe mniejszej ilości danych może trwać dłużej niż zrobienie tego samego z wykorzystaniem jednego wątku. Dodatkowo kolejność przetwarzanie elementów przez wiele wątków jednocześnie jest niedeterministyczna.
private static final List<String> LIST = Arrays.asList("aab", "aab",
"aac", "aac",
"bbb", "ccc", "ddd");
public static void main(String[] args) {
LIST.parallelStream()
.filter(e -> {
System.out.println("Stream - filter: " + e);
return e.startsWith("a");
})
.map(e -> {
System.out.println("Stream - map:" + e);
return e.toUpperCase();
})
.collect(Collectors.toList());
}
Benchmark
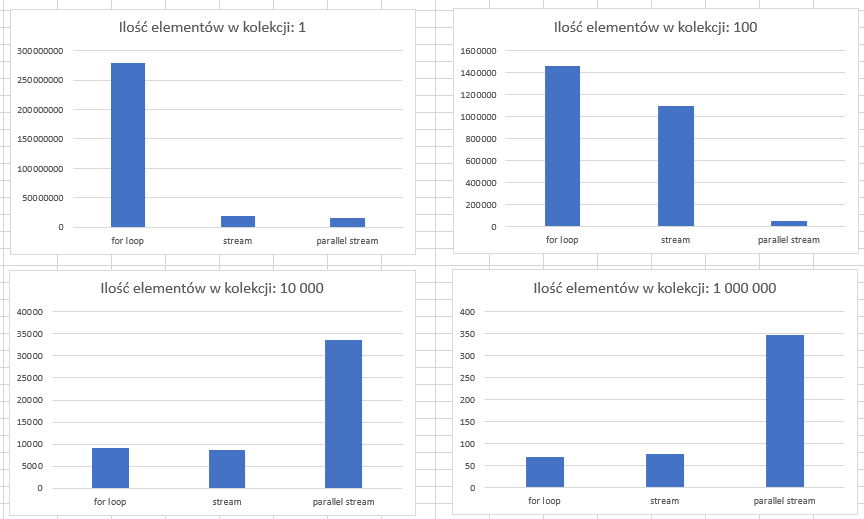
Wiemy już, jak przetwarzać Java Stream bardziej efektywnie. Nasuwa się pytanie, jak ich szybkość wypada w porównaniu do pętli, aby to sprawdzić zostały przeprowadzone testy przy użyciu Java Microbenchmark Harness i procesora Intel i7 10700K. Kod zaprezentowany niżej został uruchomiony na kolekcjach liczącej 1, 100, 10 000 oraz 1 000 000 elementów.
@Benchmark
@Fork(value = 1, warmups = 2)
public void forLoop() {
List<String> convertedList = new ArrayList<>();
for (String word : DataProvider.WORDS) {
if (word.startsWith(PREFIX)) {
convertedList.add(word.toUpperCase());
}
}
}
@Benchmark
@Fork(value = 1, warmups = 2)
public void stream() {
List<String> convertedList = DataProvider.WORDS.stream()
.filter(word -> word.startsWith(PREFIX))
.map(String::toUpperCase)
.collect(Collectors.toList());
}
@Benchmark
@Fork(value = 1, warmups = 2)
public void parallelStream() {
List<String> convertedList = DataProvider.WORDS.parallelStream()
.filter(word -> word.startsWith(PREFIX))
.map(String::toUpperCase)
.collect(Collectors.toList());
}
Jednostką pomiarową jest liczba operacji na sekundę, czyli innymi słowy, ile razy wywołano daną metodę w ciągu jednej sekundy.
Jak widać na wykresie dla 1 elementu, pętla okazała się zdecydowanie szybsza niż strumienie. Test 100 elementów pokazał że strumienie powoli doganiają zwykłą pętlę, jednocześnie strumień równoległy okazał się zdecydowanie najwolniejszym rozwiązaniem.
W kolejnych testach dla 10 000 i 1 000 000 elementów, widzimy siłę przetwarzania równoległego. Dodatkowo warto zauważyć, że dla testu największej kolekcji, przetwarzanie w pętli uzyskało delikatnie słabszy wynik niż w jednowątkowym strumieniu.
Podsumowanie
Niekiedy złożone warunki filtrowania i przetwarzania kolekcji sprawiają, że kod napisany przy użyciu pętli możeby być mało czytelny. Czytelność można poprawić korzystając z Java Stream, a znając mechanizmy działające podczas przetwarzania strumieni możemy tworzyć rozwiązania równie szybkie jak przy użyciu petli.
Podobne wpisy
Czy wiesz, jak wykonać profilowanie aplikacji za pomocą JDK Flight Recorder?




