Jak szybko stworzyć system monitoringu serwerów i usług

Bieżące informacje o stanie serwerów i działających na nich usług są ważne dla każdego dostawcy rozwiązań IT, z którego korzysta szersza rzesza użytkowników. Najważniejsze oczywiście jest zapewnienie, że wszystkie usługi działają. Jednak samo działanie to jeszcze nie wszystko. Ważny jest także czas odpowiedzi z tych usług. Jeśli czas odpowiedzi wzrósł, lub nawet usługa przestała odpowiadać, przydatna może okazać się znajomość stanu maszyny w zadanym czasie. W tym celu przydatne będą takie dane, jak obciążenie procesora w danym momencie, zużycie pamięci RAM oraz wolnej przestrzeni na dysku. Aby możliwie szybko zareagować, a być może także uniknąć sytuacji, w której usługa przestaje odpowiadać, istotne są ostrzeżenia, które pozwolą zareagować na czas. Niniejszy artykuł ma na celu zaprezentować rozwiązanie, które pozwoli w miarę szybko stworzyć system monitoringu oraz ostrzegania na systemach wyposażonych w system Linux, oparty o takie narzędzia jak “Grafana”, “Icinga2” oraz “InfluxDB”.
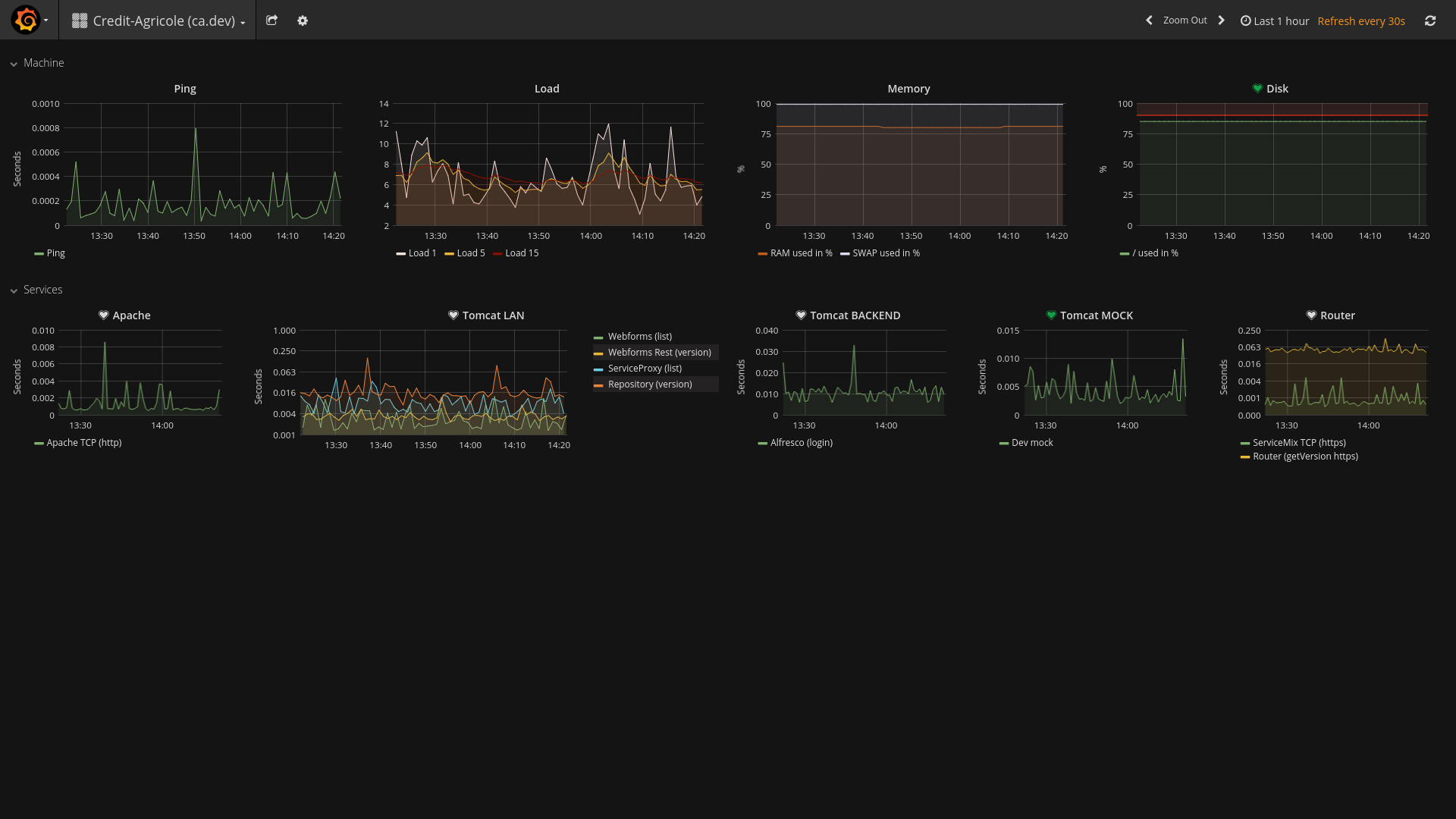 Przykładowy dashboard prezentujący stan maszyny (obciążenie, zużycie ramu i dysku), jak i działających na nim usług
Przykładowy dashboard prezentujący stan maszyny (obciążenie, zużycie ramu i dysku), jak i działających na nim usług
Wymagania wstępne
Na maszynie, która pełnić będzie rolę serwera monitoringu należy:
- Zainstalować Dockera (https://docs.docker.com/engine/installation/)
- Zainstalować Docker-Compose (https://docs.docker.com/compose/install/)
- Należy upewnić się, że sieci tworzone przez Dockera będą miały dostęp do maszyn, które chcemy monitorować. Przypadkiem kiedy takiego dostępu może nie być, jest sytuacja w której monitorowane maszyny znajdują się za siecią VPN. Jednym z rozwiązań w takim przypadku, które odbywa się kosztem słabszej separacji kontenera od hosta, jest edycja pliku docker-compose.yml z punktu piątego niniejszego rozdziału, tak aby kontenery korzystały z sieci hosta.
- W kolejnym kroku powinniśmy wygenerować parę kluczy SSH, która posłuży do uwierzytelniania się na monitorowanych maszynach.
- Na sam koniec pozostaje pobranie następującego projektu: https://github.com/aswarcewicz/monitoring
