Gatling! “Odłamkowym ładuj!”, czyli jak strzelać do aplikacji

W każdym projekcie pojawia się moment, w którym pada stwierdzenie: “A co z wydajnością? Damy radę na produkcji?”. I wtedy cały zespół zastanawia się, ile tak naprawdę zniesie owoc ich wielomiesięcznych prac. Kod po wnikliwych review, poprawkach architektonicznych i projektowych wygląda wspaniale w repozytorium, ale analizując go, trudno stwierdzić czy aplikacja wytrzyma ruch na produkcji oraz gdzie są najsłabsze ogniwa. Trzeba to sprawdzić w praktyce. Przygotowujemy środowisko zasobami zbliżone do produkcji albo odpowiednio wyskalowane i klikamy. A co tam, zespół duży, zacięcie klika i osiągamy ruch 5 użytkowników. Szybka analiza logów i wszystko jest OK. Ale zaraz, to nic nam nie daje. Nadal nie zidentyfikowaliśmy najsłabszego ogniwa. Zautomatyzujmy zatem użytkowników w systemie i wykonajmy symulację bardzo dużej liczby użytkowników. Pierwsze co przychodzi na myśl, to…
Nasz stary znajomy - Apache JMeter. Aplikacja bardzo rozbudowana, gdzie można tworzyć skomplikowane przepływy użytkowników. Narzędzie bogate w liczne funkcje, ale jak dla mnie dość toporne. Pisanie w nim nowych scenariuszy zawsze idzie jakoś ciężko. Praca jest lżejsza, jeśli można oprzeć się na starych testach. Trudno jednak czeprać przyjemność z pracy tym narzędziem.
Również w moim zespole, gdy pojawiła się kwestia testów wydajnościowych, pierwszą sugestią było użycie JMeter’a. Głównie z racji dostępnych scenariuszy dla podobnego przepływu użytkownika. W trakcie dyskusji na temat wydajności padło, że w firmie, jeden z zespołów użył narzędzia Gatling, które sprawdziło się dużo lepiej, niż narzędzie Apacha. Powód był bardzo prosty, scenariusze się programuje, a nie klika w GUI. Przez co są czytelniejsze i łatwiejsze do utrzymania w repo. Co prawda, w Gatlingu koduje się w języku scala, ale nawet jeśli, ktoś nigdy nie programował w tym języku, to bez problemu sobie poradzi. Podstawy w zupełności wystarczą. Nie jest potrzebna skomplikowana wiedza, o czym przekonują nawet twórcy na swojej stronie.
Poniżej spróbuję przybliżyć owe narzędzie posługując się prostym przykładem.
Co by tu potestować?
Na początku musimy przygotować środowisko do testów. Wystawimy jakiś prosty serwis z kilkoma metodami. Najszybciej będzie skorzystać ze springboot’a i zainicjować projekt. Wchodzimy na https://start.spring.io, klikamy co nas interesuje i ściągamy projekt. Importujemy i możemy zaczynać. Dodajemy prosty serwis.
package pl.consdata.server.controller;
import org.springframework.web.bind.annotation.*;
import java.security.SecureRandom;
@RestController
public class SimpleWaitController {
private final String GENERIC_RESPONSE = "{\"result\": %1$d}";
@GetMapping(path = "/getWaitTime")
@ResponseBody
public String getWaitTime() {
SecureRandom random = new SecureRandom();
return String.format(GENERIC_RESPONSE, 5000 + random.nextInt(5500));
}
@PostMapping(path = "/wait")
@ResponseBody
public String waitForNextStep(Integer waitTime) {
try {
Thread.sleep(waitTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
return String.format(GENERIC_RESPONSE, waitTime);
}
@GetMapping(path = "/stop/{waitTime}")
public String stop(@PathVariable Integer waitTime) {
return "user end after: " + waitTime;
}
}
Funkcjonalność poszczególnych metod nie jest skomplikowana, ale do testu wystarczy. Zakładamy następujący przepływ użytkownika (każdy użytkownik postępuje tak samo):
- Pobiera czas przetwarzania
- Wywołuje przetwarzanie
- Czeka 5 sekund - po stronie użytkownika
- Opuszcza ten skomplikowany proces
Skoro aplikacja jest gotowa, to spróbujmy zastanowić się: co jest słabym ogniwem? Bystre oko zauważy, że endpoint ‘/wait’ może sprawiać problemy, gdyż zawiera metodę ‘sleep’. OK, zgodzę się, ale pomimo tego - jaki ruch ta aplikacja wytrzyma i co pierwsze padnie? Tutaj odpowiedź już nie jest już taka oczywista. Przygotujmy zatem test wydajnościowy i sprawdźmy.
