Batchowe inserty w Hibernate - droga ku szybkości

W tym poście powiemy o przykładowej ścieżce optymalizacji wstawiania grup rekordów do bazy danych za pomocą Hibernate’a i SpringBoota z założeniem użycia spring-boot-starter-data-jpa. Skupimy się na aspektach konfiguracyjnym i diagnostycznym systemu.
Zapytany o to czy lepiej używać EntityManagera czy Hibernate’owego Session, Emmanuel Bernard bez wahania opowiedział się za tym pierwszym [1]. Jest to wypowiedź zgodna z zasadą, którą jako programiści wszyscy dobrze znamy – bazowanie na specyfikacji, a nie implementacji danej technologii. Stosowanie się do tej reguły sprawia, że zmiany technologiczne są o wiele prostsze - jesteśmy związani tylko z interfejsem, a podmiana dostawcy jego implementacji jest przecież w założeniu tylko formalnością.
Zdarza się jednak, że musimy zrobić coś co wychodzi poza ramy abstrakcyjnej specyfikacji i chcąc nie chcąc użyć mechanizmów konkretnej implementacji. Tak jest też w przypadku batchowych insertów czyli zapisywania większych grup rekordów w jednej transakcji. W tym poście przejdziemy przez typową drogę optymalizacji tejże operacji, przykłady wizualizując statystykami generowanymi przez Hibernate’a oraz przepływami zilustrowanymi za pomocą Zipkina [2].
Załóżmy dobrze znany scenariusz - podczas spokojnego dnia w pracy nagle otrzymujemy maila:
Złe wieści!
Wystawiona usługa co prawda działa, ale nie możemy za jej pomocą w jednym żądaniu złożyć 2000 zamówień.
Okazuje sie, że oczekiwanie na odpowiedź trwa zbyt długo i dostajemy timeout!
Nie pozostaje nam nic innego jak przystąpić do optymalizacji. Pierwsze kroki, który warto podjąć to ustawienie w celach diagnostycznych wpisu konfiguracyjnego
spring.jpa.properties.hibernate.generate_statistics=true
w pliku .properties lub .yml oraz odpowiednie skonfigurowanie Zipkina (tu tę konfigurację pominiemy bo jest ona obszernym materiałem, który mógłby wypełnić osobny artykuł). Te kroki pomogą nam w prześledzeniu powodu wyjątkowo długiego czasu odpowiedzi usługi. Przykłady będziemy badać na realnej usłudze w dwóch wariantach – żądanie z małą liczbą encji zwizualizowane za pomocą Zipkina oraz żądanie z dużą liczbą encji opisane za pomocą kluczowych statystyk i czasu wykonania. Przejdźmy do analizy. Na początek przyjrzyjmy się usłudze bez żadnych optymalizacji.

Co powoduje, że widzimy tak dużo wykonanych operacji? Już na pierwszy rzut oka widać, że każde wstawianie rekordu jest realizowane osobno. Spójrzmy na wygenerowane statystyki dla normalnego wywołania usługi (przy dużej liczbie encji)
Łączny czas odpowiedzi usługi przy wywołaniu przez HTTP 9503ms (POSTMAN)
Kluczowe statystyki wygenerowane przez Hibernate:
195762869 nanoseconds spent preparing 4005 JDBC statements;
6984223566 nanoseconds spent executing 4005 JDBC statements;
0 nanoseconds spent executing 0 JDBC batches;
4163640487 nanoseconds spent executing 1 flushes (flushing a total of 2003 entities and 0 collections);
5927 nanoseconds spent executing 1 partial-flushes (flushing a total of 0 entities and 0 collections)
Ze statystyk wynika, że nie wykonały się żadne paczki operacji, widać natomiast informację o zrealizowaniu ponad 4000 komend JDBC. Wąskim gardłem jest sposób wstawiania rekordów do bazy danych. Jak temu zaradzić?
Z pomocą przychodzi nam konfiguracja operacji batchowych. Skupimy się przede wszystkim na wstawianiu rekordów. Skonfigurujmy batchowe inserty poprzez dodanie do wcześniej wspomnianych plików konfiguracyjnych odpowiednich wpisów
spring.jpa.properties.hibernate.jdbc.batch_size=1000
Dodając ten wpis ustawiliśmy wielkość paczek w operacjach paczkowanych. Warto również, choć nie jest to wymagane, ustawić inny wpis konfiguracyjny.
spring.jpa.properties.hibernate.order_inserts=true
Jest to przydatne szczególnie w przypadku gdy występuje relacja encji rodzic-dziecko z kaskadową persystencją, pozwoli to w takim przypadku na zgrupowanie zapisów typami encji.
Po wykonaniu pierwszego kroku optymalizacyjnego sprawdźmy jak zmieniły się wygenerowane statystyki.