Na maszynach, które będą monitorowane należy dodać do zaufanych klucz publiczny SSH wygenerowany na serwerze monitoringu w kroku czwartym, tak aby serwer monitorujący mógł logować się przez SSH bez podawania hasła. Logowanie przez SSH wykonywane jest celem pobrania stanu maszyny (obciążenie, zużycie RAMu oraz dysku).
Uruchamiamy kontenery
- Po pobraniu projektu z githuba, należy umieścić klucz prywatny serwera wewnątrz struktury pobranego projektu w katalogu “icinga2/ssh_keys”. Klucz prywatny zazwyczaj nosi nazwę id_rsa i nie posiada rozszerzenia *.pub.
- Tworzymy i uruchamiamy wszystkie kontenery następującym poleceniem wykonanym wewnątrz pobranego projektu: “docker-compose up”
- W terminalu obok wykonujemy polecenie “docker exec -it influxdb bash”, dzięki któremu znajdziemy się wewnątrz kontenera influxdb.
- W celu utworzenia bazy danych pod zbierane metryki uruchamiamy w kontenerze następujący program “/opt/influxdb/usr/bin/influx”
- Następnie wykonujemy polecenie tworzące bazę danych, która będzie przechowywała dane przez dwa tygodnie. Długość przechowywania danych można dobrać dowolnie, w tym także pominąć ich usuwanie po zadanym czasie. “CREATE DATABASE icinga2 WITH DURATION 2w”. Po wykonaniu tego polecenia można już opuścić kontener influxdb.
- W tym kroku należy przejść do konfiguracji Icinga2, tak aby zapisywała zebrane dane do wcześniej utworzonej bazy InfluxDB. Uruchomienie polecenia z punktu drugiego stworzyło w katalogu projektu folder o nazwie “data”, wewnątrz którego znajdują się niezbędne konfiguracje oraz bazy danych. W celu konfiguracji Icinga2 należy wyedytować plik “./data/config/icinga2/features-enabled/influxdb.conf” tak, aby wskazywał na właściwą bazę danych. Jeśli korzystamy z sieci utworzonej przez dockera, w linijce odpowiedzialnej za hosta powinien znaleźć się wpis “influxdb”, gdyż pod takim aliasem dostępny będzie kontener z bazą. Natomiast, jeśli korzystamy z sieci host’a, w tej samej linijce powinien znaleźć się wpis localhost. Pozostałe linijki wystarczy odkomentować.
- Uruchamiamy ponownie całość. Można dokonać tego poprzez użycie kombinacji klawiszy “CTRL+C” na terminalu z uruchomionym poleceniem “docker-compose up” lub poprzez uruchomienie innego terminala w katalogu projektu oraz wykonanie polecenia “docker-compose stop”. Po zatrzymaniu kontenerów należy oczywiście uruchomić je ponownie za pomocą “docker-compose up” lub w tle “docker-compose start”.
