AWS - serverless programming

Trudno dziś wyobrazić sobie branżę IT bez chmury obliczeniowej. Przeniesienie naszych serwerów do clouda i zastosowanie Infrastructure as Code (IaC) pozwala często na zoptymalizowanie kosztów, a także na zapewnienie lepszej dostępności i skalowalności rozwiązania. Architektura serverless przenosi nas jeszcze poziom wyżej - przestajemy myśleć o maszynach wirtualnych, skupiamy się na kodzie rozwiązującym konkretne potrzeby biznesowe. Wymusza ona również pewną zmianę mentalną w środowisku inżynierów IT - praca z arkuszem kalkulacyjnym i liczenie kosztów przygotowywanego rozwiązania staje się nieodłączną częścią procesu produkcji. Wraz z wprowadzeniem przez Amazon usługi AWS Lambda w 2014 roku programowanie w architekturze serverless stało się jeszcze prostsze. W artykule przedstawię przykład serwisu do przechowywania notatek, przygotowany w oparciu o architekturę serverless, dostarczaną przez AWS. Pokażę również koszty takiego rozwiązania.
Wymagania biznesowe:
- Użytkownik może zapisywać notatki tekstowe.
- Użytkownik może pobrać zapisane wcześniej notatki tekstowe.
Środowisko deweloperskie:
- Potrzebne będzie aktywne konto w Amazon AWS. Założenie takiego konta jest dość proste i dla większości usług darmowe przez pierwszy rok użytkowania. Konto możemy założyć tutaj: https://aws.amazon.com/free. Podczas tworzenia konta konieczne jest podanie danych karty kredytowej, ale przy okazji tworzenia opisanego tu serwisu będziemy używali jedynie usług wchodzących w skład rocznego free tier. W każdym momencie istnieje również możliwość sprawdzenia jakie są nasze należności dla Amazona. Niestety nie ma możliwości ustalenia granicy kwotowej, której nie chcemy przekroczyć, po której nastąpi wyłączenie naszej usługi. Można za to zdefiniować alerty, które powiadomią nas w przypadku przekroczenia ustalonej należności. Konfigurując konto w AWS warto włączyć Multi-Factor Authentication (MFA), ustrzeże nas to przed najgorszym możliwym scenariuszem, czyli przejęciem konta przez nieuprawnioną osobę. To może pociągnąć za sobą spore koszty obciążające nasz rachunek.
Implementacja odczytu notatek
Warstwa persystencji
Aby zaimplementować odczyt notatek będziemy potrzebowali jakąś warstwę persystencji, gdzie przechowywane będą dane naszych notatek, komponent który wystawi nam restowe API i coś w czym zaimplementujemy “logikę biznesową” reagującą na wywołanie API pobraniem danych z warstwy persystencji.
AWS udostępnia warstwę persystencji na różne sposoby. Mamy do dyspozycji storage plikowy S3, bazy relacyjne RDS a także bazę NoSql DynamoDB. Jeżeli chcemy być w 100% serverless, nie używamy RDS, gdyż wymaga ona utrzymywania ciągle działającej instancji (nadal nie musimy się w tym przypadku przejmować vm’kami - baza jest uruchamiana jako niezależny serwis, ale płacimy za cały czas, w którym dostępna jest baza). Do naszego zastosowania dobrze nadaje się baza DynamoDB. Aby utworzyć instancję bazy, logujemy się do konsoli AWS https://aws.amazon.com/console/ i przechodzimy do serwisu DynamoDB. Zanim utworzymy jakikolwiek zasób w konsoli AWS ważne jest określenie regionu, w którym chcemy działać. Mapa przedstawia jakie regiony są dostępne (pomarańczowe okręgi) i ile “availability zones” znajduje się w każdym regionie. Zielone okręgi oznaczają dodatkowe regiony, które będą dostępne w przyszłości.
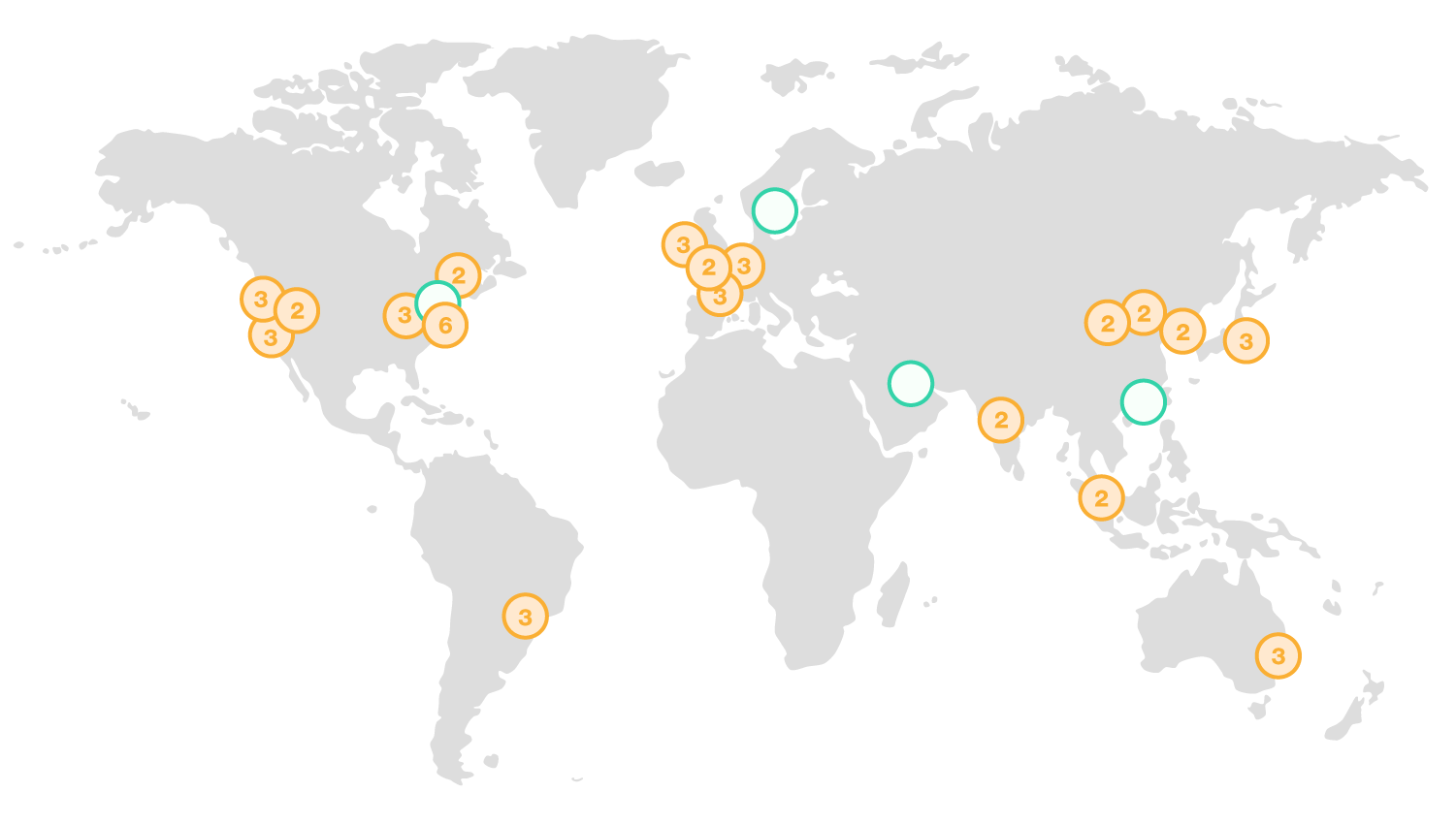
Najlepiej wybrać region, znajdujący się najbliżej lokalizacji, dla której oferujemy nasze rozwiązanie (mniejsze opóźnienia w komunikacji). Wszystkie komponenty składające się na nasze rozwiązanie powinny w miarę możliwości znajdować się w tym samym regionie. Możliwa jest oczywiście komunikacja, między różnymi regionami, ale pociąga to za sobą dodatkowe koszty. Region wybieramy klikając nazwę miasta w prawym górnym rogu konsoli:
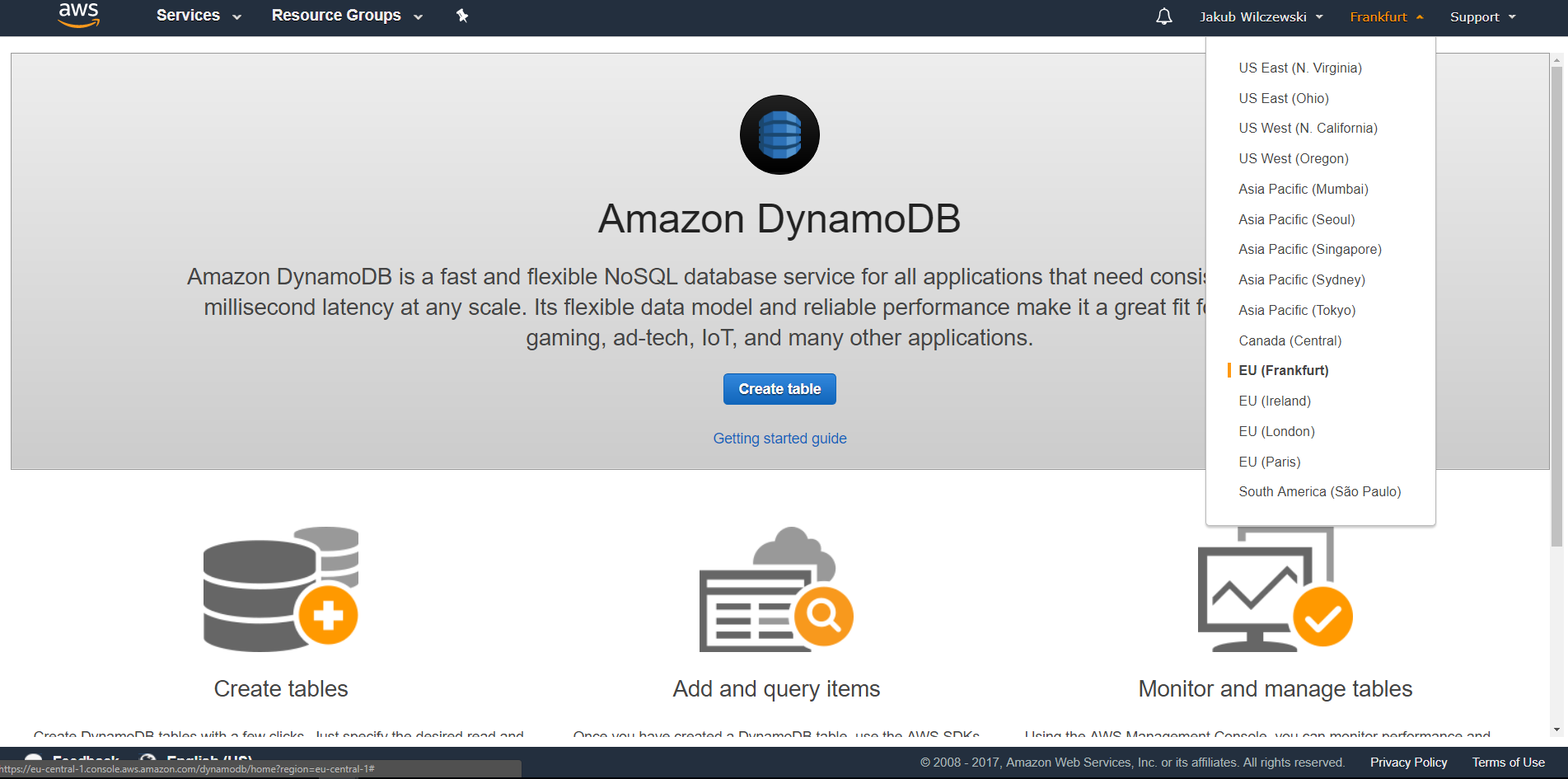
Po wybraniu regionu klikamy przycisk “Create table” i przechodzimy do widoku tworzenia tabeli. Tutaj musimy określić nazwę tabeli, np.: “notes” oraz klucz. Klucz tabeli DynamoDB może składać się z jednej lub dwóch kolumn. Pojedynczy klucz zawiera tylko tzw. partition key - kolumna, którą wybierzemy będzie używana do rozkładu danych w różnych partycjach bazy danych. Wybierając partition key pamiętajmy, że pożądane jest, aby podczas działania systemu odwoływać się do różnych partycji - to zapewnia lepsze skalowanie. W przypadku aplikacji do przechowywania notatek dobrym wyborem wydaje się nazwa użytkownika. Nie możemy jednak poprzestać na jednoczęściowym kluczu, gdyż moglibyśmy zapisać tylko jedną notatkę dla użytkownika - podobnie jak w RDS wartości klucza muszą być unikalne. Dodamy więc drugą część klucza tzw. sort key. W naszym przypadku będzie to timestamp dodania notatki:
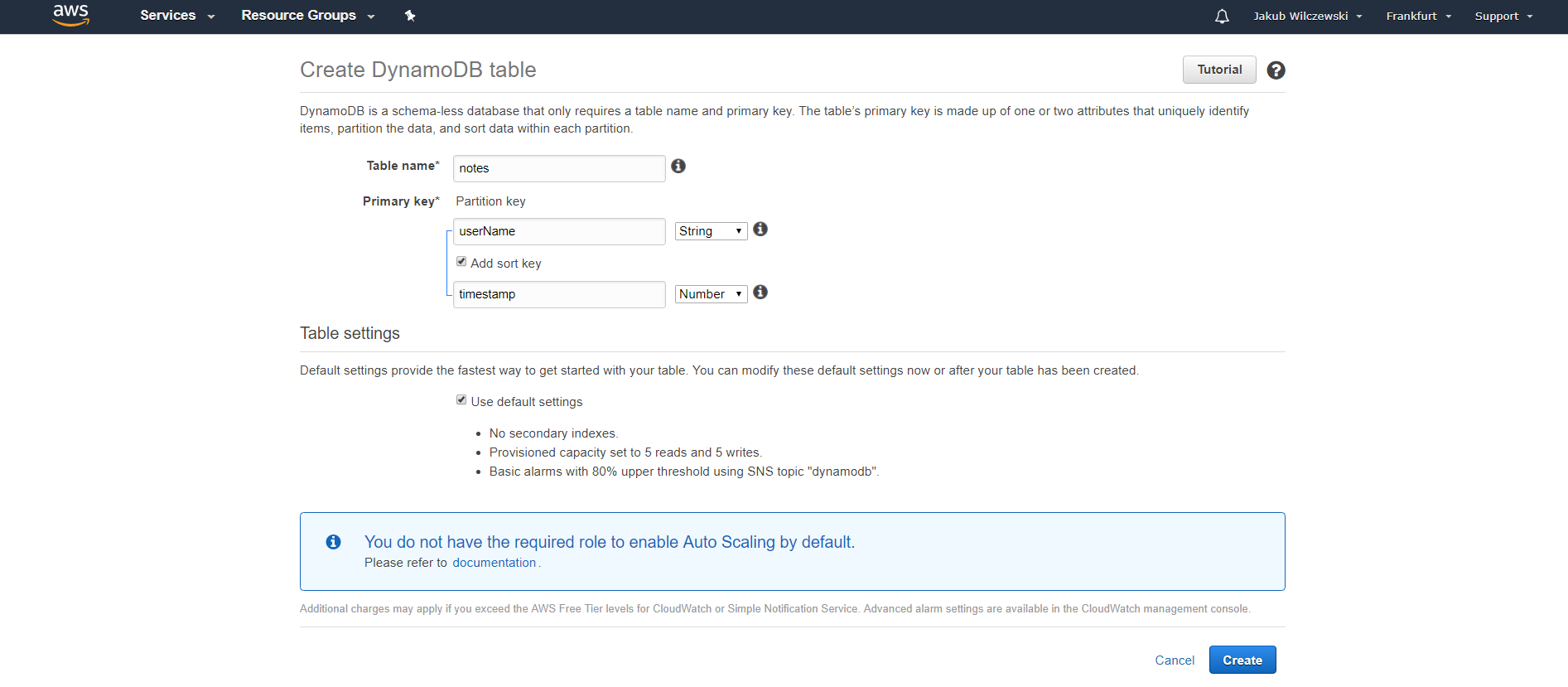
Wybór klucza tabeli jest bardzo istotnym krokiem - decyzja jest wiążąca i później nie można zmienić już klucza. Co ważne, wyszukiwanie w tabeli DynamoDB możliwe jest jedynie po kluczu lub indeksie. W innym przypadku wyszukiwanie realizowane jest jako scan tabeli. Warto tu napisać, że indeksy wyglądają inaczej niż indeksy w relacyjnej bazie danych. Indeks w DynamoDB jest de facto kopią tabeli (określamy nawet jakie kolumny znajdą się w kopii i jedynie one będą dostępne dla wyszukanego rekordu). Kopia ta jest synchronizowana w sposób asynchroniczny! z oryginalną tabelą. Przy okazji: DynamoDB zapewnia transakcyjność jedynie na poziomie pojedynczego wiersza tabeli - możliwe są tzw. conditional updates, czyli modyfikacja wiersza jeżeli spełnia on określone kryteria. Klasyczna transakcyjność typu przelew z konta A na konto B nie jest wspierana!
