Czy Apache Kafka nadaje się do Event Sourcingu?

Nietrudno jest natknąć się na głosy mówiące, że Apache Kafka nie nadaje się do implementacji wzorca, jakim jest Event Sourcing [1]. Czy jest tak w istocie? W artykule tym postaram się przedstawić swój punkt widzenia na tę sprawę.
Aby móc debatować nad przydatnością (bądź nie) Apache Kafki do implementacji Event Sourcingu należy najpierw odpowiedzieć na pytanie - czym tak właściwie jest Event Sourcing? Z miejsca natrafiamy na problem, bowiem nie istnieje jedna, uniwersalna definicja Event Sourcingu. W zależności od źródła, natrafimy na różne definicje, nierzadko kładące nacisk na zupełnie odmienne aspekty tego modelu. W tej sytuacji najlepszym wyjściem będzie zwrócenie się do uznanych autorytetów, a konkretniej niezawodnego Martina Fowlera. W wolnym tłumaczeniu definiuje on Event Sourcing następująco:
Każda zmiana stanu systemu reprezentowana jest przez ciąg uszeregowanych eventów. [2]
Z czym to się je?
Jednak na pierwszy rzut oka definicja ta może wydawać się co najmniej enigmatyczna. Czym jest stan systemu? Czym są, i jak mają się do niego eventy?
W tym ujęciu jako stan systemu należy rozumieć aktualną postać obiektów domenowych, utrwaloną w specyficzny dla danej aplikacji sposób - w pamięci, na dysku w postaci plików, w bazie danych. W praktyce stan systemu najczęściej przechowywany jest w bazie danych.
Jak wobec tego eventy mają się do stanu? Weźmy na warsztat klasyczny przykład sklepu internetowego, w ramach którego istnieje obiekt zamówienia, na chwilę zapominając o Event Sourcingu.
Standardowy przepływ w takim przykładzie mógłby wyglądać następująco:
- klient rozpoczyna składanie zamówienia - na bazie danych tworzona jest krotka zamówienia - przy pomocy bezpośredniego bazodanowego inserta,
- klient finalizuje zamówienie - aktualizujemy krotkę zamówienia na bazie, zmieniając status zamówienia - przy pomocy bazodanowego update’a,
- klient porzuca zamówienie - usuwamy obiekt zamówienia z bazy - bezpośrednio na bazie wywołując delete’a.
Jest to do bólu klasyczny przepływ, który można odnieść do większości systemów webowych. Jak jednak wyglądałoby to w świecie Event Sourcingu? Każda z powyższych akcji nie kończyłaby się bezpośrednim uderzeniem do bazy danych. Zamiast tego, generowany byłby odpowiedni event. A więc:
- klient rozpoczyna składanie zamówienia - tworzony jest event mówiący, że klient utworzył zamówienie,
- klient finalizuje zamówienie - tworzony jest event mówiący, że klient sfinalizował zamówienie,
- klient porzuca zamówienie - tutaj analogicznie tworzymy event wyrażający akcję biznesową.
Jak wobec tego, dysponując jedynie eventami, poznać aktualny stan obiektu zamówienia?
Wyróżniamy tutaj dwa podejścia:
- pierwsze z nich mówi, że chcąc poznać stan danego obiektu, należy zebrać wszystkie dotyczące go eventy i je zagregować - to znaczy przetworzyć po kolei, “nałożyć na siebie”, aż do uzyskania wynikowego stanu obiektu. Takie podejście w praktyce jest jednak często niepraktyczne, szczególnie w dużych systemach, przetwarzających dużą liczbę eventów;
- w praktyce częściej wykorzystuje się rozwiązanie zwane state storage lub state store. Jest to odzwierciedlenie aktualnego stanu systemu, np. w formie bazy danych. Powyższe eventy byłyby w związku z tym “tłumaczone” na odpowiednie wywołania na bazie - odpowiednio insert, update oraz delete.
Należy tutaj zwrócić uwagę na dwie bardzo ważne cechy eventów. Po pierwsze, eventy powinny być domenowe, a więc abstrahować od technicznych szczegółów wybranego przez nas state store’a. Stąd też eventy niosą za sobą informację domenową - “zamówienie zostało sfinalizowane”, a nie - “wykonaj w bazie danych update na polu status, ustawiając je na final”. Po drugie, eventy powinny być idempotentne, tj. niezależnie od tego ile razy dany event zostanie przetworzony (o ile nie zostanie utracona kolejność eventów) system powinien znajdywać się w tym samym stanie.