Konfiguracja zbierania danych
W tej części skonfigurujemy Icingę tak, aby zbierała dane potrzebne dla naszego monitoringu. Wszystkie konfiguracje powinny znaleźć się w katalogu projektu “./data/config/icinga2/conf.d” lub w jego podkatalogach, aby zostały zaczytane przez Icingę. Warto zwrócić uwagę na domyślną konfigurację komend zbierających dane o obciążeniu, zużyciu pamięci RAM czy dysku. Komendy te domyślnie wykorzystują użytkownika “root” do logowania po SSH, jeśli klucze wygnerowane w podpunkcie 4. “wymagań wstępnych” przeznaczone są dla innego użytkownika, to warto dokonać tej zmiany globalnie już w samej konfiguracji komend.
Aby rozpocząć zbierane danych przez Icingę należy najpierw skonfigurować usługi, przykładowa konfiguracja poniżej:
apply Service "router_version_https" {
import "generic-service"
display_name = "Router (version) - HTTPS"
assign where "router" in host.vars.services
ignore where host.vars.router.https.port == ""
check_command = "http"
vars.http_uri = "/router/version/getVersionNumber"
vars.http_vhost =
vars.http_port =
vars.http_ssl = "true"
}
apply Service "servicemix_tcp_https" {
import "generic-service"
display_name = "ServiceMix - TCP (https)"
assign where "router" in host.vars.services
ignore where host.vars.router.https.port == ""
check_command = "tcp"
vars.tcp_address =
vars.tcp_port =
}
A następnie dodać konfigurację maszyn (hostów), które z tych usług korzystają, przykład poniżej:
object Host "Consdata (formdev)" {
import "generic-host"
address = "formdev.eximee.consdata.local"
vars.os = "Linux"
vars.services = ["check-load", "check-memory", "check-disk-space", "router"]
/* Router */
vars.router.https.port = "9002"
}
Po ponownym uruchomieniu Icinga powinna zaczytać konfigurację i co około 30 sekund zapisywać metryki do InfluxDB. Ewentualne problemy powinny znaleźć się w logach, do których dostęp można uzyskać poprzez komendę “docker logs -f icinga2”.
Wizualizacja danych
Kolejnym etapem jest skonfigurowanie Grafany, aby zaczęła wyświetlać dane zbierane przez Icingę. Grafanę znajdziemy na porcie 3000 na maszynie, na której uruchomiono pobrany z GitHuba projekt. Domyślny login to admin, domyślne hasło to także admin. Po zalogowaniu, podobnie jak w przypadku Icingi, konfigurujemy najpierw źródło