Zaprogramujmy scenariusz wydajnościowy
Przejdźmy zatem do naszego zadania, czyli napisania scenariusza pokrywającego flow użytkownika. Zanim jednak do tego przystąpimy, musimy pobrać naszego frameworka. Skorzystamy z mojego ulubionego sposobu, czyli zaprzęgniemy mavena, aby się tym zajął. W głównym pom’ie dodajemy następujące konfiguracje:
- biblioteka wykorzystywana przez Gatlinga
<dependencies> <dependency> <groupId>io.gatling.highcharts</groupId> <artifactId>gatling-charts-highcharts</artifactId> <version>2.2.4</version> <scope>test</scope> </dependency> </dependencies> - plugin odpowiedzialny za uruchamianie z poziomu mavena
<plugin> <groupId>io.gatling</groupId> <artifactId>gatling-maven-plugin</artifactId> <version>2.2.4</version> <configuration> <simulationsFolder>src/main</simulationsFolder> <simulationClass>scala.simulation.SimpleWaitSimulation</simulationClass> </configuration> <executions> <execution> <goals> <goal>execute</goal> </goals> </execution> </executions> </plugin>
Dodatkowo, w konfiguracji dodajemy ścieżkę ze źródłami oraz domyślną klasę naszej symulacji. Klasa ta musi dziedziczyć po obiekcie ‘Simulation’ z pakietu Gatlinga. Po stworzeniu klasy ‘SimpleWaitSimulation’, uruchamiamy symulację w konsoli poleceniem:
mvn gatling:execute
Powinniśmy dostać błąd:
Caused by: java.lang.IllegalArgumentException: requirement failed: No scenario set up
Błąd ten informuje nas, że nasza symulacja nie zawiera scenariusza, co oczywiście jest prawdą na tym etapie, ale potwierdza nam działanie szkieletu symulacji. Możemy zatem przejść dalej i skupić się na zakodowaniu naszego testu. Uruchamiamy wcześniej napisaną aplikację do testowania i ruszamy.
W pierwszej kolejności definiujemy podstawy komunikacji naszego testu z serwerem.
Aplikacja uruchamia się na standardowym adresie i porcie, zatem takie wartości przekazujemy. W Gatlingu za konfigurację komunikacji odpowiada klasa ‘http’. Ustawiamy adres bazowy, pod którym szukać należy naszej aplikacji. Nasz test będzie symulował uderzenia z przeglądarki, zatem ustawiamy odpowiednie nagłówki wykorzystywane przy requestach. Powstaje następujący kod:
val httpConf = http
.baseURL("http://localhost:8080")
.acceptHeader("text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8")
.acceptEncodingHeader("gzip, deflate")
.acceptLanguageHeader("en-US,en;q=0.5")
.userAgentHeader("Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:50.0) Gecko/20100101 Firefox/50.0")
Teraz możemy zaprogramować scenariusz, czyli krok po kroku wykonać to, co wykonuje symulowany użytkownik. Za tworzenie scenariusza odpowiada polecenie ‘scenario’. Na początku powołajmy instancję tego obiektu.