Wracając do przykładu sklepu - po odzwierciedleniu eventów na bazie danych, będącej naszym state storem, otrzymujemy w wyniku identyczny stan bazy danych jak w przykładzie bez event sourcingu - obiekt zamówienia nie istnieje na bazie, ponieważ został usunięty. Na usta ciśnie się więc pytanie: jaki jest wobec tego sens Event Sourcingu? Po co zaprzątać sobie głowę kolejną abstrakcją i dokładać kolejne elementy do systemu, kiedy finalnie dochodzimy do identycznego stanu?
Na szczęście, istnieje szereg zalet takiego podejścia:
- ponowne przetworzenia strumienia zdarzeń - ponieważ każda zmiana stanu systemu reprezentowana jest przez event, możemy w bardzo prosty sposób ponownie ten strumień przetworzyć - kiedy chcemy wymienić state store (np. zamienić jedną bazę danych na inną), dołożyć nowy mechanizm raportowy do systemu, który musi od nowa przeanalizować aktywność naszej aplikacji, czy po prostu naprawić błędy lub rozbieżności, które wkradły się do state store’a. W ujęciu tym strumień eventów staje się źródłem prawdy w systemie,
- łatwe odpytanie o stan każdego z obiektów w dowolnym momencie - nietrudno jest sobie wyobrazić sytuację, w której chcemy poznać stan jednego z obiektów w systemie w konkretnym punkcie czasu. Bez Event Sourcingu mamy do dyspozycji jedynie aktualny stan obiektu lub jesteśmy skazani na analizę logów w celu odtworzenia cyklu życia obiektu. Wykorzystując Event Sourcing staje się to proste i bezproblemowe,
- możliwość zrzutu stanu z dowolnego momentu - chcąc przeanalizować aplikację w konkretnym momencie jej działania wystarczy przetworzyć eventy aż do tego momentu w czasie, “zrzucając” je do stojącej na boku bazy danych - tym samym, nie przeszkadzając w żaden sposób produkcyjnej bazie danych, można włączyć oraz zdebugować aplikację znajdującą się w perfekcyjnie tym samym stanie co np. w momencie wystąpienia błędu na produkcji,
- wiele różnych odzwierciedleń stanu aplikacji - pewne reprezentacje stanu aplikacji są lepsze do konkretnych zastosowań niż inne. Np. chcąc łatwo przeszukiwać nasze obiekty pod kątem tekstu wybierzemy Solra lub Elastic Search. Jednak chcąc wykonywać klasyczne zapytania bazodanowe na naszym stanie, lepszy będzie PostgreSQL. Dzięki Event Sourcingowi łatwe staje się odzwierciedlanie stanu w różnych technologiach - sprowadza się to jedynie do “przetłumaczenia” eventów na odpowiednią technologię i ponownego przetworzenia strumienia zdarzeń,
- prostsze debugowanie oraz audyt systemu - mając jawnie zdefiniowaną i zapisaną każdą zmianę każdego obiektu, debugowanie oraz audyt systemu stają się prostsze - prześledzenie zmian sprowadza się do prześledzenia eventów, bez konieczności odszyfrowywania nierzadko zawiłych logów aplikacji.
Pozostawiając za nami przykład ze sklepem internetowym, świetną ilustracją Event Sourcingu oraz jego zalet są systemy kontroli wersji, np. git:
- każda zmiana reprezentowana jest w postaci eventu (commit),
- mamy możliwość powrotu do dowolnego punktu na strumieniu zdarzeń,
- jeśli przydarzy nam się pomyłka w kodzie, możemy w każdej chwili powrócić do poprawnego stanu,
- tworzenie wynikowego stanu (w postaci plików) jest niczym innym jak agregacją pojedynczych eventów,
- debugowanie jest uproszczone, dzięki możliwości prześledzenia zmian każdej linijki kodu.
Wejście Kafki
Pozostaje więc pytanie - gdzie przechowywać eventy? Jedną z możliwych opcji jest wykorzystanie Apache Kafki jako event store’a, a więc składnicy eventów.
Czym jednak jest Kafka? U absolutnych podstaw można o Kafce myśleć jako o brokerze komunikatów - o funkcjonalności zbliżonej do ActiveMQ lub RabbitMQ. Po bliższym przyjrzeniu się tym technologiom okazuje się jednak, że Kafka jest brokerem o diametralnie innej filozofii działania niż te wcześniej wspomniane.