danych, jeśli korzystamy z sieci Docker’a źródło danych będzie znajdowało się na hoście o nazwie influxdb, w przypadku korzystania z sieci hosta będzie to localhost. Następnie możemy przejść do konfiguracji Dashboard’ów czyli tablic agregujących wykresy. Najpierw dodajemy wiersz, później wykres, a następnie przechodzimy do edycji (konfiguracji) wykresu.
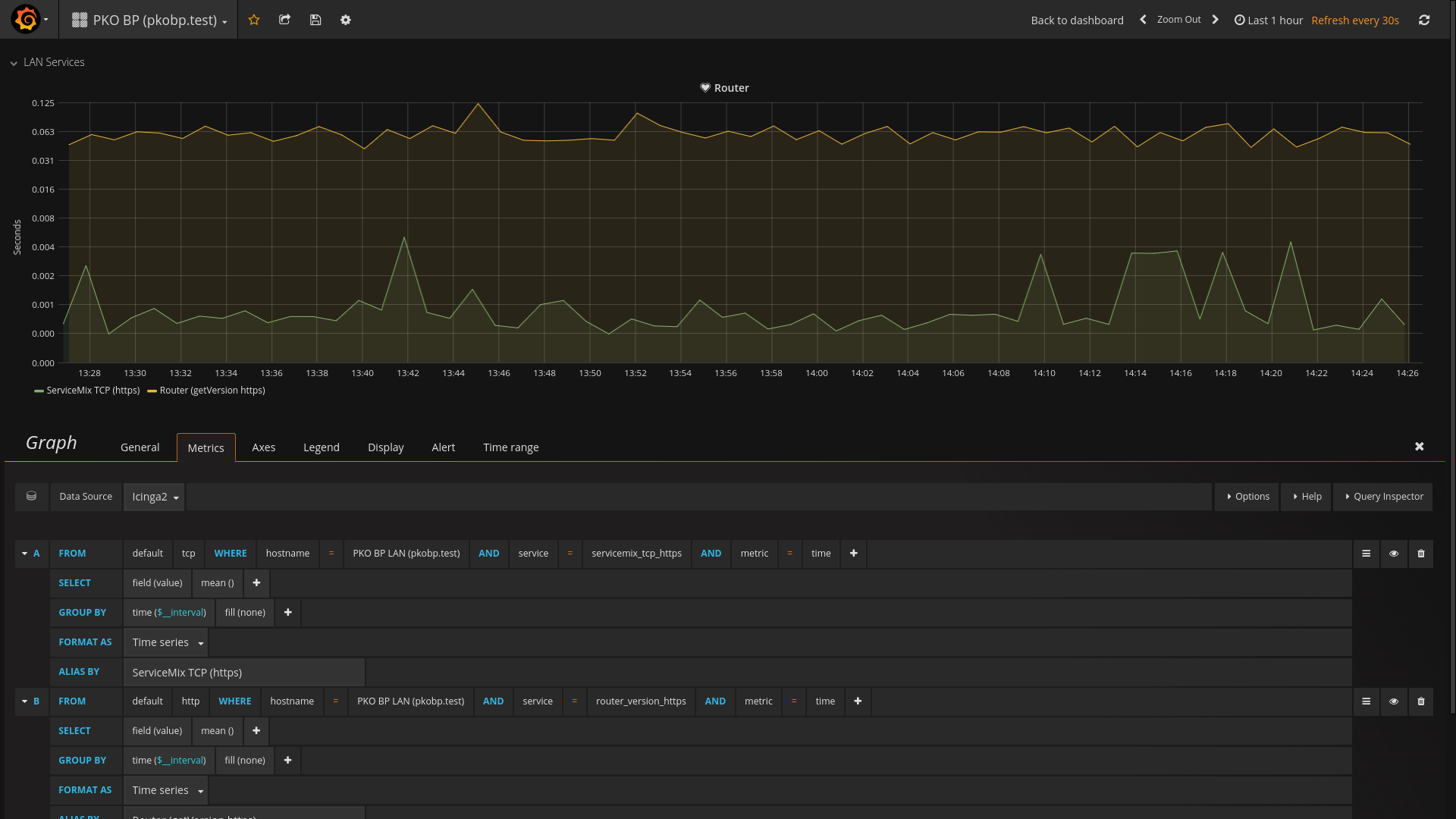 Konfiguracja wyświetlania metryk dla wykresu
Konfiguracja wyświetlania metryk dla wykresu
Tak naprawdę wszystko tutaj powinno dać się wyklikać, jeśli brakuje jakiejś metryki, a minęło więcej niż 30-60 sekund od startu Icingi z nową konfiguracją, oznacza to błąd w konfiguracji. W takim przypadku istnieje szansa, że znajdziemy jakieś informacje po wykonaniu komendy “docker logs -f icinga2”. W przypadku konfiguracji alertów istotne może okazać się wypełnienie miejsc, w których brakuje danych. Na powyższym screenie wybrano “none” i taką opcję zalecałbym na początek.
Powiadomienia w przypadku problemu z usługami
Kolejnym etapem będzie konfiguracja powiadomień. Dla odmiany od najczęściej wykorzystywanych powiadomień mailowych w tym przypadku skorzystamy z komunikatora Slack.