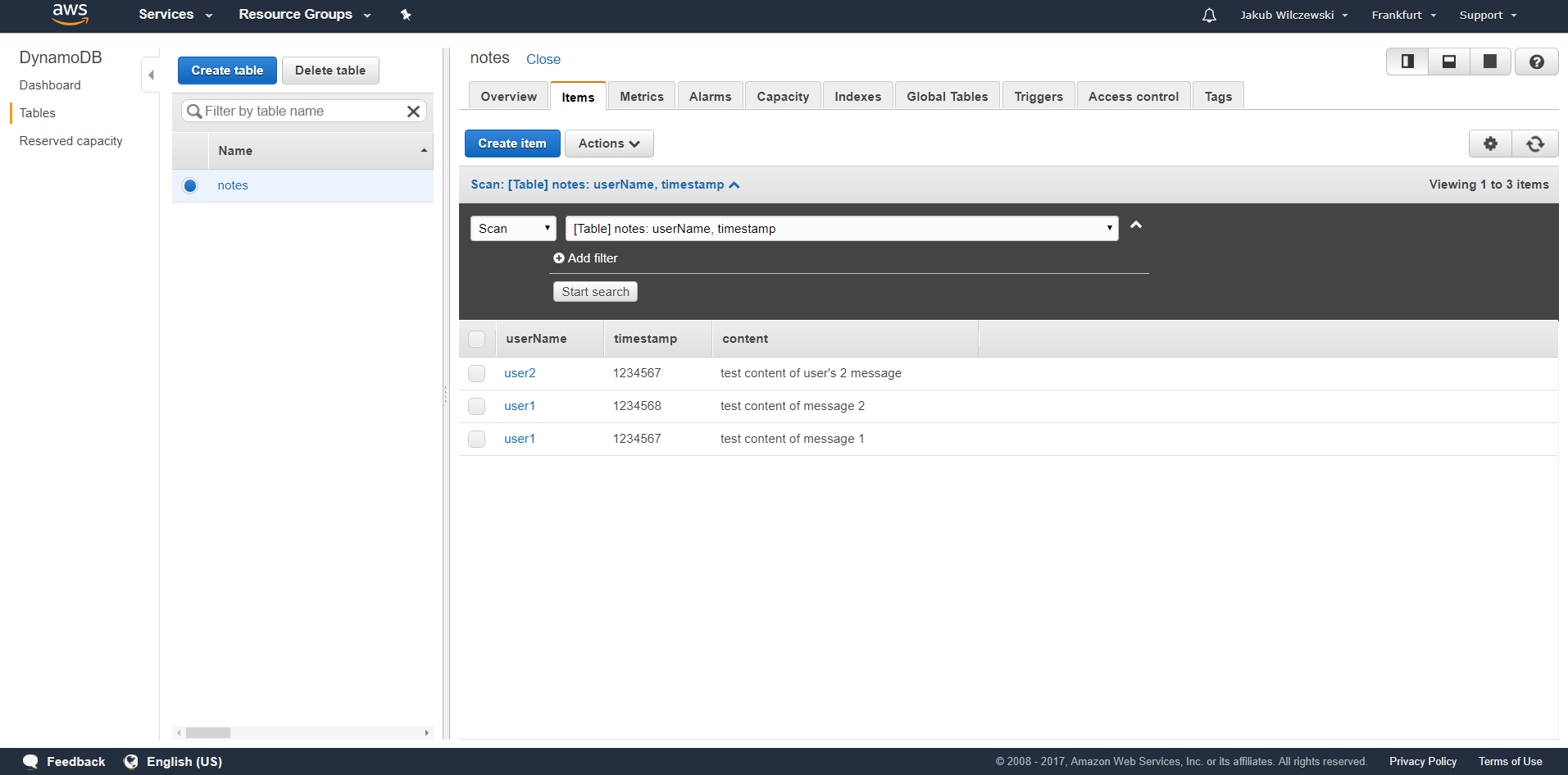
W tej chwili dodamy kilka rekordów do naszej tabeli, aby możliwe było przetestowanie funkcjonalności odczytu notatek. Przechodzimy na zakładkę items i klikamy przycisk “Create item”. Wpisujemy nazwę użytkownika oraz timestamp. Dodajemy również nową kolumnę o nazwie “content” i typie “String”:
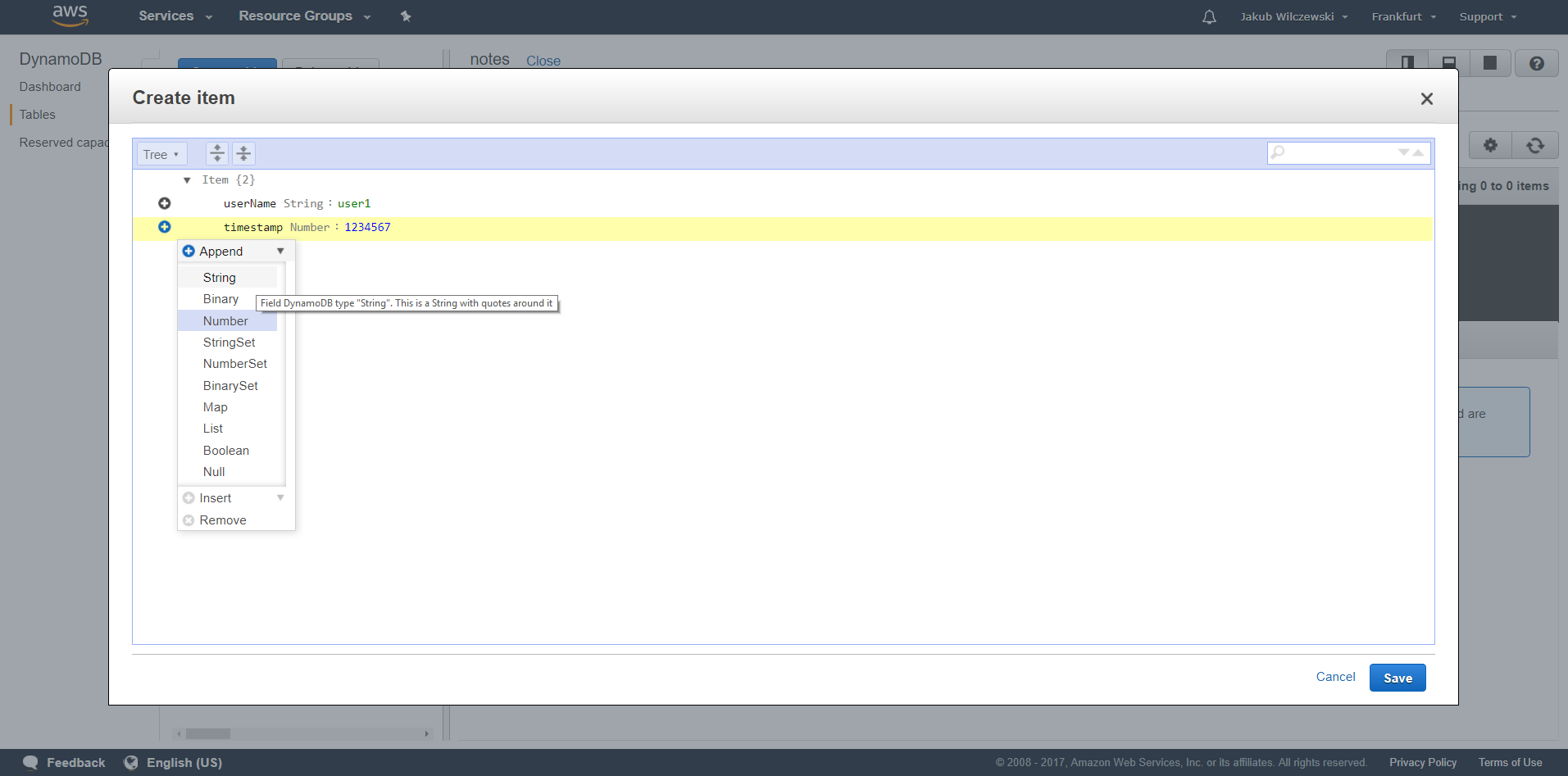
Wpisujemy przykładową treść notatki. Dodajmy jeszcze kilka przykładowych notatek:
Logika biznesowa
Warstwę persystencji mamy gotową, zajmiemy się teraz częścią biznesową. Zaimplementujemy ją w postaci lambd udostępnianych przez AWS. Wybieramy w lewym górnym rogu konsoli Services i przechodzimy do serwisu Lambda. Tutaj klikamy przycisk “Create a function” i przechodzimy do określania parametrów naszej lambdy. Określamy nazwę funkcji np.:”getNotes” oraz wybieramy język, w którym tworzona jest nasza funkcja. Do wyboru mamy C#, Javę 8, Node.js 4.3, Node.js 6.10, Python 2.7, Python 6.10. Wybieramy Node.js 6.10.
Za wyborem języka idą nie tylko określone cechy danego języka, ale także sposób jego działania w AWS. Przykładowo implementacja w Javie będzie zdecydowanie najszybciej działającym kodem na AWS, z drugiej jednak strony powołanie nowej instancji lambdy napisanej w Javie będzie trwało dość długo, bo aż kilka sekund. Przy założeniu, że nasz system będzie doświadczał peek’ów wywołań może to oznaczać, że w jednym momencie AWS będzie próbował zainstancjonować tysiąc (w zależności od liczby jednoczesnych wywołań) lambd w tym samym czasie, a dalej przełoży się to na kilkusekundowe opóźnienie w realizacji tych requestów. Będziemy musieli również ponieść koszt za czas jaki został poświęcony na wystartowanie każdej instancji lambdy. Analogiczny przypadek dla lambd zaimplementowanych w którymś z języków skryptowych może mymagać znacząco mniejszej liczby instancji, gdyż lambdy będą wcześniej dostępne do obsługi requestów (kilkaset milisekund w porównaniu do kilku sekund). Ciekawe porównianie szybkości działania dla poszczególnych języków można znaleźć na stronie: https://read.acloud.guru/comparing-aws-lambda-performance-when-using-node-js-java-c-or-python-281bef2c740f.