Dla dużej liczby encji statystyki prezentują się następująco:
Łączny czas odpowiedzi usługi przy wywołaniu przez HTTP 5138ms (POSTMAN)
Kluczowe statystyki wygenerowane przez Hibernate:
84610265 nanoseconds spent preparing 2006 JDBC statements;
3139685203 nanoseconds spent executing 2003 JDBC statements;
349347467 nanoseconds spent executing 4 JDBC batches;
539223064 nanoseconds spent executing 1 flushes (flushing a total of 2003 entities and 0 collections);
5446 nanoseconds spent executing 1 partial-flushes (flushing a total of 0 entities and 0 collections)
Zarówno z zwizualizowanego przepływu dla małej liczby encji, jak i wygenerowanych statystyk dla dużej ich liczby widzimy, że operacji jest mniej więcej o połowę mniej, a wygenerowane statystyki wprost mówią, że zostały wykonane „paczki” operacji. Nadal jednak wywołań komend JDBC jest dużo ponieważ wciąż wykonywane są indywidualne zapytania po przydział numerów bazodanowej sekwencji, które służą jako identyfikatory wstawianych encji. Jak możemy temu zaradzić? Początkowa konfiguracja identyfikatora naszej encji wygląda tak:
@Id
@GeneratedValue
private Long transactionId;
W praktyce oznacza to zostawienie dostawcy implementacji dowolności w doborze strategii generowania id. Weźmy sprawy w swoje ręce i zmieńmy strategię generowania id dla naszej encji na odpowiadającą naszym potrzebom.
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "hilo_sequence_generator")
@GenericGenerator(
name = "hilo_sequence_generator",
strategy = "org.hibernate.id.enhanced.SequenceStyleGenerator",
parameters = {
@Parameter(name = "sequence_name", value="EXAMPLE_SEQ"),
@Parameter(name = "initial_value", value="1"),
@Parameter(name = "increment_size", value = "100"),
@Parameter(name = "optimizer", value = "hilo")
})
private Long transactionId;
Co właściwie skonfigurowaliśmy w tym momencie? W adnotacji GeneratedValue informujemy Hibernate by użył strategii sekwencji generowania id dla encji i wskazujemy nazwę generatora. Niżej podajemy wcześniej wspomnianą nazwę generatora, klasę wskazującą na strategię generatora, podstawowe parametry i optymalizator. Jak działa ten ostatni, u nas przyjmujący wartość „hilo”?
Sam algorytm hi/lo jest opisany w wielu miejscach na internecie [3], dlatego skupimy się tylko na tym jak działa na poziomie koncepcyjnym:
Skoro nie chcemy za każdym razem pytać bazę danych o nowy numer sekwencji, to możemy jako klient zapytać o niego raz na N encji (wartość N została przez nas ustawiona w parametrze increment_size), a pomiędzy tymi zapytaniami sami inkrementować licznik.
W praktyce oznacza to, że mogą powstać „dziury” w numeracji, gdy w danej transakcji wstawimy jedną encję to mimo wszystko potrzebujemy numeru sekwencji z bazy danych, a w konsekwencji podbijemy ją o N. Zyskiem z korzystania z tego mechanizmu jest rzadka potrzeba pytania bazy o kolejną wartość sekwencji. Sprawdźmy kolejny raz jak nasze optymalizacje wpłynęły na szybkość działania usługi.
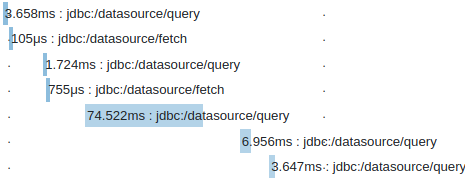
Dla dużej liczby encji statystyki prezentują się następująco:
Łączny czas odpowiedzi usługi przy wywołaniu przez HTTP: 1746 ms (POSTMAN)
Kluczowe statystyki wygenerowane przez Hibernate:
4294453 nanoseconds spent preparing 26 JDBC statements;
118572140 nanoseconds spent executing 23 JDBC statements;
531069793 nanoseconds spent executing 4 JDBC batches;
732899796 nanoseconds spent executing 1 flushes (flushing a total of 2003 entities and 0 collections);
5497 nanoseconds spent executing 1 partial-flushes (flushing a total of 0 entities and 0 collections)
Widzimy kolejny drastyczny spadek liczby wykonywanych operacji wynikający z tego, że nie musimy tak często odpytywać bazy o kolejne numery sekwencji. Porównajmy teraz łączne wywołania usługi
Stan początkowy – bez optymalizacji: 9503 ms
Z batchowymi insertami: 5138 ms
Z batchowymi insertami i optymalizacją sekwencji: 1746 ms
Dzięki użyciu odpowiednich mechanizmów zmniejszyliśmy czas odpowiedzi naszej usługi o ponad 80%! Warto wspomnieć, że przy tego typu optymalizacjach zmiany w czasach wykonywania żądań mogą być wysoce zależne od użytych technologii, dla konkretnych baz danych istnieją też specyficzne możliwe optymalizacje. Dobrym przykładem tego jest ustawienie obecne w MySQL
rewriteBatchedStatements=true
pozwalające na zoptymalizowanie liczby zapytań przesyłanych w pakiecie sieciowym.
W przypadku optymalizacji takich jak pokazane w tym poście warto zajrzeć pod maskę - do dokumentacji, a nawet kodu źródłowego frameworku, a także zaopatrzyć się w dobre narzędzia wspomagające diagnostykę jak chociażby wyżej przytoczony Zipkin.
Warto też strzec się błędów i niepoprawnych użyć mechanizmów frameworków, należy chociażby pamiętać o tym, że aby wykonać batch insert za pomocą klasy JpaRepository z frameworku Spring musimy skorzystać z metody saveAll, a nie save. Osobnej optymalizacji poprzez ustawienie order_updates w plikach konfiguracyjnych może wymagać również uaktualnianie rekordów. Kolejna pułapka o której należy pamiętać związana jest z cache poziomu L1. Jak wiemy, działa ono na poziomie pojedynczej transakcji. Oznacza to, że zapisując dużą liczbę encji w jednej transakcji narażamy się na problemy pamięciowe.
Podsumowując, wiemy że ceną za wysoki poziom abstrakcji frameworków jest to, że dużo rzeczy dzieje się poza naszym wzrokiem. Czasem musimy wyjść poza specyfikację interfejsu technologicznego i skorzystać z mechanizów konkretnej implementacji, takie podejście często bazowane jest na eksperymentowaniu by dowiedzieć jaki mechanizm rozwiąże nasz problem. Wymaga to nieraz diagnostycznego spojrzenia na problem oraz zagłębienia się w dokumentację używanej przez nas technologii.
Podobne wpisy