- Na początku musimy skonfigurować SlackBota, a dokładniej “Incoming Webhook”. W przypadku Consdaty można tego dokonać pod następującym adresem: https://consdata.slack.com/apps/manage/custom-integrations
- Po otrzymaniu adresu URL należy go dodać w Menu “Alerting->Notification Channels”. W razie potrzeb można swobodnie wykorzystać jeden URL, aby skonfigurować kilka kanałów:
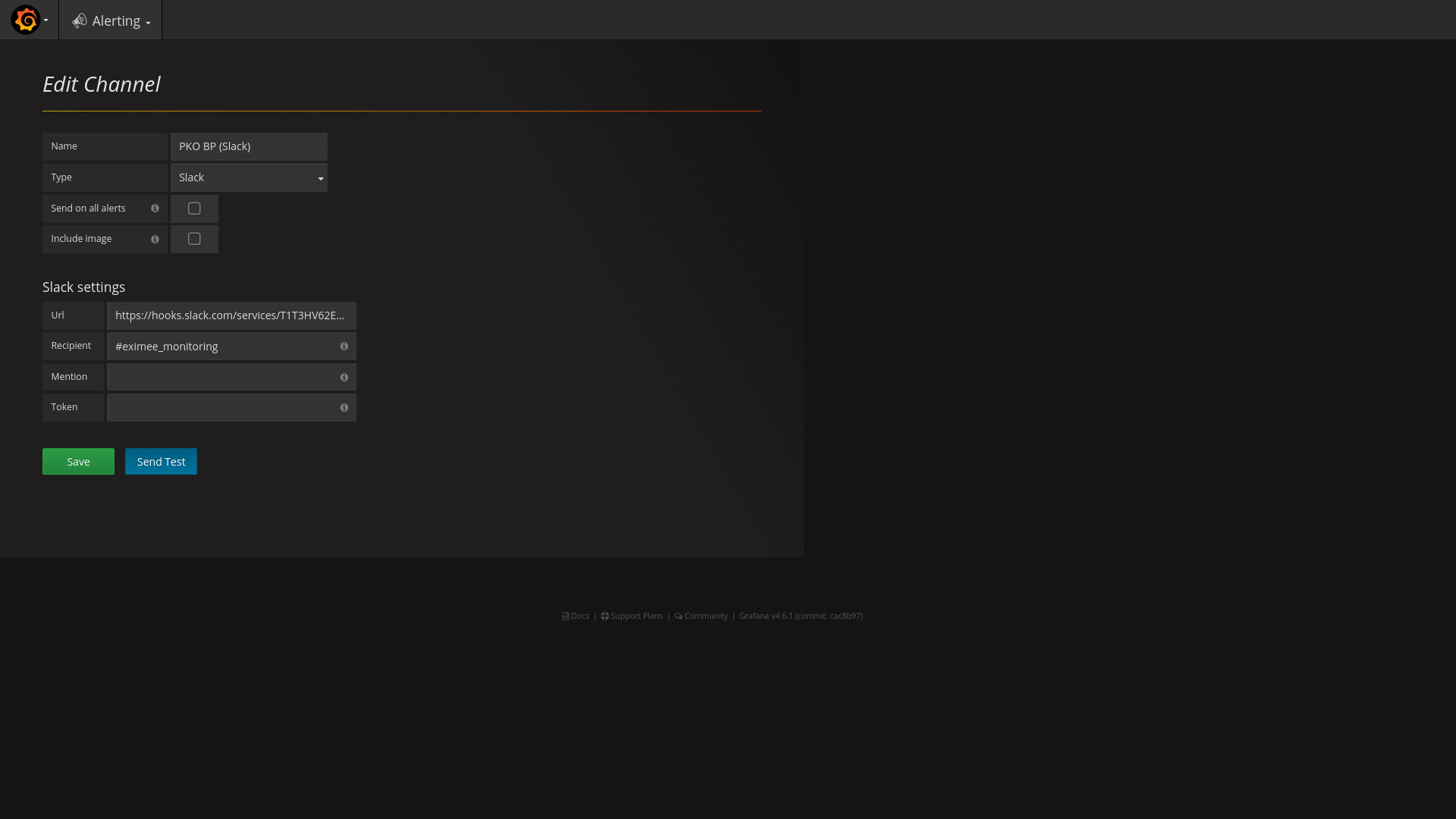 Ekran edycji kanału powiadomień. W tym przypadku jako kanał dostarczania powiadomień wybrano komunikator Slack
Ekran edycji kanału powiadomień. W tym przypadku jako kanał dostarczania powiadomień wybrano komunikator Slack - Po tym pozostaje już tylko konfiguracja powiadomień dla każdego z wykresów z osobna
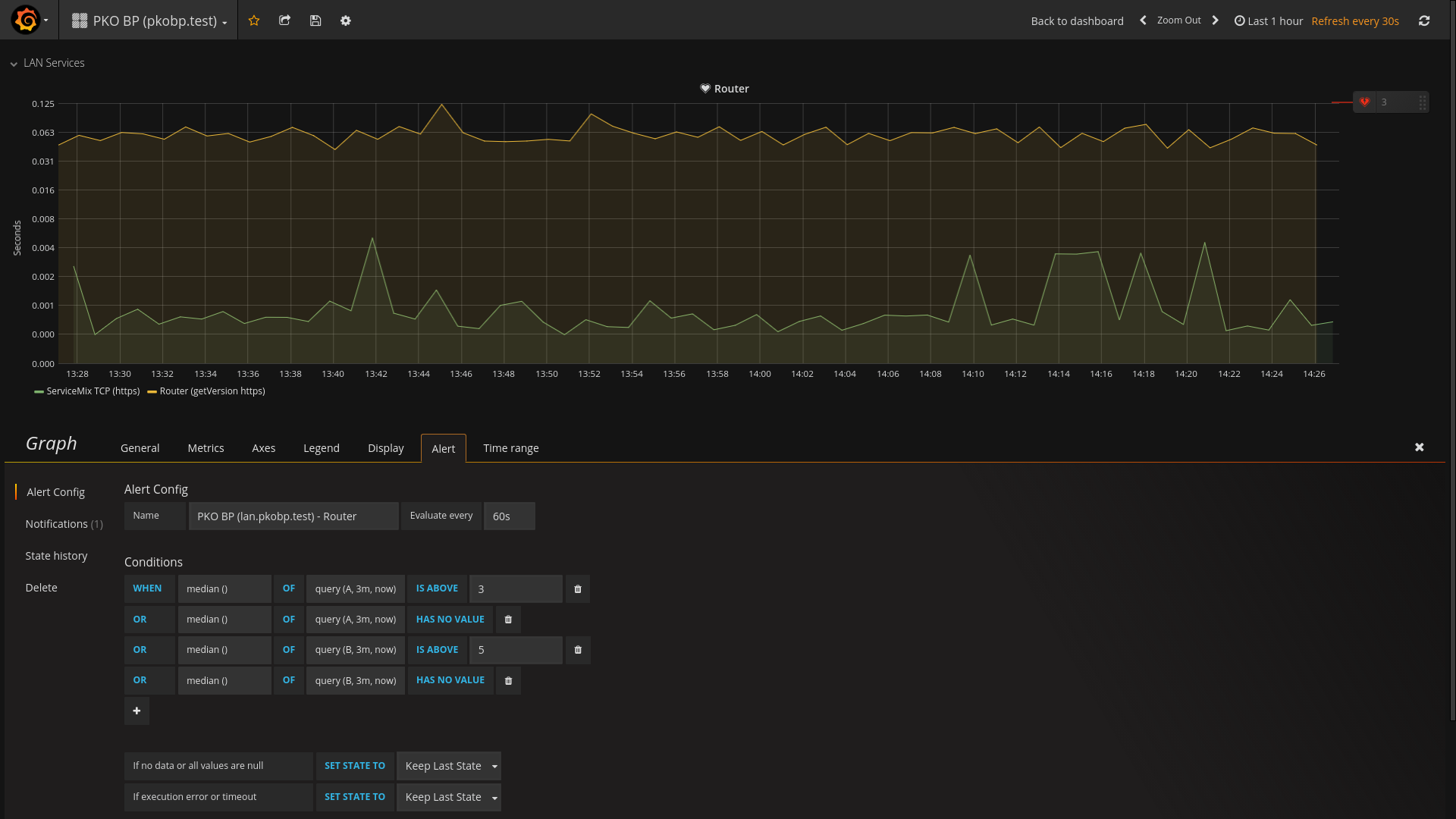 Konfiguracja wywołania powiadomienia na wykresie, dla którego wcześniej skonfigurowano zbieranie metryk
Konfiguracja wywołania powiadomienia na wykresie, dla którego wcześniej skonfigurowano zbieranie metryk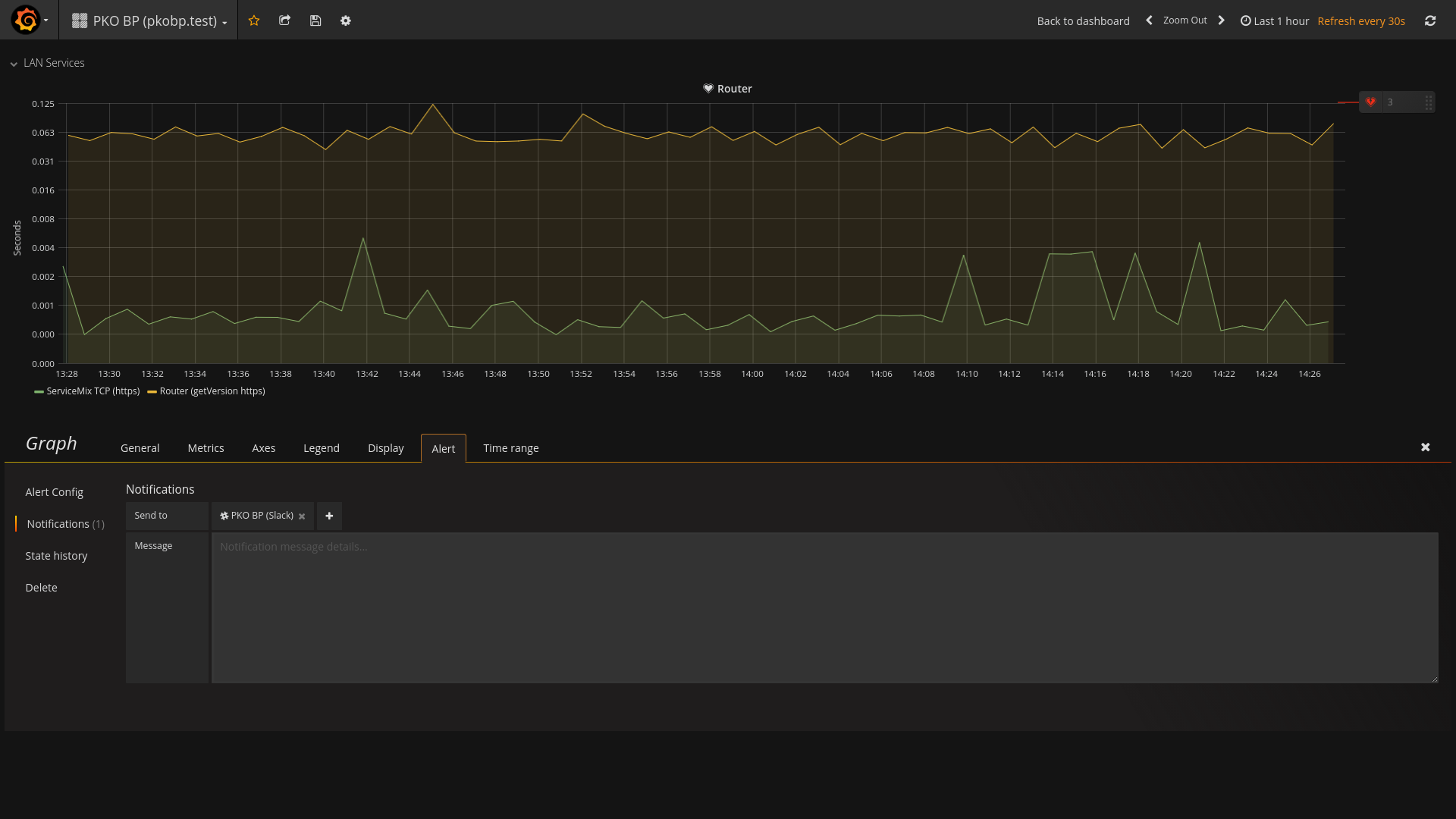 Konfiguracja wywołania powiadomienia na wykresie - wybór sposobu wysyłki alertu