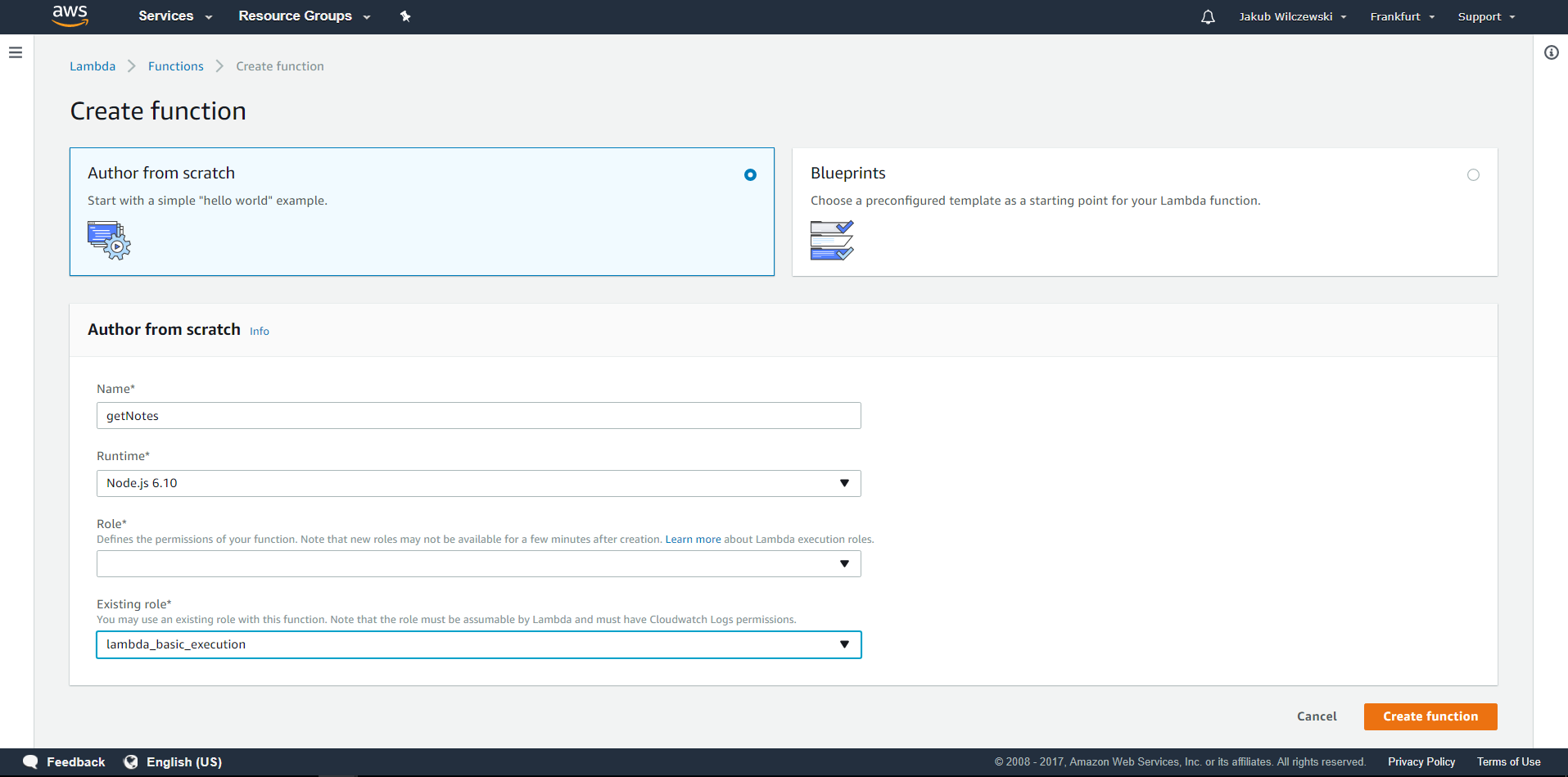
W polu Role wybieramy “Create a custom role” i przechodzimy do tworzenia nowej roli dla tworzonej przez nas lambdy. Rola ta będzie przydatna do definiowania uprawnień, które umożliwią lambdzie dostęp do różnych serwisów AWS. Pozostawiamy domyślnie wypełnione wartości i klikamy przycisk Allow. Następnie na ekranie tworzenia lambdy wybieramy w polu Existing role* utworzoną przez nas rolę, powinna to być rola o nazwie “lambda_basic_execution”:
Klikamy przycisk “Create function”. Funkcja zostaje utworzona, a my widzimy ekran konfiguracji utworzonej przez nas funkcji. W polu “Function code” znajduje się inline’owy edytor, w którym możemy edytować kod naszej lambdy.
Oczywiście tworzenie kodu w konsoli pozwala jedynie na tworzenie prostych funkcji. Bardziej skomplikowane lambdy tworzymy w zewnętrznych narzędziach i upload’ujemy w postaci archiwów zip. W polu “Code entry type” wybieramy “Upload a .ZIP file”.
Implementacja lambdy w Node.js 6.10 polega na implementacji trój-argumentowej funkcji. Pierwszy argument zawiera dane event’a, który uruchomił lambdę, drugi to informacje kontekstowe dot. środowiska uruchomieniowego, trzeci to metoda callbackowa pozwalająca na zwrócenie wyniku lub zaraportowanie błędu. Poniżej znajduje się kod lambdy umożliwiający pobieranie notatek z DynamoDB dla użytkownika przekazanego w argumencie event:
// dołączamy sdk AWS
const AWS = require('aws-sdk');
exports.handler = (event, context, callback) => {
console.log("event=", event);
// tworzymy instancję DocumentClient, która umożliwia zapytanie bazy danych
let documentClient = new AWS.DynamoDB.DocumentClient();
// definicja parmetrów zapytania do bazy danych
// szukamy rekordów, dla których userName jest równe userName przekazanemu w event
let params = {
TableName: 'notes',
KeyConditionExpression: 'userName = :userName',
ExpressionAttributeValues: {
':userName': event.userName
}
}
// wykonanie zapytania do bazy
documentClient.query(params, (err, data) => {