val scn = scenario("Simple Wait simulation")
W tym momencie mamy zalążek scenariusza i możemy zacząć dodawać poszczególne wywołania. W pierwszym kroku użytkownik wywołuje metodą GET endpointa ‘/getWaitTime’, a w odpowiedzi otrzymuje dane, które musi zapamiętać i wykorzystać w kolejnym etapie. Praca z Gatlingiem jest bardzo wygodna. Dostajemy masę użytecznych poleceń, dzięki którym możemy wykonywać różne operacje. Zarówno na wejściowych, jak i wyjściowych danych z testu. Na początku dodajemy wywołanie GET:
.exec(http("Take waiting time")
.get("/getWaitTime")
)
Całkiem proste. Powyższy kod wywoła tylko wskazanego endpointa. Brakuje nam pobrania odpowiedzi i zapamiętania wartości. Dodatkowo powinniśmy dostać kod statusu http równy 200. W naszym przypadku oznacza to, że wywołanie powiodło się, a serwer wyśle do nas jsona z polem o nazwie ‘result’. Wartość tę musimy zapamiętać i wykorzystać do dalszego procesowania użytkownika. Uzupełnijmy nasze proste wywołanie o niezbędne elementy:
val scn = scenario("Simple Wait simulation")
.exec(http("Take waiting time")
.get("/getWaitTime")
.check(status.is(200))
.check(jsonPath("$.result").saveAs("waitTime"))
)
Podobnie jak wcześniej skorzystaliśmy z wbudowanych narzędzi Gatlinga. ‘Check’ operuje na odpowiedzi wszystkich requestów. Metodą ‘status’ sprawdzamy kod odpowiedzi, czyli oczekujemy wartości 200. Metodami ‘jsonPath’ wyciągamy niezbędne informacje z odpowiedzi, a poleceniem ‘saveAs’ zapamiętamy te dane. Warto wspomnieć, iż Gatling do każdego użytkownika tworzy sesję użytkownika, do której możemy zarówno zapisywać, jak i odczytywać wartości. Istnieje także możliwość odczytywania wielu wartości w ramach jednego żądania, wówczas musimy tylko skopiować polecenie ‘check’ i odpowiednio ustawić, co i jak chcemy zapisać.
Idąc dalej, użytkownik wywołuje endpoint ‘/wait’ przekazując wartość z pierwszego żądania, a otrzymując inną wartość, którą także zapamiętujemy. Postępując zgodnie z opisem, kodujemy:
.exec(http("Wait for")
.post("/wait")
.formParam("""waitTime""", "${waitTime}")
.check(status.is(200))
.check(jsonPath("$.result").saveAs("realWaitTime"))
)
Nowym elementem, jaki tutaj wykorzystaliśmy, jest polecenie ‘formParam’. Jak nazwa sugeruje, służy ono do przekazywania parametrów do wywołania. Poza nazwą, w formularzu podajemy wartość: bezpośrednio lub za pomocą zmiennej. W tym przypadku odczytaliśmy z sesji wcześniej zapisaną wartość.
W kolejnym etapie użytkownik czeka kilka sekund, zanim wywoła następną operację. Aby to osiągnąć, w prosty sposób możemy wykorzystać wbudowaną metodę ‘pause’. Jako parametr przyjmujemy wartość, oznaczającą ilość czasu, którą symulowany użytkownik ma czekać przed wykonaniem następnego kroku. Polecenie proste, ale użyteczne. Możemy w ten sposób symulować np. wypełnianie formularza czy klikanie w jakiś przycisk.
.pause(5 seconds)
W ostatnim kroku użytkownik wywołuje tak, jak na początku polecenie GET, ale tym razem przekazując wartość. W odpowiedzi nie otrzymuje JSONa, ale prosty ciąg znaków. Rezultat odpowiedzi sprawdzimy czy zawiera interesującą nas wartość przekazaną w żądaniu.
.exec(http("User stop")
.get("/stop/${realWaitTime}")
.check(status.is(200), bodyBytes.saveAs("endMessageBody"))
.check(substring("${realWaitTime}").exists)
)
Poza wykorzystywanymi poprzednio poleceniami, użyliśmy tutaj kolejnej metody Gatlinga, tym razem do operacji na stringach. ‘Substring’ pozwala w prosty sposób operować na ciągach znakó,w np. znajdując podaną na wejściu frazę. Serwer powinien wysłać nam “stringa” zawierającego przekazany na wejściu parametr. Dlatego też weryfikujemy, czy otrzymana odpowiedź zawiera ów wartość.
Cały przepływ użytkownika mamy już zakodowany. Na końcu, zbierzmy wszystkie kroki w jednym miejscu. Każde polecenie do wykonania operacji użytkownika zwraca instancję scenariusza, zatem w prosty sposób możemy agregować polecenia. W efekcie nasz wynikowy scenariusz wygląda następująco:
val scn = scenario("Simple Wait simulation")
.exec(http("Take waiting time")
.get("/getWaitTime")
.check(status.is(200))
.check(jsonPath("$.result").saveAs("waitTime"))
)
.exec(http("Wait for")
.post("/wait")
.formParam("""waitTime""", "${waitTime}")
.check(status.is(200))
.check(jsonPath("$.result").saveAs("realWaitTime")))
.pause(5 seconds)
)
.exec(http("User stop")
.get("/stop/${realWaitTime}")
.check(status.is(200), bodyBytes.saveAs("endMessageBody"))
.check(substring("${realWaitTime}").exists)
)
W następnym kroku zajmiemy się konfiguracją i przygotowaniem ruchu użytkowników.