Konfiguracja wywołania powiadomienia na wykresie - wybór sposobu wysyłki alertu - Od tej chwili, w przypadku wystąpienia problemów, możemy spodziewać się komunikatów podobnych do tego poniżej
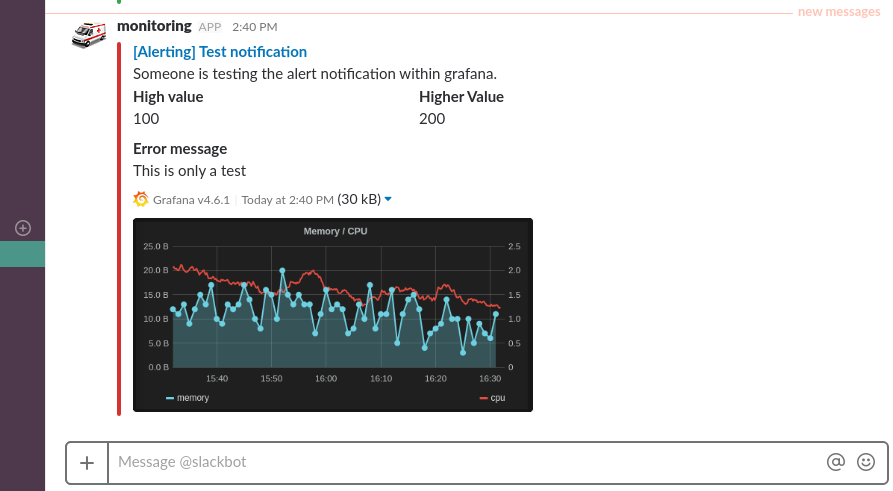 Przykładowy alert dostarczany na komunikator Slack
Przykładowy alert dostarczany na komunikator Slack
Podsumowanie
Połączenie Grafany, jako warstwy prezentacji i ostrzegania, oraz Icingi, jako narzędzia do zbierania metryk, jest dosyć łatwym i szybkim w zestawieniu systemem do monitorowania serwerów. Warto zwrócić uwagę także na wiele opcji budowania własnych tablic z wykresami. Poza grupowaniem wykresów w wiersze z opcjami zwijania, ustalania różnych rozmiarów czy umieszczania na tablicach kontrolek, które prezentują dane w innych formach niż wykresy (np. w formie tabel lub pojedynczych wartości), wartą uwagi jest funkcjonalność zmiennych, których można używać na wykresach. Zmienne można definiować za pomocą wartości wpisanych na stałe, lub w formie zapytań. Jednym z zastosowań takiej funkcjonalności jest dynamiczna tablica zasilana metrykami z różnych serwerów w zależności od wybranej opcji.