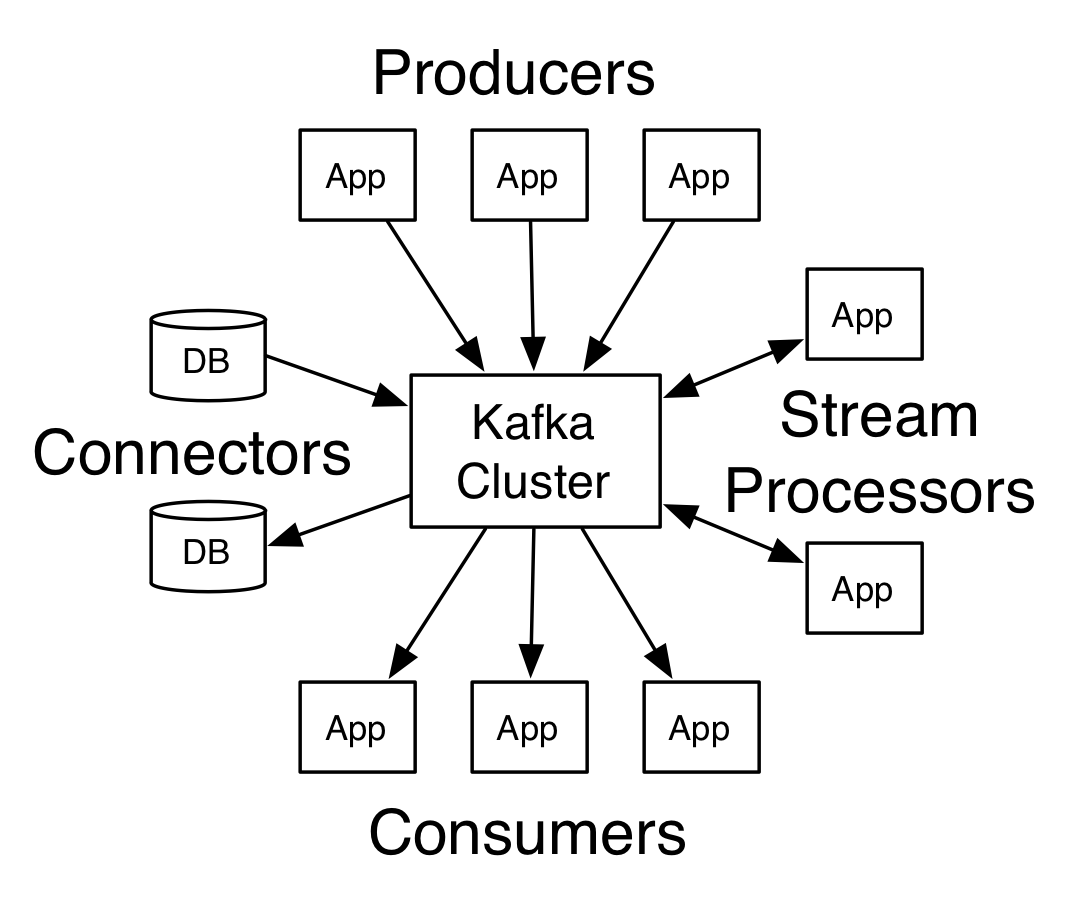
Klasyczne systemy, jak ActiveMQ, dostarczając wiadomości do konsumentów wykorzystują model Smart Broker / Dumb Consumer. Oznacza to, że broker bierze na siebie ciężar obsługi dostarczania wiadomości do konsumentów - a więc wybiera i przesyła wiadomości do odpowiednich konsumentów, oczekuje na ACK, a w przypadku błędów zajmuje się obsługą DLQ. Kafka jednak wychodzi z dokładnie odwrotnego założenia, przyjmując filozofię Dumb Broker / Smart Consumer, przerzucając na konsumentów konieczność obsługi dostarczania wiadomości.