Pierwsze strzały
Mamy gotowy scenariusz, aby jednak nasza symulacja została poprawnie uruchomiona, trzeba ją jeszcze skonfigurować. W tym celu musimy wywołać metodę ‘setUp()’, która połączy nam wszystkie elementy tzn.: komunikację, scenariusz i ruch użytkowników. Nie jest to skomplikowana operacja. W jej efekcie powstanie jedna linijka kodu:
setUp(scn.inject(atOnceUsers(1)).protocols(httpConf))
Na początek, w celu sprawdzenia czy wszystko poprawnie działa, uruchomimy test tylko z jednym użytkownikiem. Użyjemy tutaj polecenia ‘atOnceUsers(1)’, które symuluje właśnie określoną liczbę użytkowników na start testu. Wszystko gotowe, zatem możemy uruchamiać. Odpalamy konsolę i uruchamiamy polecenie:
mvn gatling:execute
Jeśli wszystko poszło OK, to dostajemy:
[INFO] BUILD SUCCESS
Przeglądamy logi i weryfikujemy czy otrzymaliśmy następujące wyniki:
--- Requests ------------------------------------------------------------------
Global (OK=3 KO=0 )
Take waiting time (OK=1 KO=0 )
Wait for (OK=1 KO=0 )
User stop (OK=1 KO=0 )
Jeśli mamy takie wypiski, to wszystko jest w jak najlepszym porządku.
Przy takiej konfiguracji testu mamy w sumie 3 uderzenia do aplikacji, zatem ciężko wnioskować i mówić tu o jakichś wynikach do analizy. Testowo możemy spojrzeć sobie na raport, który wygenerowany został automatycznie na koniec testu. Wystarczy poszukać ‘Please open the following file:’ gdzie znajduje się strona html z wszystkimi wynikami naszego testu. Dokładniej przyjrzymy się temu, gdy uderzeń będzie o wiele więcej. Ustalmy zatem większy ruch.
“Och, ilu tych użytkowników”
Ruch jednego użytkownika nie jest w stanie zbadać nam wydajności aplikacji. Dlatego musimy zastanowić się, jaki ruch chcemy wygenerować. Oczywiście, jeśli mowa o prawdziwych aplikacjac,h to musimy wziąć pod uwagę charakterystykę działania naszej aplikacji w środowisku produkcyjnym. Czy jest to ruch liniowy, skokowy, impulsowy itp. I to właśnie rozkład ruchu na produkcji powinien determinować, w jaki sposób generujemy ruch użytkowników w systemie w trakcie testu.
Gatling ma kilka sposobów generowania ruchu. Ponieważ metod jest wiele, warto spojrzeć do dokumentacji - http://gatling.io/docs/current/general/simulation_setup/. My zakładamy, że w każdej sekundzie do systemu będzie wpadać określona liczba nowych użytkowników, postępujących według poprzednio opisanego scenariusza. Przy konfiguracji symulacji wykorzystamy dwie metody:
- ’nothingFor()’ - do rozładowania poprzedniego ruchu
- ‘constantUsersPerSec() during() randomized’ - do symulowania określonej liczby użytkowników przez ustalony czas.
W początkowej fazie należy wykonać wstępne testy i określić wartości w jakich będziemy się poruszać. Nie ma sensu przeprowadzać godzinnego testu, jeśli aplikacja “wywali się” w ciągu pierwszych sekund. Po wykonaniu takich szybkich testów, możemy przystąpić do finalnej konfiguracji.
Dobrym rozwiązaniem jest przeprowadzanie testów w ramach kilku iteracji. Każda z nich składa się z fazy obciążenia aplikacji użytkownikami, a następnie czasu potrzebnego na zakończenie przetwarzania wszystkich użytkowników. Wówczas możemy uruchomić następne powtórzenie, ale zwiększając liczbę użytkowników. O tym jak przeprowadzać testy wydajnościowe, można by napisać następny artykuł czy nawet książkę.