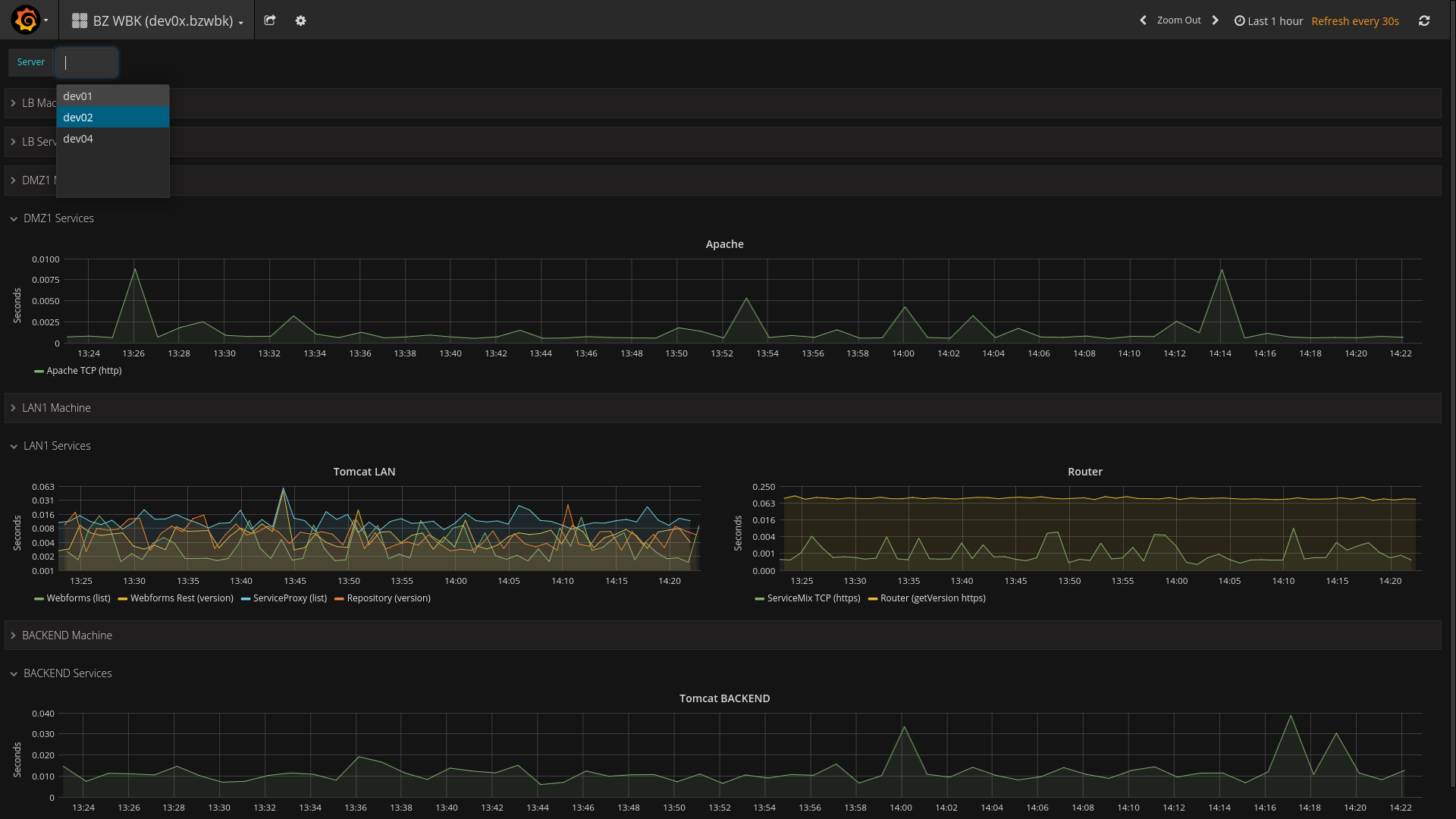 Dashboard, na którym zaprezentowano przykładowe użycie zmiennych. W tym wypadku jeden Dashboard jest w stanie przełączać serwer, z którego wyświetlane są metryki
Dashboard, na którym zaprezentowano przykładowe użycie zmiennych. W tym wypadku jeden Dashboard jest w stanie przełączać serwer, z którego wyświetlane są metrykiNiestety opcja ta nie jest pozbawiona wad i w bieżącej wersji Grafany (4.6.2), chcąc skorzystać ze zmiennych, pozbawiamy się możliwości definiowania powiadomień.
Podobne wpisy