if (err) {
// w przypdaku błędu logujemy błąd i zwracamy błąd w funkcji callback
console.log(err);
callback(err);
} else {
// logujemy odpowiedź z bazy u zwracamy odpowiedź w funkcji callback
console.log(data);
callback(null, data);
}
});
};
Po dodaniu kodu określimy jeszcze kilka parametrów konfiguracyjnych lambdy. W polu “Basic setting” określamy timeout dla wywołania lambdy, warto zauważyć, że maksymalny timeout to 5 minut, co oznacza, że żadna lambda nie może wykonywać się dłużej niż 5 minut. Dodatkowo możemy określić rozmiar pamięci i co ciekawe przekłada się to również na moc procesora, którą dostanie nasza lambda (rozmiar pamięci przekłada się oczywiście na koszt usługi). W polu concurrency możemy określić maksymalną liczbę instancji naszej lambdy.
Ten wprowadzony niedawno parametr ma bardzo ważne znaczenie dla lambd napisanych w języku Java. Pozwala bowiem obejść problem uruchomienia bardzo dużej liczby instancji lambdy w przypadku peek’u - spowolni obsługę wszystkich requestów (co i tak by nastąpiło ze względu na długi czas tworzenia nowej instancji lambdy w Javie), ale jednocześnie pozwoli na zmniejszenie kosztów usługi - następne wywołania będą już działały na zainstancjonowanych lambdach i będą szybkie.
Zapisujemy lambdę przyciskiem “Save”. Teraz możemy przetestować napisany przez nas kod. Klikamy przycisk “Test” i definiujemy json’a, który zostanie przekazany w evencie podczas uruchamiania naszej lambdy.
{
"userName": "user1"
}
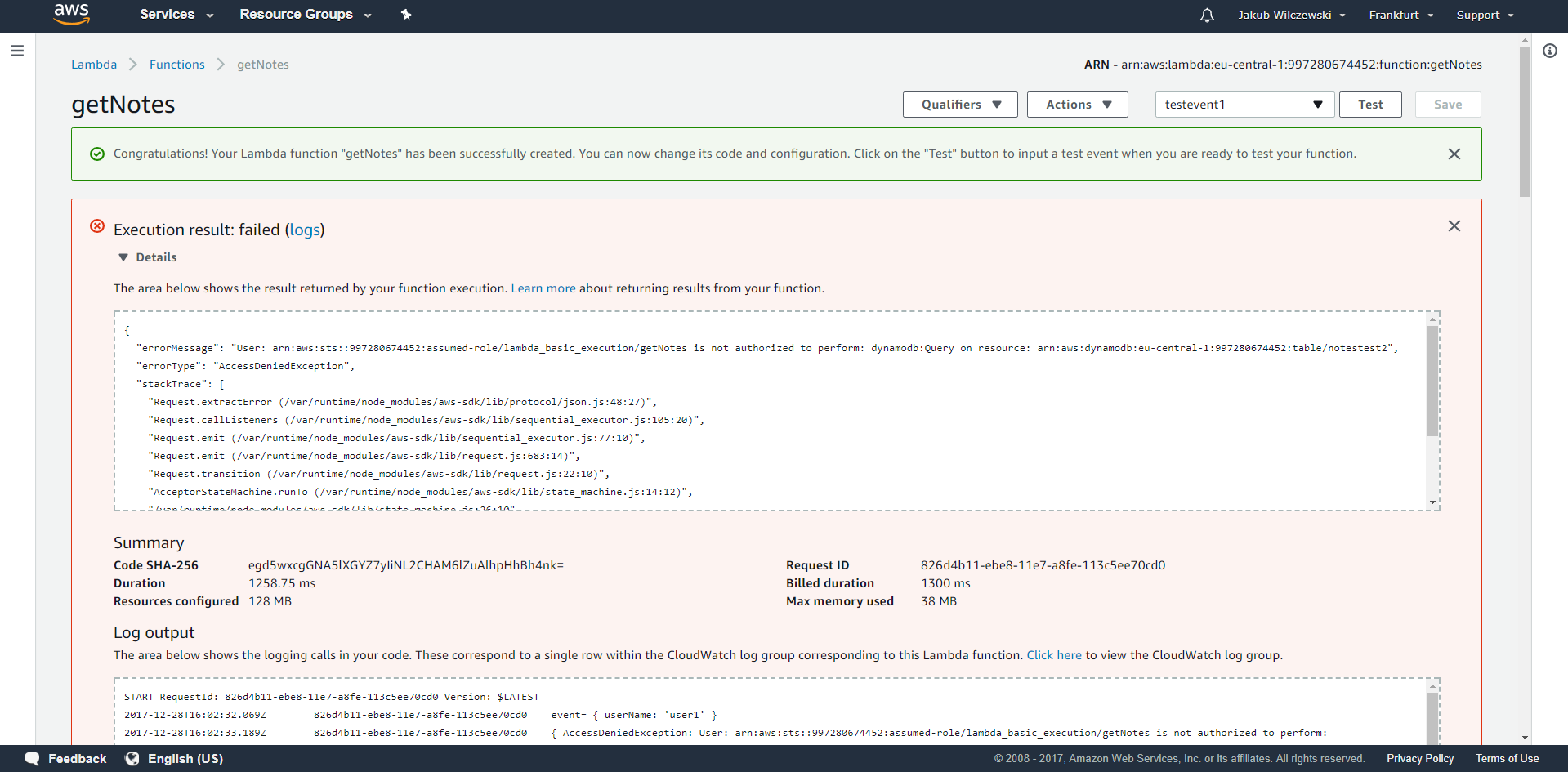
Po uruchomieniu testu powinniśmy otrzymać błąd oznaczający brak autoryzacji zdefiniowanej przez nas lambdy do odczytu danych z bazy DynamoDB:
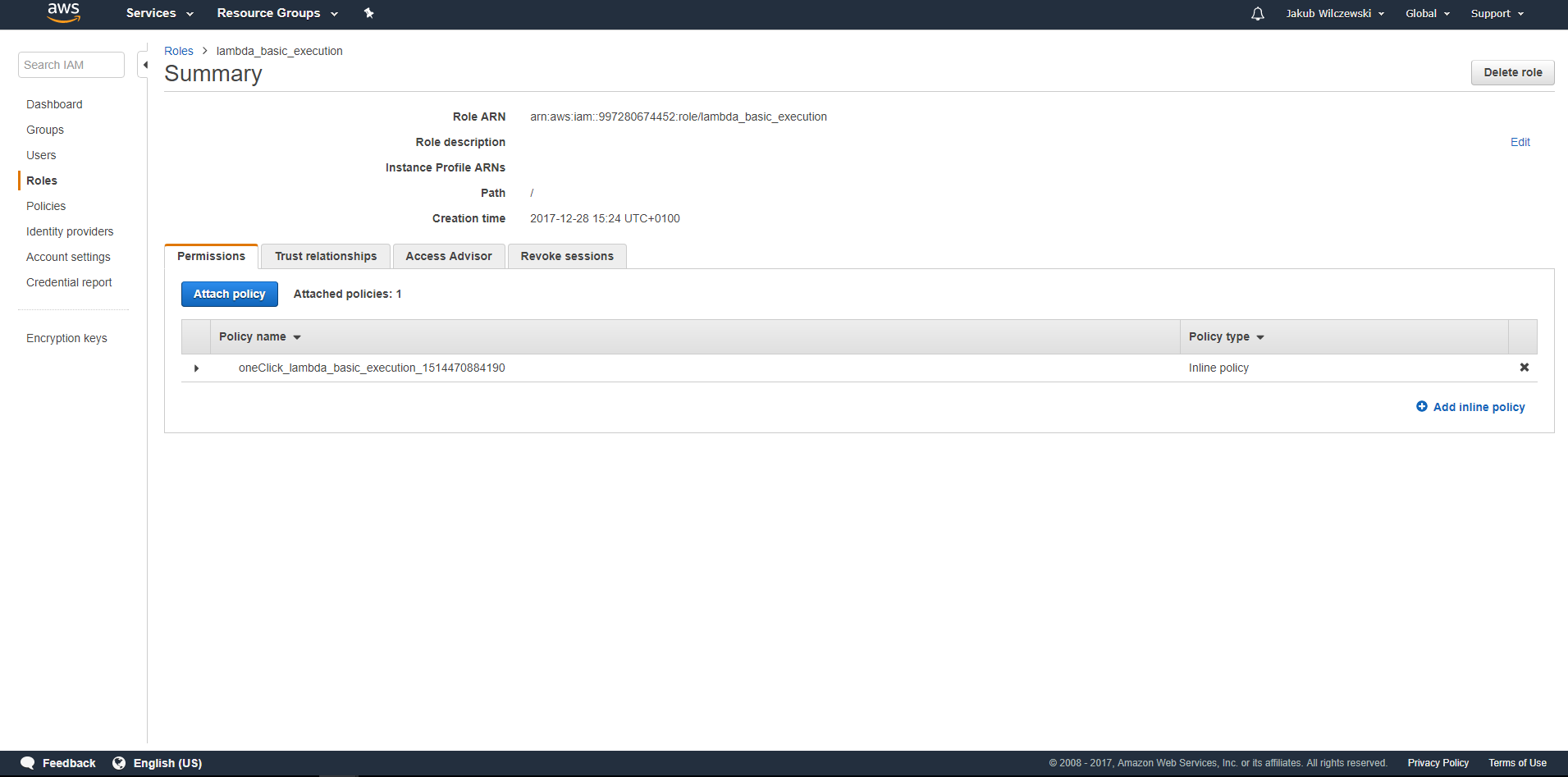
Aby nadać odpowiednie uprawnienia musimy przejść do usługi IAM (Services->IAM). Wybrać z menu po lewej stronie “Roles”, a następnie wybrać rolę, którą zdefiniowaliśmy podczas tworzenia lambdy (lambda_basic_execution). Klikamy przycisk “Attach policy”:
W polu wyszukiwania “policy type” wpisujemy DynamoDB i po wyszukaniu dołączamy policy “AmazonDynamoDBFullAccess”:
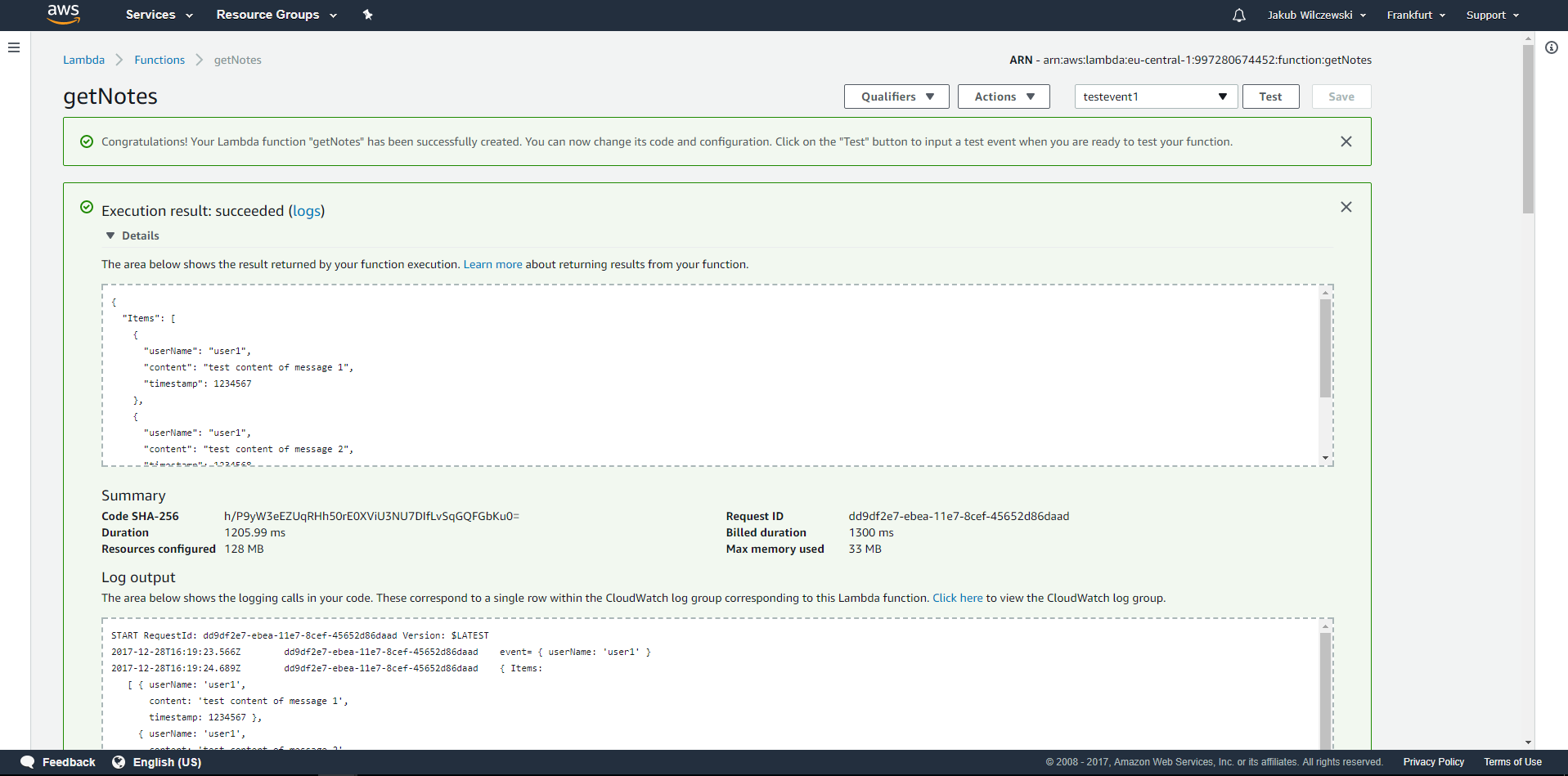
Po ponownym wywołaniu testu lambdy powinniśmy otrzymać w wyniku dane pobrane z bazy DanamoDB:
Rest API
Pozostaje nam udostępnienie naszego serwisu do notatek w formie API restowego. Komponent AWS, który umożliwi nam zrobienie tego to API Gateway. W konsoli AWS przechodzimy do Serices->API Gateway i po załadowaniu strony klikamy przycisk “Get started”. W polu wyboru wybieramy New API i wpisujemy nazwę np.: “notes”:
Klikamy przycik “Create API”. W polu “Actions” wybieramy “Create Resource”:
W polu “Resource Name” wpisujemy “userName”, a w “Resource Path” “{username}”:
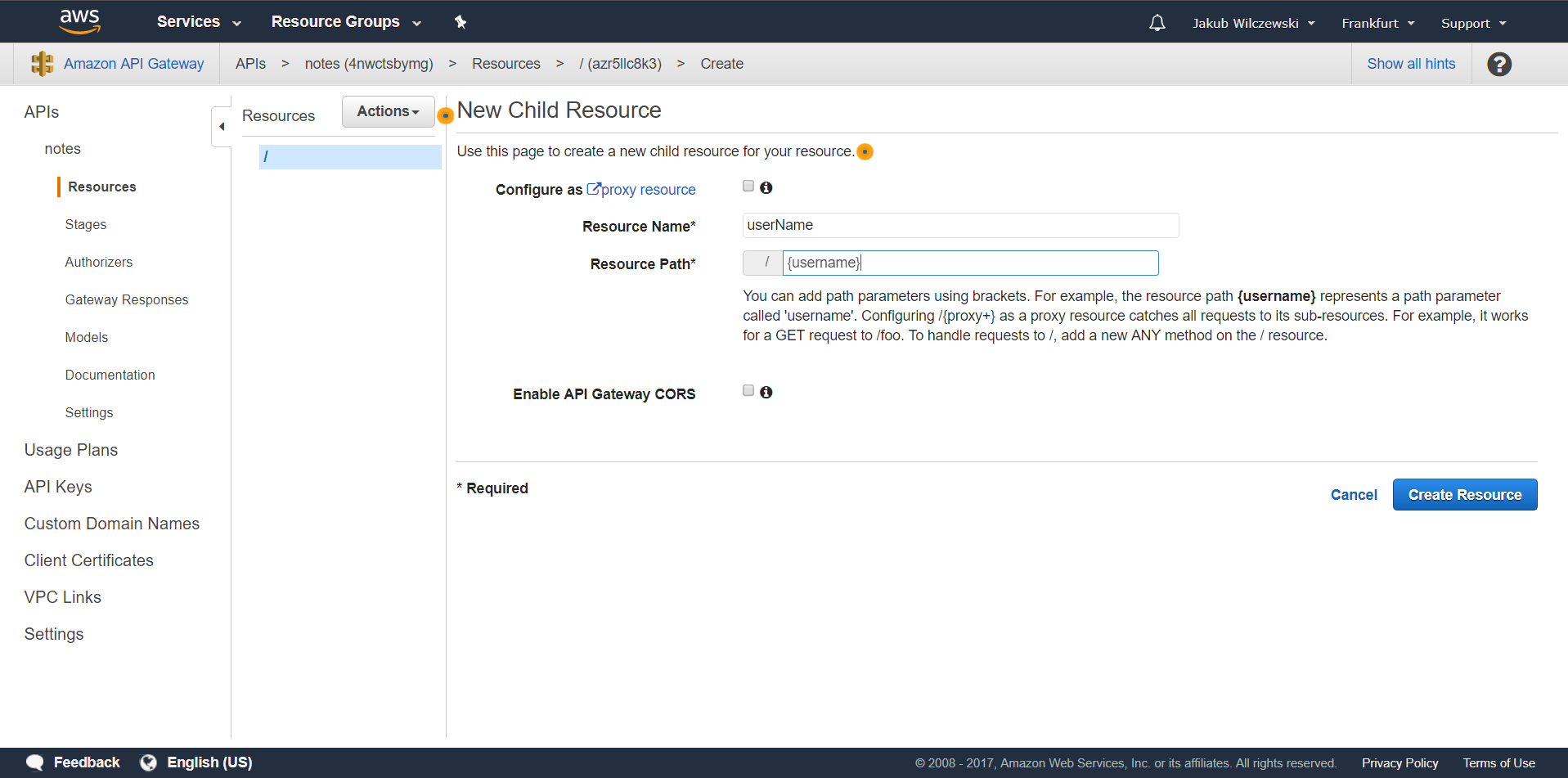
Klikamy przycisk “Create Resource”. Będąc na nowoutworzonym resource z menu “Actions” wybieramy “Create Method”:
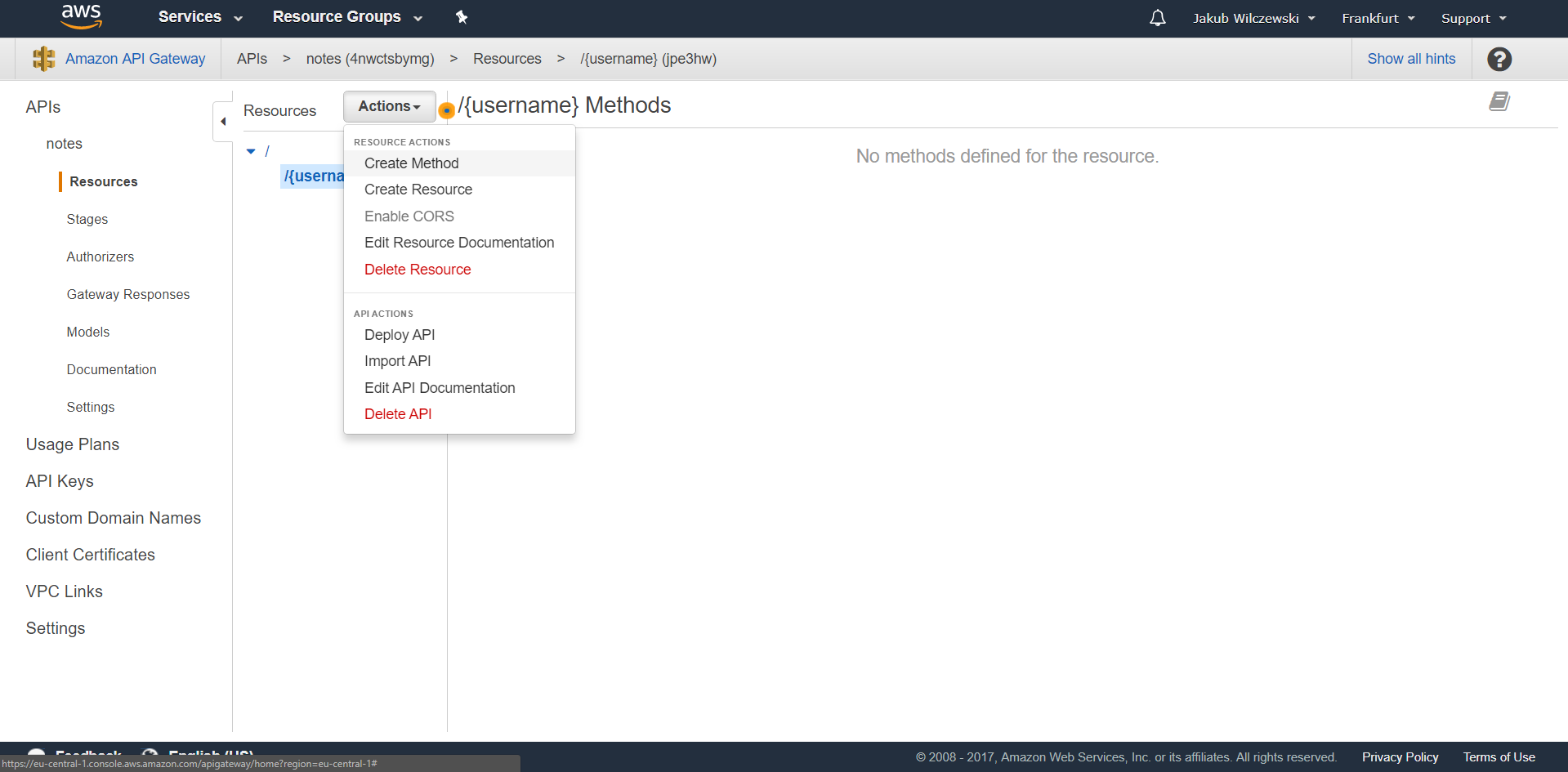
Z listy rozwijanej wybieramy metodę GET i zatwierdzamy:
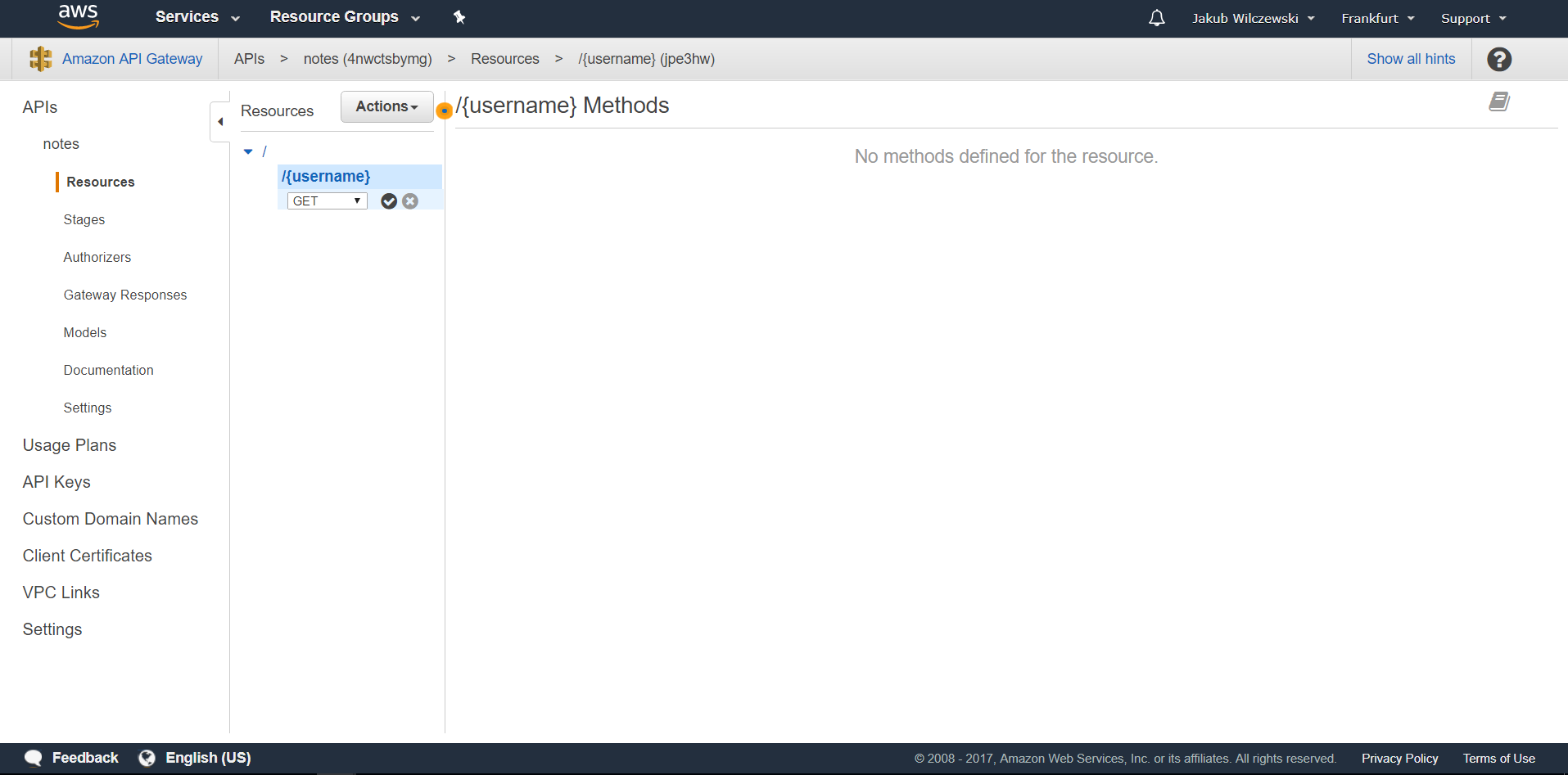
W polu wyboru “Integration type” wybieramy “Lambda function”. Poniżej w polu “Lambda region” wybieramy region, w którym utworzyliśmy lambdę getNotes. W polu “Lambda Function” podajemy nazwę funkcji np.: “getNotes” (po wpisaniu pierwszej litery nazwa powinna się podpowiedzieć):
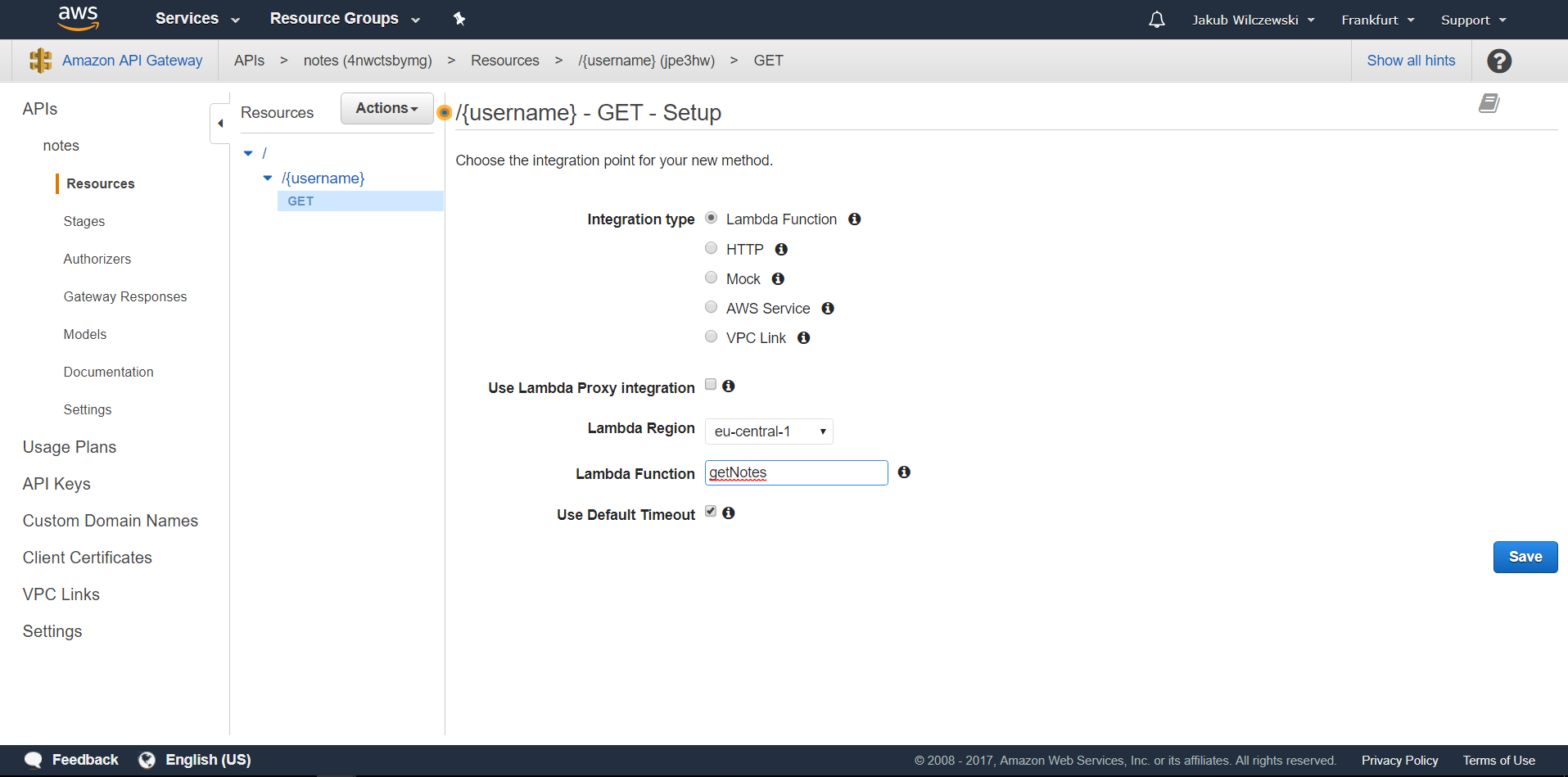
Klikamy przycisk “Save” i zatwierdzamy nadanie uprawnienia wykonywania lambdy (popup). Ponieważ chcemy, aby nazwa użytkownika, dla którego chcemy pobrać notatki przekazywana była w ścieżce potrzebujemy jeszcze dodatkowej konfiguracji. Kliknij na link “Integration Request”. Rozwiń “URL Path Parameters” i kliknij “Add path”. W polu name wpisz “username”, w “mapped from” “method.request.path.username” i zatwierdź:
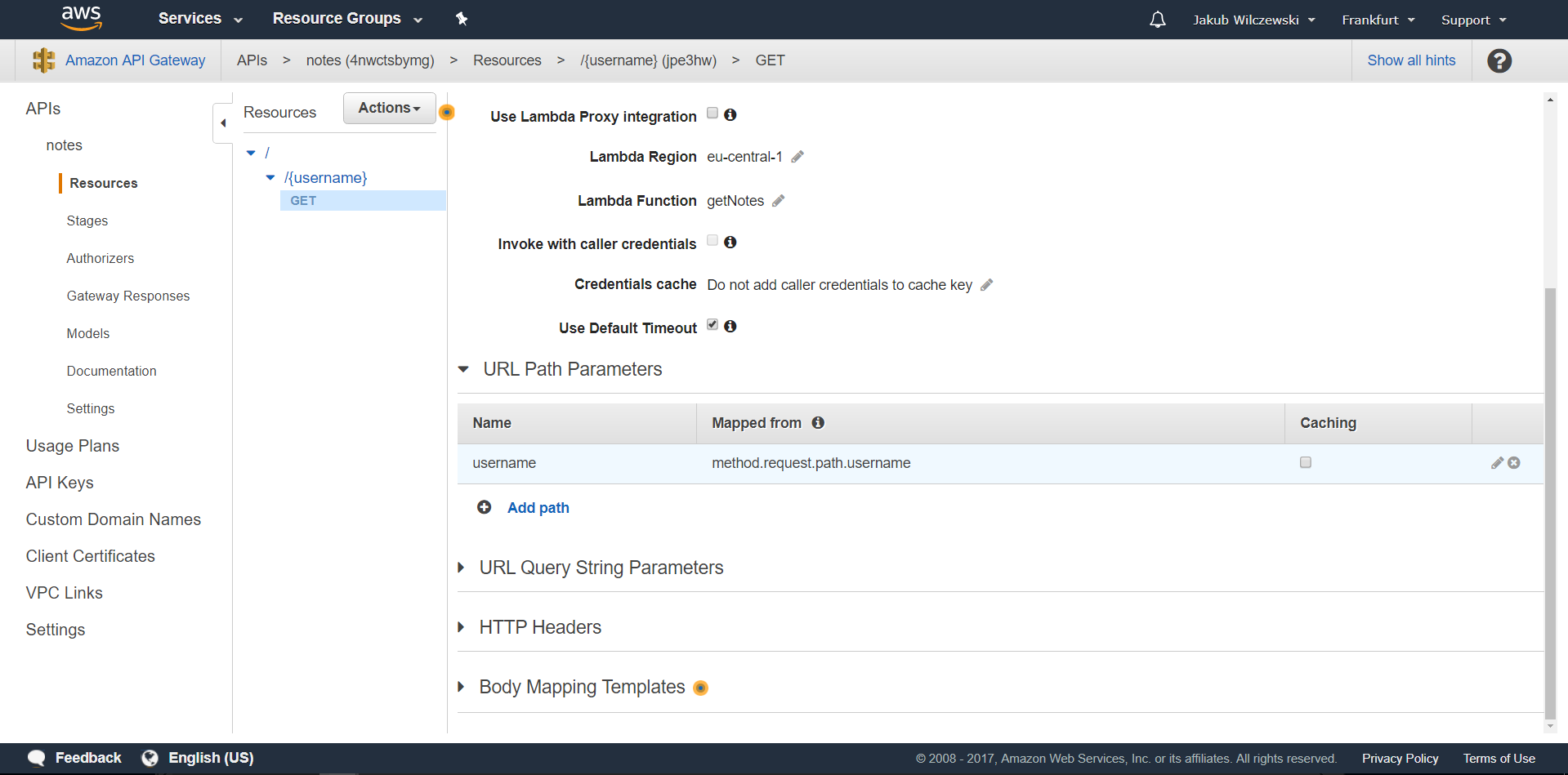
Rozwiń “Body Mapping Templates” i kliknij “Add mapping template”. W polu “Content-Type” wpisz “application/json” i zatwierdź. W polu edycji dodaj mapowanie:
{
"userName": "$input.params('username')"
}
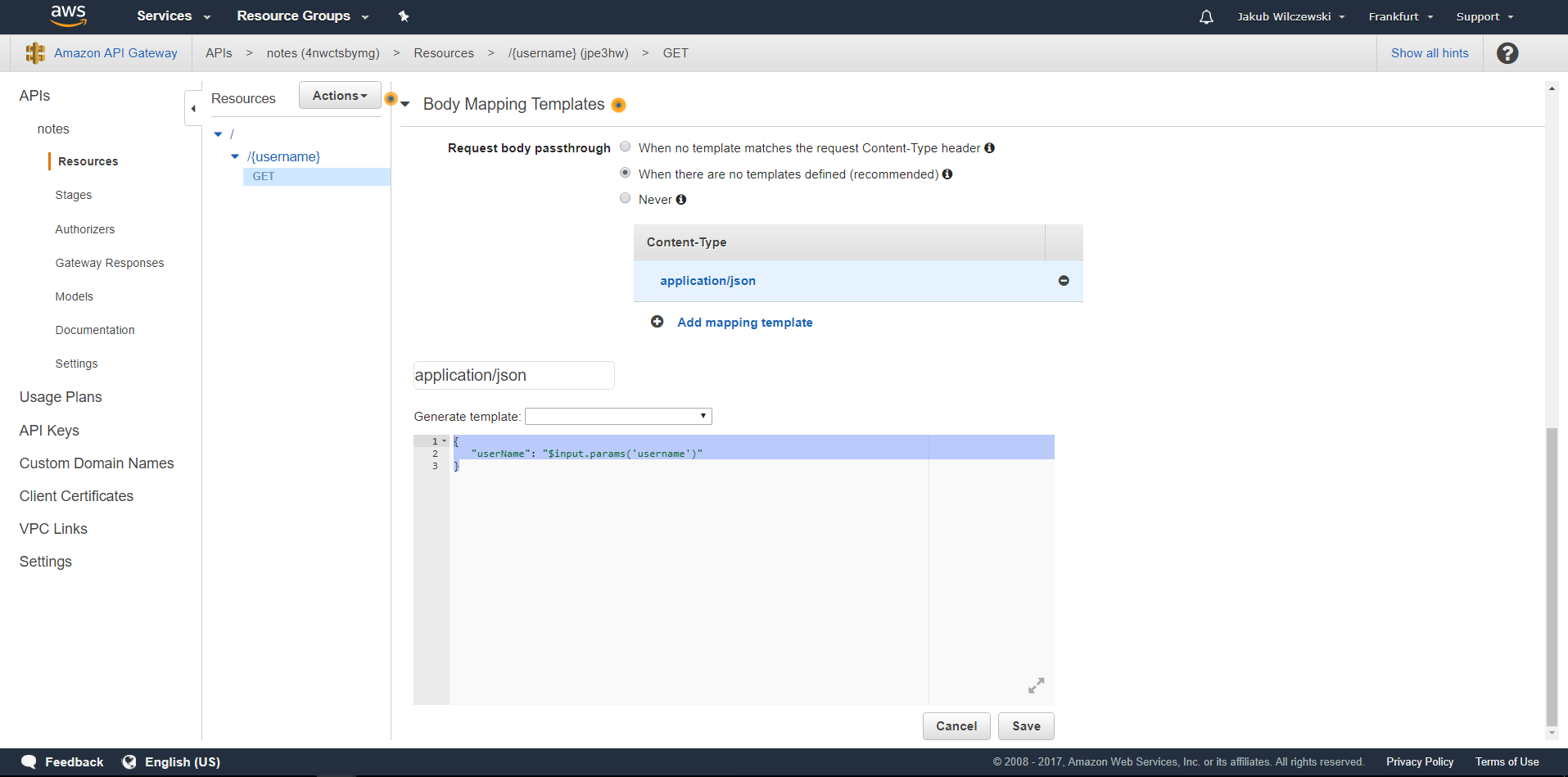
Zapisz mapowanie przyciskiem “Save”.