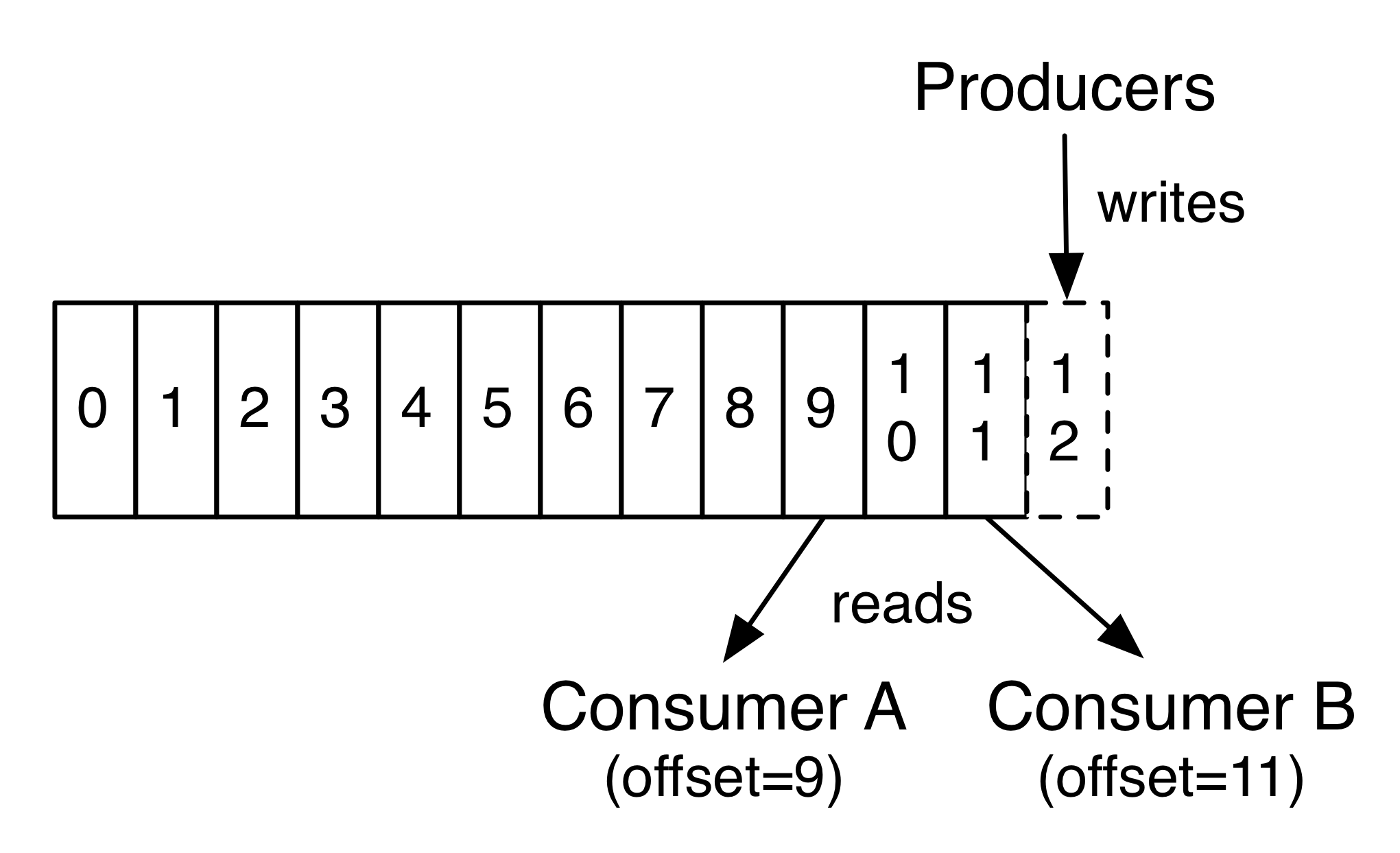
Jak działa to w praktyce? Kiedy do Kafki wpływa nowy rekord, zostaje on umieszczony na topiku, gdzie otrzymuje swój offset - w najprostszym ujęciu jest to numer porządkowy danego rekordu na topiku. Kiedy konsument chce skonsumować jeden z rekordów musi, w uproszczeniu, wskazać konkretny offset tego rekordu - jest to więc zupełne odwrócenie klasycznego modelu, w którym to broker decyduje, który rekord należy dostarczyć do konsumenta. Takie odwrócenie kontroli jest niezwykle istotne z punktu widzenia Event Sourcingu, którego jedną z podstaw jest możliwość ponownego przetworzenia strumienia zdarzeń. Ponieważ to konsument wskazuje, który rekord chce odczytać, może ustawić się na początku strumienia i przetworzyć ten strumień od nowa. Jednak możliwości są zdecydowanie większe, na przykład konsument może rozpocząć przetwarzanie od połowy strumienia w dowolnym kierunku. Co więcej, z punktu widzenia Kafki pobranie dowolnego rekordu, niekoniecznie w naturalnej kolejności, jest bardzo tanią operacją. Jest to pierwsza duża zaleta Kafki w kontekście Event Sourcingu - natywne wsparcie dla ponownego przetwarzania strumienia zdarzeń.
Kolejną zaletą jest obsługa pokaźnych wolumenów danych. Duże systemy mogą generować miliardy eventów. Nawet jeśli rozmiar pojedynczych eventów jest bardzo mały, to efekt skali powoduje, że ich sumaryczna wielkość może swobodnie przekraczać terabajty. Również tutaj Kafka nie zawodzi, obsługując liniowo zarówno wolumen danych o wielkości 50 KB jak i 50 TB [3]. Jest to kolejna duża zaleta bezpośrednio związana z Event Sourcingiem - Kafka świetnie sprawdza się w charakterze event store’a.