Wróćmy zatem do naszej symulacji. Wykonamy pięć iteracji, każda będzie się składać z obciążenia użytkownikami trwającym 100 sekund, następnie przez 60 sekund będziemy czekać zanim uruchomimy następne powtórzenie. Zaczniemy od 20 nowych użytkowników na sekundę i będziemy zwiększać ich liczbę o kolejnych 10 w następnych iteracjach. Podobnie jak w przypadku scenariusza, możemy agregować poszczególne fazy testu. Dla powyższych założeń mamy następującą konfigurację:
setUp(scn.inject(constantUsersPerSec(20) during(100 seconds) randomized,
nothingFor(60 seconds),
constantUsersPerSec(30) during(100 seconds) randomized,
nothingFor(60 seconds),
constantUsersPerSec(40) during(100 seconds) randomized,
nothingFor(60 seconds),
constantUsersPerSec(50) during(100 seconds) randomized,
nothingFor(60 seconds),
constantUsersPerSec(60) during(100 seconds) randomized
).protocols(httpConf))
Konfiguracja gotowa, czas na uruchomienie.
Wielkie strzelanie
W końcu dotarliśmy do momentu, w którym możemy sprawdzić, jak zachowuje się nasza aplikacja przy dużym obciążeniu. Wszystko gotowe, uruchamiamy symulację i idziemy na kawę. Jak już wypijemy, jest szansa, że nasz test się zakończył. Wówczas w logach, tak jak poprzednio, otrzymamy:
[INFO] BUILD SUCCESS
Następnie szukamy, gdzie wygenerowany został raport: ‘Please open the following file:’. Odpalamy i naszym oczom pojawia się automatycznie wygenerowany raport.
Przejrzyjmy otrzymane wyniki. Pierwsze błędy zaczęły się pojawiać przy ruchu 50 nowych użytkowników na sekundę. Całkiem nieźle. Widać jednak, że aplikacja przetwarzała cały ruch tylko przy 20 nowych użytkownikach na sekundę. Już przy kolejnej iteracji widać tendencję wzrostową aktywnych użytkowników. Oznacza to, że aplikacja nie radziła sobie z całym ruchem, jaki był generowany i część żądań była kolejkowana. Przy kolejnych fazach widać, że tendencja się jeszcze zaostrzała i przy 50 użytkownikach czas oczekiwania na aplikację był tak długi, że “leciały” timeouty. Wiemy oczywiście z czego to wynika. Użycie “sleep” z dużymi wartościami jest mało wydajne. Jeśli to usuniemy, otrzymamy dużo większe wartości.
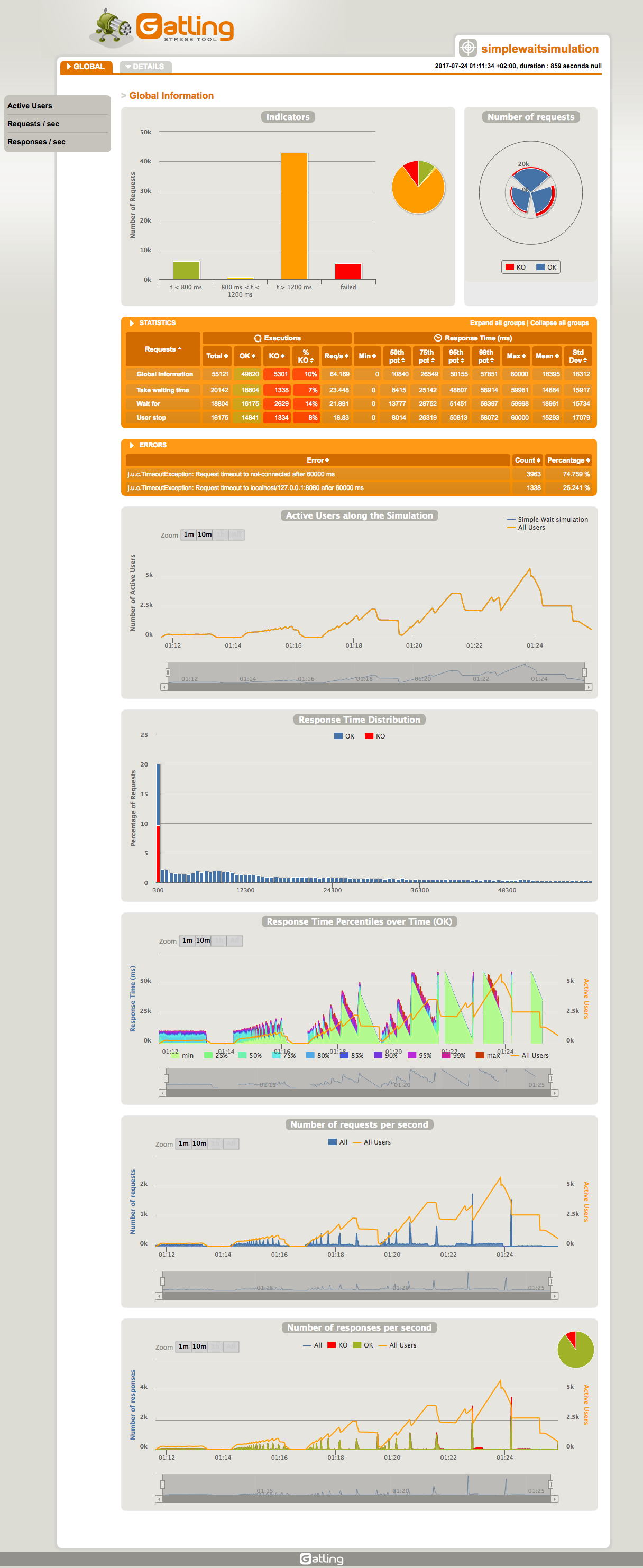