Kliknij w drzewie “Resources” metodę “GET”. Po prawej stronie powinien pojawić się przepływ danych łączący API Gateway i lambdę. Kliknij przycisk “Test” aby przetestować konfigurację API Gateway. Jako parametr “{username}” podaj “user1” i kliknij przycisk “Test”:
API Gateway powinno zwrócić notatki znajdujące się w bazie danych DynamoDB:
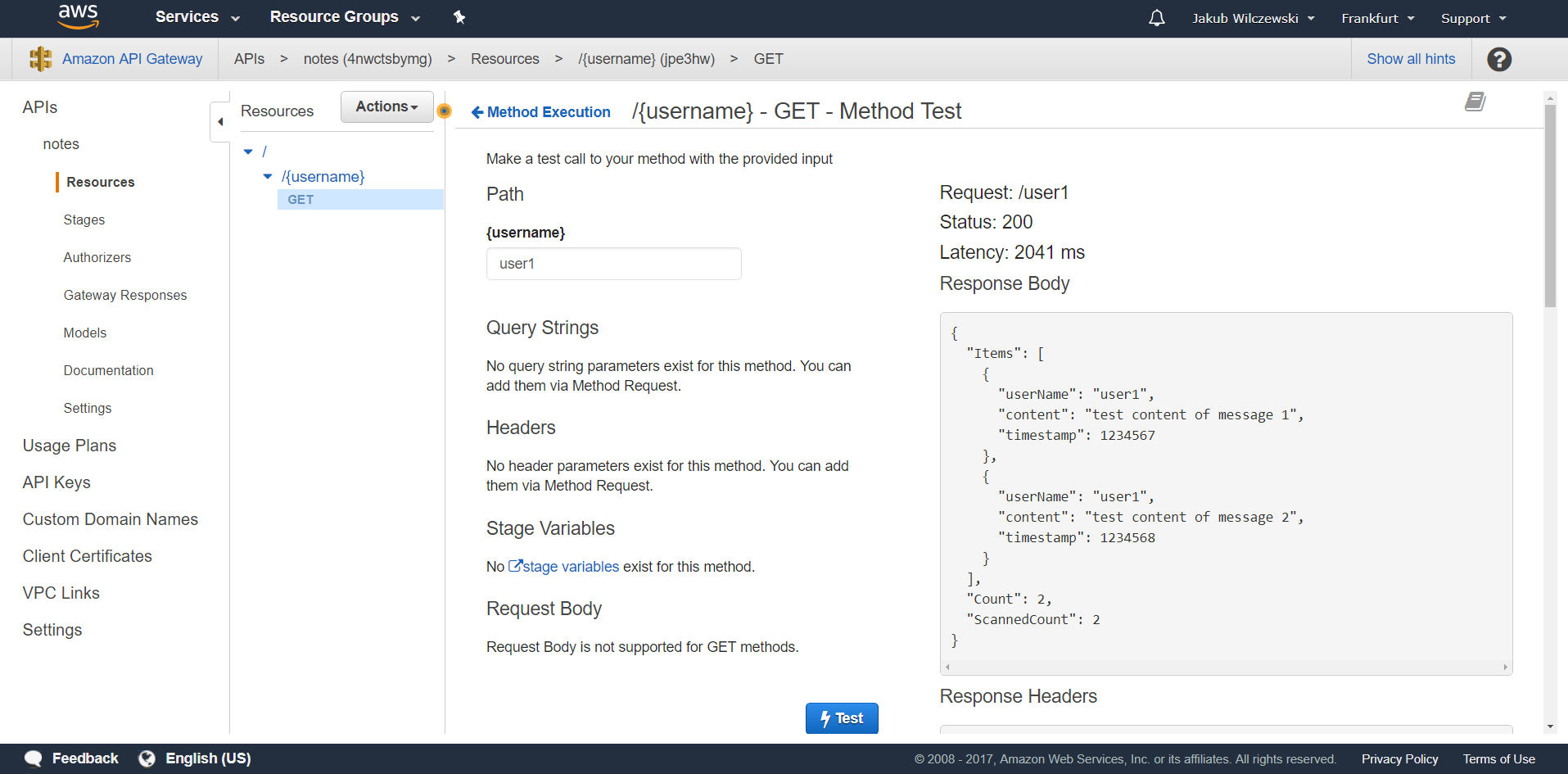
Aby wystawić naszą usługę na świat musimy jeszcze wdrożyć konfigurację API Gateway. W tym celu z menu “Actions” wybieramy “Deploy API”. W polu “Deployment stage” wybieramy “[New Stage]”, w polu “Stage name” wpisujemy nazwę naszego środowiska np.: “test” i klikamy przycisk “Deploy”:
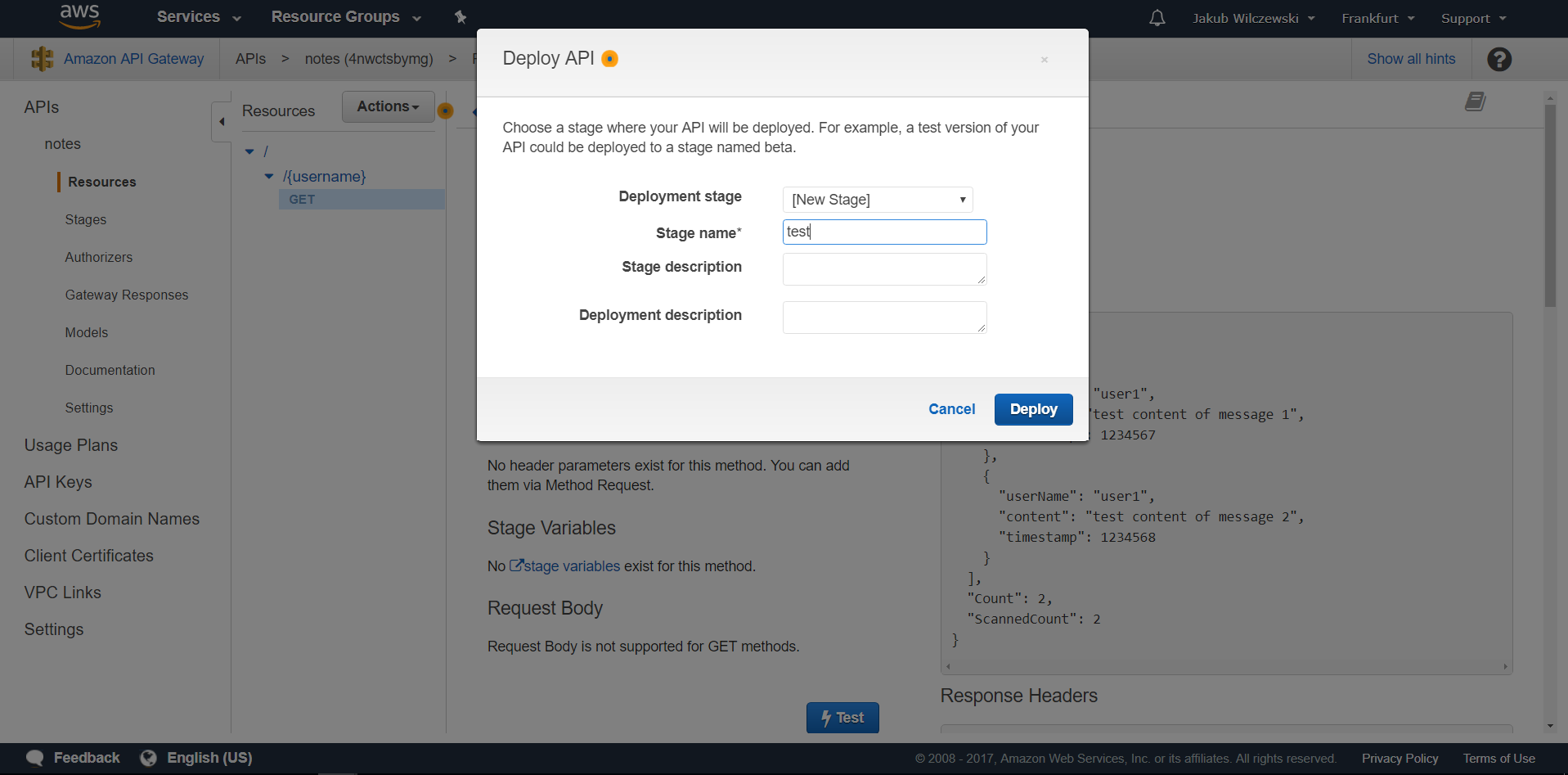
Od tej chwili nasz serwis dostępny jest w sieci. Aktualnie nie jest on niczym zabezpieczony, więc każdy znający jego adres może go wywołać. Aby sprawdzić działanie z zewnętrznej aplikacji, przechodzimy na zakładkę “Export” i pobieramy json’a dla postmana:
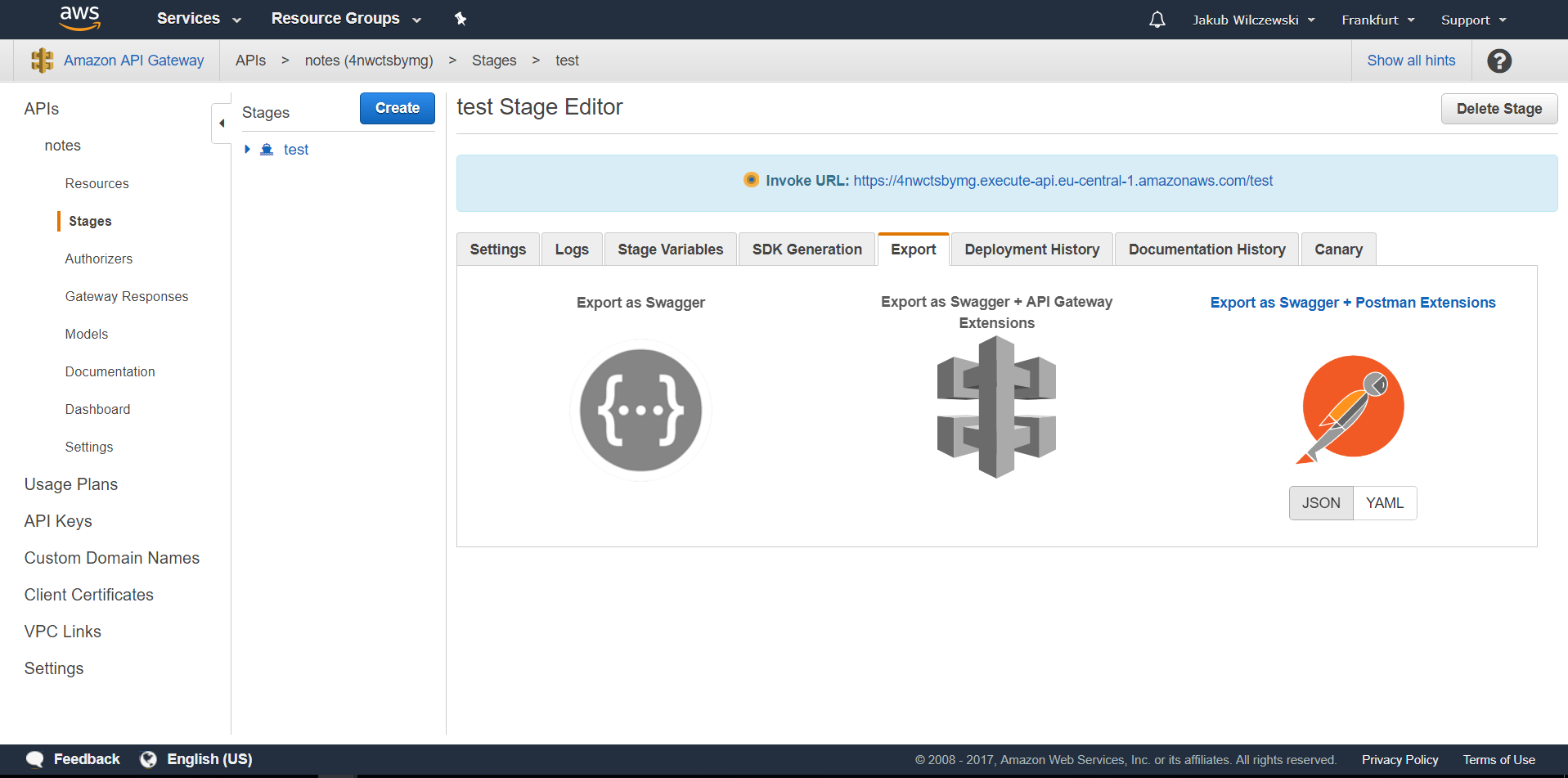
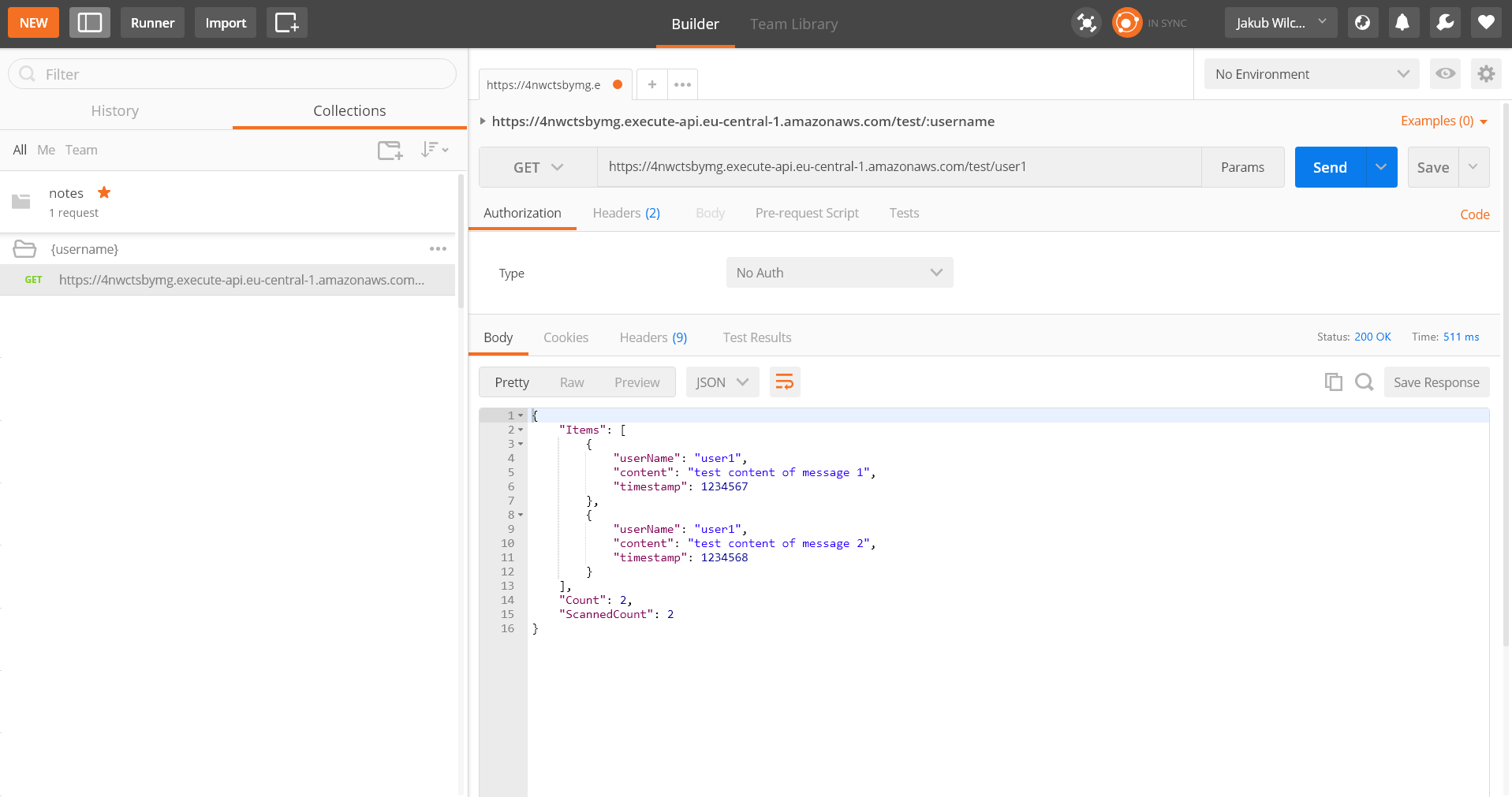
Pobraną kolekcję importujemy do Postmana. W ścieżce wywołania zamieniamy “:username” na faktyczną nazwę użytkownika i wysyłamy żądanie. W odpowiedzi powinniśmy dostać dane z bazy DynamoDB:
Dostęp do logów możliwy jest za pomocą serwisu CloudWatch. Aby dotrzeć do logów konkretnej lambdy należy wejść na jej konfigurację, np.: Lambda->Functions->getNotes i przejść na zakładkę “Monitoring”. Dalej na jednym z paneli klikamy link “Jump to Logs”. W to samo miejsce możemy również dotrzeć z poziomu serwisów: Services->CloudWatch->Logs.