Na tym zalety Kafki się nie kończą, a jedną z największych jest ujednolicenie modeli kolejek oraz publisher-subscriber. Niestety, jest to już poza zakresem niniejszego artykułu.
Zarzuty
Jak wobec tego prezentują się zarzuty wobec Kafki w kontekście Event Sourcingu?
Pierwszy z nich dotyczy trudności z odczytem eventów dla konkretnego obiektu. Postuluje on konieczność przetworzenia całego strumienia zdarzeń celem odnalezienia eventów dotyczących interesującej nas instancji obiektu [1]. Jest to jednak błędny argument - z co najmniej kilku powodów. Po pierwsze, w dobie rozwiązań takich jak KSQL, odczytanie konkretnych eventów jest jak najbardziej możliwe [4]. Po drugie, argument ten rozmija się z faktyczną ideą Event Sourcingu, którego podstawą nie jest sposób wyznaczania wynikowego stanu, a sam fakt odzwierciedlania wszystkich zmian stanu w postaci eventów. Kwestia agregacji eventów do wynikowego (lub pośredniego) stanu jest już drugorzędna, w sporej mierze zależy od konkretnego rozwiązania i jako taka nie definiuje Event Sourcingu.
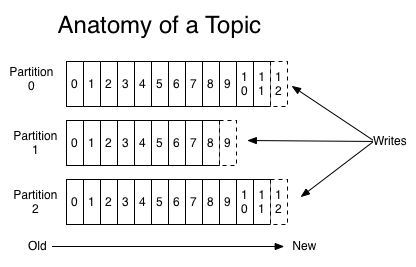
Kolejne zarzuty dotyczą spójności zapisu [1] - kiedy po odczytaniu stanu konkretnego obiektu w wyniku logiki biznesowej generujemy kolejny event zmieniający stan tego obiektu, może dojść do sytuacji, w której inny wątek w międzyczasie nadpisze lub usunie obiekt, na którym działamy. Zarzut dotyczy w praktyce braku blokad na obiektach, znanych z klasycznych baz danych. W ogólności rozwiązaniem tego problemu jest zapewnienie jednowątkowych zapisów, jednak autor przywołanego artykułu sugeruje, że będzie to miało drastyczny wpływ na wydajność zapisu. I tutaj Kafka przychodzi nam z pomocą - topiki na Kafce mogą zostać podzielone na partycje, co w połączeniu z łatwym umieszczaniem eventów dotyczących pojedynczego obiektu na jednej partycji, pozwala bezproblemowo zrównoleglić przetwarzanie, nie naruszając zasady jednowątkowego zapisu - tym samym obalając niniejszy zarzut.
Podsumowując, nie mam wątpliwości, że Kafka nadaje się do implementacji Event Sourcingu. Z jednej strony, dzięki natywnemu wsparciu dla ponownego przetwarzania eventów oraz radzeniu sobie z dużym wolumenem danych, jest to naturalny wybór jako event store. Prostą pochodną tych dwóch właściwości są pozostałe zalety Event Sourcingu - zrzuty stanu z dowolnego momentu, łatwe odzwierciedlanie stanu w innej technologii, czy też prostsze debugowanie. Z drugiej strony, dzięki bardziej zaawansowanym możliwościom przetwarzania eventów - jak streamy, KSQL, czy zrównoleglanie przetwarzania topików - Kafka staje się świetną podstawą do implementacji szeroko rozumianego Event Sourcingu.
Na zakończenie należy jeszcze zauważyć, że Event Sourcing jest wzorcem technologicznie agnostycznym - nieprzywiązanym do żadnej konkretnej technologii. Istnieją rozwiązania, jak Apache Kafka, które znacząco ułatwiają implementację Event Sourcingu, jednak nic nie stoi na przeszkodzie, żeby zaimplementować go w oparciu o MySQL, MongoDB lub jeszcze inną technologię pozwalającą na przechowywanie uszeregowanych eventów. Ostatecznie idea Event Sourcingu jest prosta: każda zmiana stanu systemu reprezentowana jest przez ciąg uszeregowanych eventów - a technologia jest już sprawą drugorzędną.
Jeśli chcecie dowiedzieć się więcej na temat Event Sourcingu, zapraszamy na pierwszą edycję Consdata Tech! Więcej informacji na temat całego wydarzenia znajdziecie pod tym linkiem: https://consdata.tech/. Co ważne, podczas tego meetupu będzie streaming, na którym warto być: http://consdata.tech/streaming.
Źródła:
Podobne wpisy