Implementacja zapisu notatek
Warstwę persystencji mamy już przygotowaną i ona nie wymaga żadnych modyfikacji. Aby umożliwić zapis notatek, musimy zaimplementować dodatkową lambdę. Tworzymy ją w taki sam sposób jak lambdę do odczytu podając inną nazwę, np.: addNote i wybierając utworzoną wcześniej rolę “lambda_basic_execution”. Kod lambdy powinien wyglądać mniej więcej tak:
const AWS = require('aws-sdk');
exports.handler = (event, context, callback) => {
console.log("event=", event);
// tworzymy instancję DocumentClient, która umożliwia wstawienie do bazy danych
let documentClient = new AWS.DynamoDB.DocumentClient();
// definicja parmetrów wstawienia do bazy
// nazwę użytkownika i treść notatki pobieramy z przekazanego event'a
let params = {
TableName: 'notes',
Item: {
userName: event.userName,
timestamp: Date.now(),
content: event.content
}
}
// próba wstawienia do bazy
documentClient.put(params, (err, data) => {
if (err) {
console.log(err);
callback(err);
} else {
console.log(data);
callback(null, data);
}
});
};
Aby przetestować lambdę definiujemy nowy event testowy w formie json’a:
{
"userName": "user1",
"content": "nowo dodana notatka"
}
i klikamy przycisk test. Notatka powinna być zwrócona podczas pobierania notatek użytkownika “user1”.
Pozostaje jeszcze konfiguracja API Gateway. W tym celu wchodzimy na Services->API Gateway i odnajdujemy utworzone wcześniej API “notes”. W drzewie “Resources” wybieramy “/” i w menu “Actions” wybieramy akcję “Create Method”.
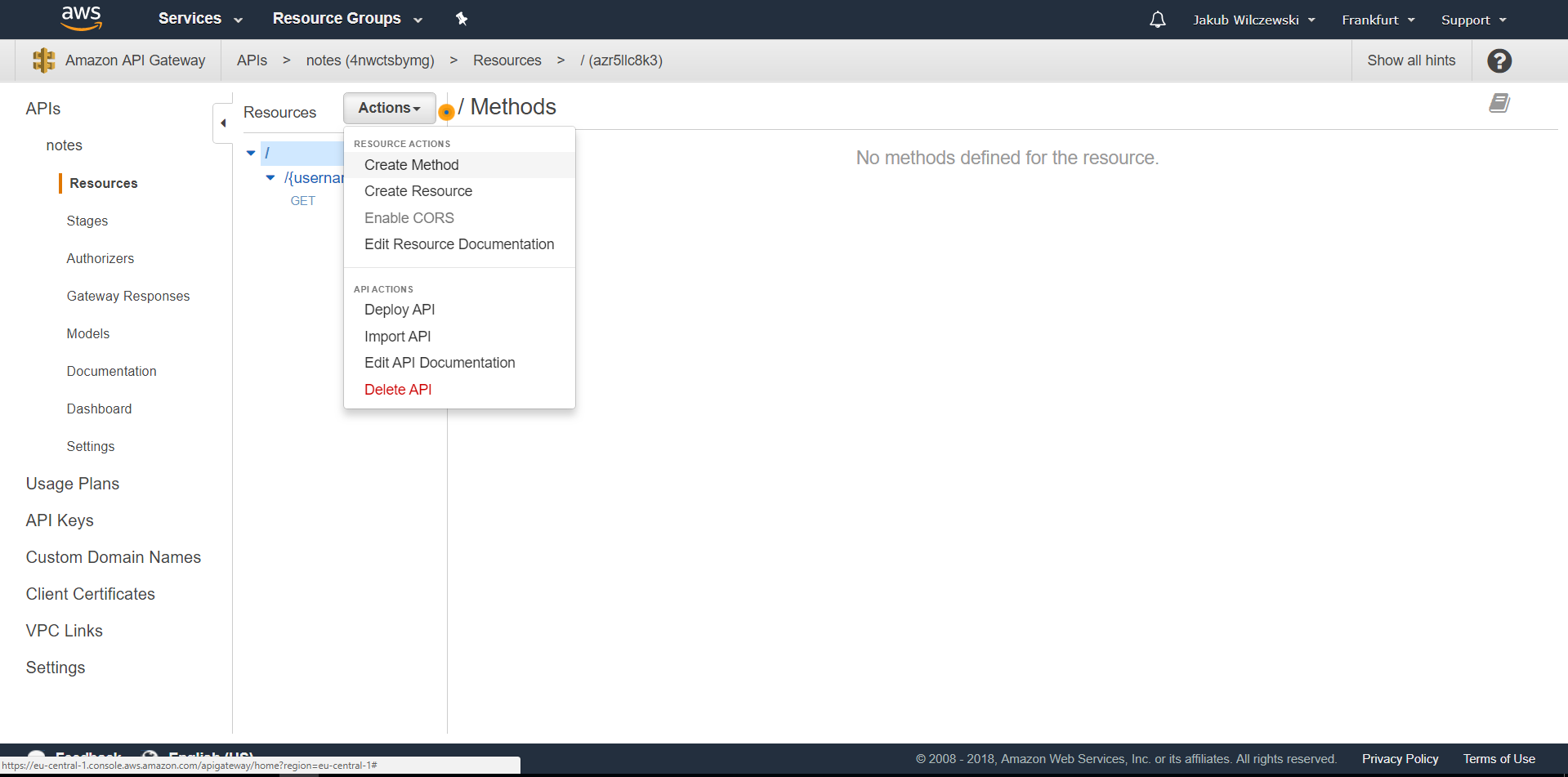
Z listy metod wybierramy “POST” i zatwierdzamy wybór. W polu “Integration type” wybieramy “Lambda Function”. Określamy region naszej lambdy i podajemy jej nazwę w polu “Lambda Function”:
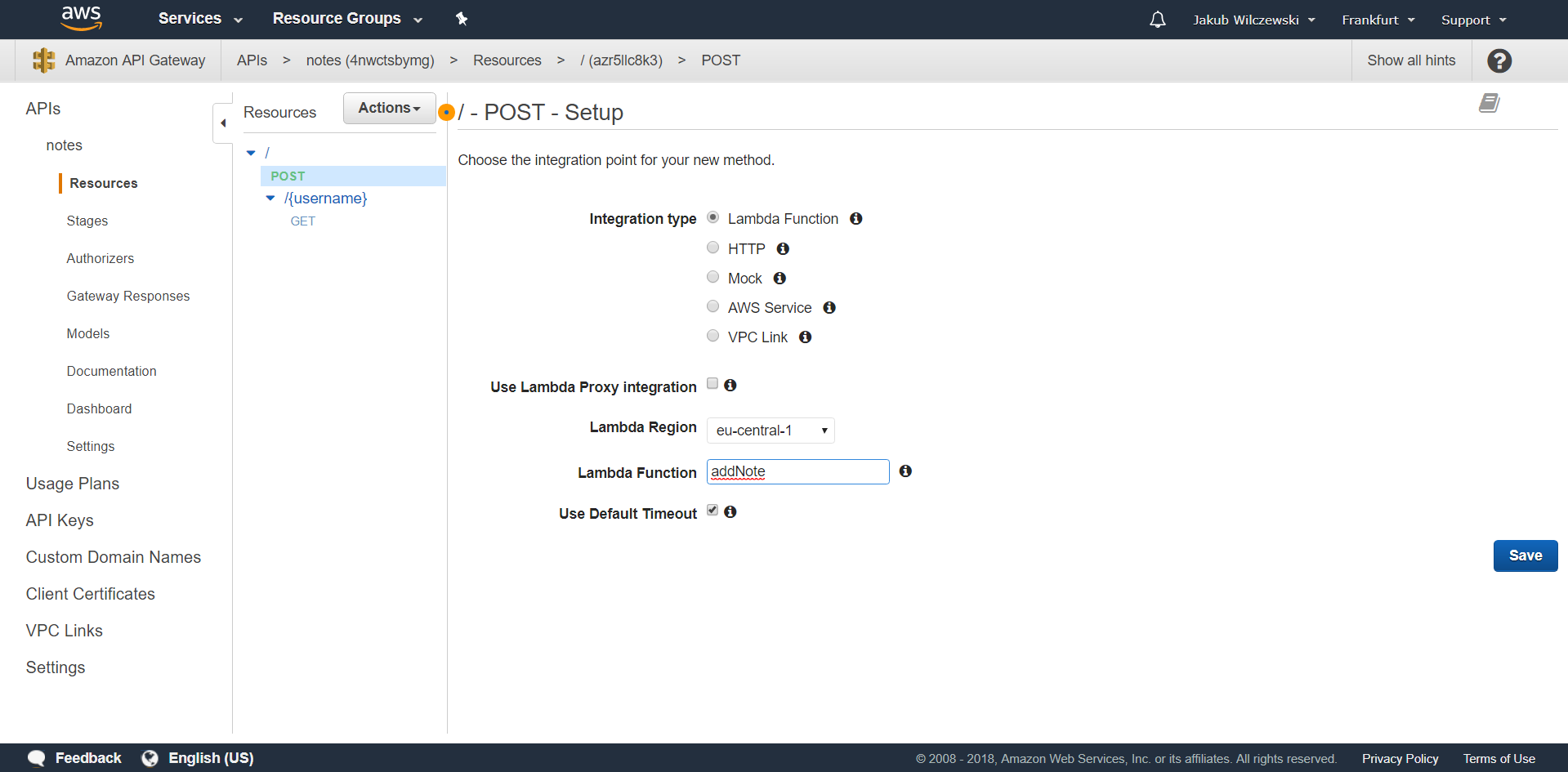
Klikamy przycisk “Save” i zatwierdzamy dodanie uprawnienia do funkcji. I to tyle z konfiguracji API Gateway. Podobnie jak w przypadku odczytu również na zapisie możemy przetestować konfigurację API Gateway. Klikamy przycisk “Test” i w polu “Request Body” podajemy treść eventa:
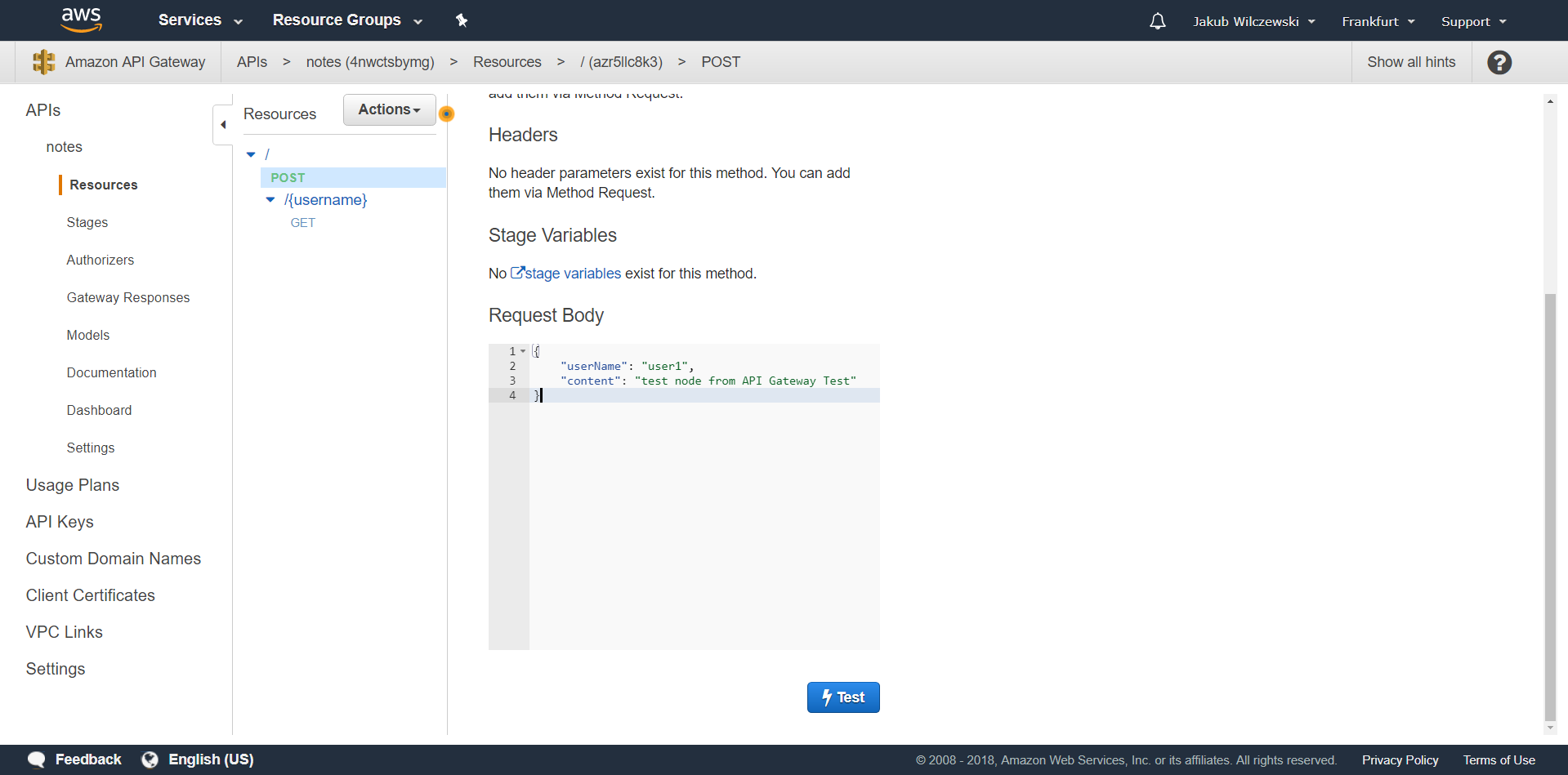
W odpowiedzi powinniśmy otrzymać status http 200, a nowododana notatka powinna być widoczna w pobieranych notatkach użytkownika “user1”. Aby nowa metoda była dostępna z zewnątrz, należy zdeployować jeszcze raz nasze api wybierając z menu “Actions” “Deploy API” i podać utworzony wcześniej stage “test”. Teraz ponownie możemy wyeksportować konfigurację do postmana i wykonać test:
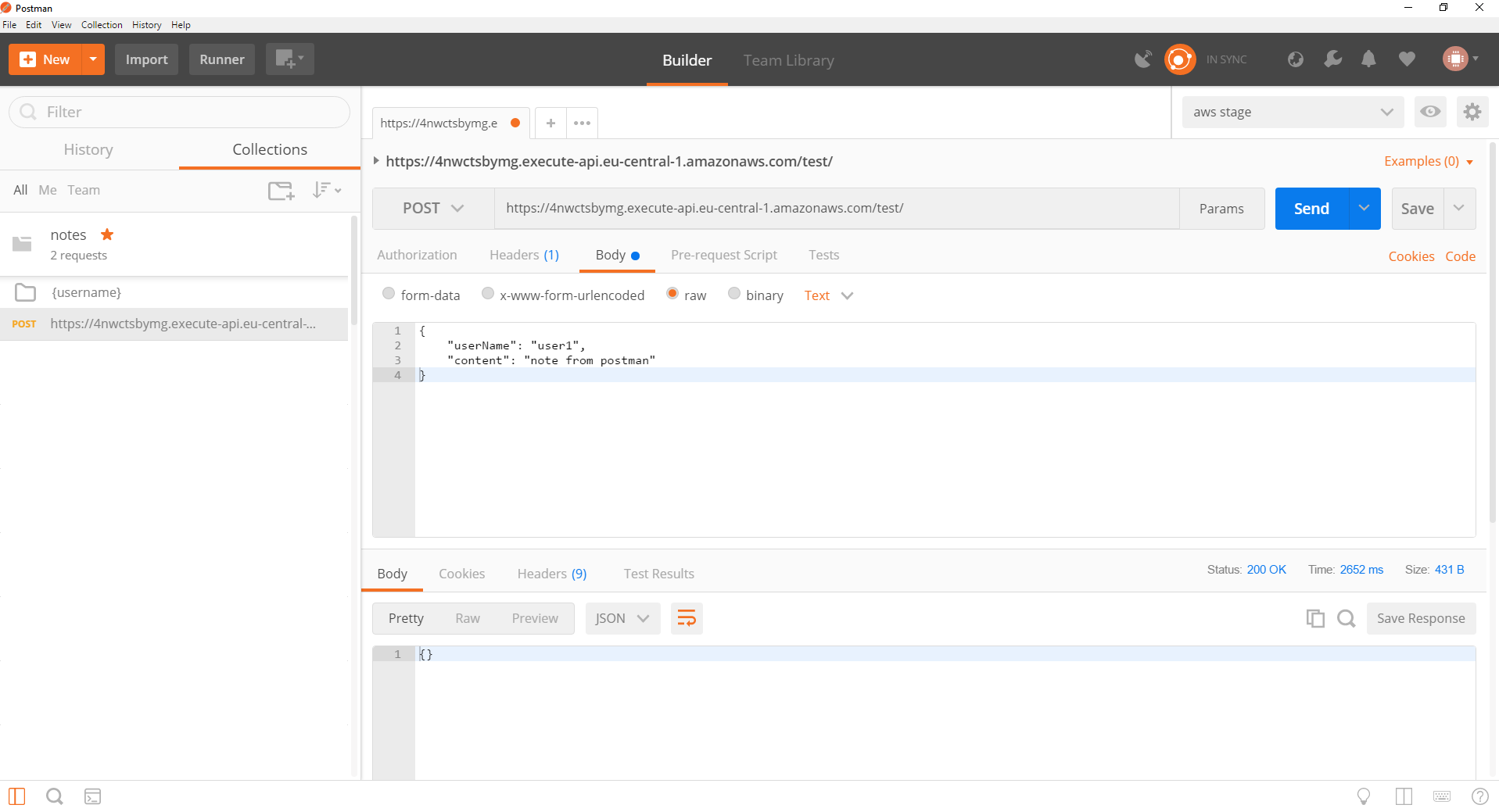
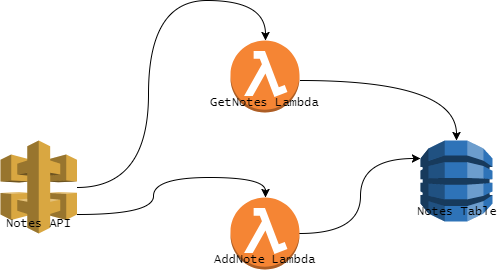
Diagram użytych przez nas komponentów AWS wygląda następująco:
Ile to kosztuje
Praca w cloudzie AWS daje nam możliwość dokładnego policzenia kosztów naszego rozwiązania. Trzeba przy tym pamiętać również o tym, że AWS daje nam tzw. “Free tier” czyli pewną pulę zasobów, która jest dostępna bezkosztowo.
Koszty DynamoDB
I tak zaczynając od warstwy persystencji na koszty DynamoDB składają się koszty przestrzeni, które zajmują dane oraz koszty operacji odczytu i zapisu wykonywane w jednostce czasu. Przy kosztach zapisu i odczytu AWS posługuje się jednostkami:
- RCU (read capacity unit) - jeden RCU umożliwia wykonywanie dwóch odczytów na sekundę,
- WCU (write capacity unit) - jeden WCU umożliwia wykonywanie jednego zapisu na sekundę.
Jeżeli nasza aplikacja obsługuje ruch, w którym maksymalnie wykonywane są 2 odczyty na sekundę przez cały czas jej działania to AWS naliczy opłatę za 1 RCU.
W przypadku DynamoDB Free Tier wynosi:
- 25 RCU,
- 25 WCU,
- 25 GB zaindeksowanych danych. Oznacza to, że aplikacja generująca 25 zapisów na sekundę i 50 odczytów na sekundę, której dane mieszczą się w 25 GB nie generuje kosztów. Free tier dla DynamoDB jest stały, nie ma ograniczenia czasowego. Po przekroczeniu wartości Free tier koszt wynosi odpowiednio:
- 1 RCU: $0.09 miesięcznie,
- 1 WCU: $0.47 miesięcznie,
- 1 GB: $0.25 miesięcznie. Szczegóły naliczania kosztów dla DynamoDB można znaleźć na stronie https://aws.amazon.com/dynamodb/pricing/.
Koszty Lambdy
W przypadku lambd płacimy za liczbę wykonanych żądań oraz za tzw. gigabajto-sekundy (GB-seconds). W konfiguracji lambdy możemy określić ile maksymalnie pamięci chcemy jej przydzielić. Minimalnie to 128 MB, maksimum 3008 MB. Liczbę GB-s zużytych przez lambdę określamy jako: -liczba skonfigurowanej pamięci w MB / 1024 * czas wykonania lambdy w sekundach (zaokrąglony do 100 ms w górę).
Czas wykonania lambdy, za który AWS naliczy nam opłatę jest zawsze podawany w logu po wykonaniu danej lambdy, np.:
REPORT RequestId: 31aaeaec-ef26-11e7-9892-57823db0c303 Duration: 316.42 ms Billed Duration: 400 ms Memory Size: 128 MB Max Memory Used: 34 MB
W tym przypadku nasza lambda zużyła 128/1024 GB * 0.4 s = 0.125 GB * 0.4 s = 0.05 GB-s. Free tier dla lambd wynosi:
- 1 000 000 żądań miesięcznie,
- 400 000 GB-s miesięcznie.
Po przekroczeniu tych wartości płacimy:
- za każde 1 000 000 żądań $0.20,
- za 1 GB-s $0.00001667. Szczegóły możemy znaleźć na stronie https://aws.amazon.com/lambda/pricing/.
Koszty API-Gateway
Zdecydowanie najdroższym komponentem, którego użyliśmy w naszym przykładzie jest API-Gateway. W tym przypadku płacimy za liczbę żądań oraz dane, które transferujemy przez api. Warstwa darmowa obejmuje 1 000 000 żądań miesięcznie, ale jest dostępna przez pierwsze 12 miesięcy używania API-Gateway. Po tym czasie koszty wyglądają następująco:
- 1 000 000 żądań: $3.70,
- pierwsze 10 TB transferowanych danych $0.09 za 1 GB,
- kolejne 40 TB transferowanych danych $0.085 za 1 GB,
- kolejne 100 TB transferowanych danych $0.07 za 1 GB,
- kolejne 350 TB transferowanych danych $0.05 za 1 GB. Szczegóły dot. kosztów API-Gateway dostępne są na stronie https://aws.amazon.com/api-gateway/pricing/.
Koszty przykładowej aplikacji
Proponuję teraz ćwiczenie polegające na policzeniu kosztów przygotowanej przez nas aplikacji. Załóżmy, że chcemy obsługiwać milion użytkowników i każdy z nich będzie zapisywał 10 notatek dziennie i odczytywał 30. Zakładamy że jedna notatka ma wielkość 1 KB.
Koszty DynamoDB
Mamy więc 1 000 000 użytkowników zapisujących 10 notatek każdego dnia. Policzmy ile zapisów na sekundę potrzebujemy:
- 1 000 000 użytkowników * 10 notatek * 31 dni = 310 000 000 zapisywanych notatek miesięcznie,
- 310 000 000 / (31 dni * 24h * 60m * 60s) = 310 000 000 / 2678400s = 116 zapisów na sekundę, czyli potrzebujemy 116 WCU.
Każdy z użytkowników odczytuje 30 notatek każdego dnia:
- 1 000 000 użytkowników * 30 notatek * 31 dni = 930 000 000 odczytywanych notatek miesięcznie,
- 930 000 000 / (31 dni * 24h * 60m * 60s) = 930 000 000 / 2678400s = 348 odczytów na sekundę, ponieważ jeden RCU pozwala na 2 odczyty na sekundę potrzebujemy 348 / 2 = 174 RCU.
Maksymalna liczba notatek jaką będziemy przechowywać w systemie po upływie 1 roku to:
- 12 miesięcy * 310 000 000 notatek = 3 720 000 000 * 1 KB = 3720 GB danych.
Koszty wyniosą odpowiednio:
- koszt zapisów, czyli WCU to 116 - 25 (free tier) = 91 WCU * $0.47 = $42.77 miesięcznie,
- koszt odczytów, czyli RCU to 174 - 25 (free tier) = 149 RCU * $0.09 = $13.41 miesięcznie,
- koszt przechowywania danych to 3720 GB * $0.25 = $930 miesięcznie.
W sumie za użycie DynamoDB zapłacimy miesięcznie $986.18.
Koszty lambd
Lambda getNotes:
- będzie wywoływana 930 000 000 razy miesięcznie,
- możemy odjąć od tej liczby 1 000 000 requestów (free tier),
- zostaje 929 000 000 requestów,
- za każdy 1 000 000 requestów płacimy $0.20,
- w sumie mamy więc 929 * $0.20 = $185.8 miesięcznie.
Lambda addNote:
- będzie wywoływana 310 000 000 razy miesięcznie,
- koszt wynosi więc 310 * $0.20 = $62 miesięcznie.
Oprócz opłat za liczbę requestów płacimy jeszcze za gigabajto-sekundy. Załóżmy w przybliżeniu, że wywołanie lambdy odczytującej będzie mieściło się w 100 ms, a lambdy zapisującej w 200 ms.
Dla getNotes mamy więc:
- 930 000 000 * 0.1s * 128 / 1024 MB = 11 625 000 GB-s,
- od tej wartości możemy odjąć 400 000 GB-s (free tier),
- koszt wynosi: 11 225 000 GB-s * $0.00001667 = $187.12 miesięcznie.
Odpowiednio dla addNote:
- 310 000 000 * 0.2s * 128 / 1024 MB = 7 750 000 GB-s,
- koszt wynosi 7 750 000 * $0.00001667 = $129.19 miesięcznie.
Sumaryczny koszt lambd wynosi $316.31 miesięcznie.
Koszty API-Gateway
Koszty API-Gateway podzielone są na koszty wykonanych żądań oraz koszty transferu danych. Miesięcznie wykonujemy:
- 1 000 000 użytkowników * (10 zapisów + 30 odczytów) * 31 dni = 1 240 000 000 wywołań API-Gateway,
- za 1 000 000 wywołań płacimy $3.70, koszt wynosi więc 1 240 * $3.70 = $4 588.
Przy założeniu, że pojedyncza notatka ma średnio 1 KB transferujemy:
- 1 000 000 użytkowników * (10 zapisów + 30 odczytów) * 31 dni * 1KB = 1.24 TB danych,
- koszt transferu dla pierwszy 10 TB to $0.09 za 1 GB,
- koszt wynosi więc 1 240 GB * $0.09 = $111.6 miesięcznie.
W sumie koszty API-Gateway to $4 699.6 miesięcznie.
Podsumowanie
Przy przyjętych założeniach całkowity koszt naszej przykładowej aplikacji wyniesie $6 002.09 miesięcznie. Wydaje się to sporą kwotą, jeżeli jednak podzielimy to przez liczbę użytkowników, dostajemy koszt około $0.006 na jednego użytkownika miesięcznie. Wynika z tego, że roczne utrzymanie jednego użytkownika zamknie się w $0.08 - jeżeli zaoferujemy użytkownikom cenę $0.99 za roczny dostęp do usługi na jednym użytkowniku zarobimy $0.91 rocznie :-)
Wady i zalety rozwiązania
Rozwiązanie oparte o AWS wydaje się być dość proste do wykonania, a także atrakcyjne cenowo. Płacimy tylko za faktyczne zużycie zasobów nie ma więc niebezpieczeństwa, że w przypadku małego zainteresowania naszą aplikacją poniesiemy straty związane z kosztami utrzymania infrastruktury. Dodatkowo w standardzie dostajemy dużą skalowalność rozwiązania. Wady? - W takiej implementacji bardzo mocno uzależniamy się od komponentów AWS, przeniesienie rozwiązania na inną infrastrukturę wiąże się praktycznie z jego przepisaniem.
Już wkrótce na naszym blogu pojawi się artykuł omawiający automatyzację tworzenia zasobów na AWS w oparciu o narzędzie terraform. Zapraszamy.
Podobne wpisy