Czy nie jest wspaniałe, że Gatling wygenerował za nas wyniki i pokazał w graficznej formie? Jak dla mnie super. Możemy sprawdzić podstawowe dane, takie jak liczbę aktywnych użytkowników, czasy odpowiedzi, liczbę żądań i odpowiedzi w czasie. Dodatkowo, możemy wybrać jeden krok i przeanalizować w izolacji w ten sam sposób. Poza tym, przedstawione mamy statystyki w liczbach, takie jak, minimalny i maksymalny czas, średnia, odchylenie standardowe czy liczba requestów z podziałem na zakończone sukcesem i błędem. Gatling przedstawia także czasy poszczególnych udziałów procentowych obsługi żądań. Dostajemy zatem informacje ile trwało 50%, 75%, 95% i 99% wywołań. Ten prosty raport naprawdę sprawia, że praca z Gatlingiem i testami wydajnościowymi jest przyjemnością.
Testowanie wydajności poprzez Gatling
Podsumowując moje doświadczenia w pracy z Gatlingiem, mogę stwierdzić, że wybór tego narzędzia był “strzałem w dziesątkę”. Jego istotną zaletą jest to, że scenariusze testowe są pisane jako zwykły kod. Nie ma problemu, aby scenariusz przygotowywało więcej osób. Problemy z “mergowaniem” zazwyczaj są minimalne. Kod jest czytelny i nie ma potrzeby pisania dodatkowej dokumentacji.
Gatling zawiera ponadto masę pomocniczych poleceń. Na stronie http://gatling.io/ dostępna jest użyteczna dokumentacja, w której w przejrzysty sposób wyjaśniono dostępne funkcje. Możemy korzystać bezpośrednio z poleceń JMX’a naszego serwera, czy tworzyć komunikaty na kolejkach JMS. Produkt jest rozwijany. Powstają nowe wersje, a błędy są rozwiązywane. W przypadku problemów, można skorzystać z pomocy społeczności odpowiedzialnej za rozwój narzędzia.
Jak każde narzędzie, również Gatling ma ograniczoną liczbę funkcji. Jeśli w dokumentacji nie znajdziemy potrzebnych poleceń, możemy spróbować zapisać np. dane w sesji i posiłkować się kodem napisanym przez nas w scali. Daje nam to ogrom możliwości. Zapewnia elastyczność w rozwiązywaniu specyficznych przypadków, które niestety spotykamy praktycznie codziennie.
Kolejnym ważnym ułatwieniem wykonywania testów jest raport końcowy. Automatycznie generowane wykresy i podstawowe statystyki bardzo przydają się w początkowej i końcowej fazie testu. Jeśli chcemy, szybko przetestować aplikację z ogromnym ruchem, nie ma problemu -zmieniamy 2-3 linijki i odpalamy. Po kilku chwilach mamy dostępne wyniki i wiemy, czy aplikacja daje radę, czy już nie. Tej funkcjonalności mi zawsze brakowało np. w JMeterze, gdzie raportem było trzeba zająć się samemu po testach. W przypadku Gatlinga wyniki możemy bez problemu dołączyć do dokumentacji produktu, jako potwierdzenie naszej ciężkiej i dobrze wykonanej pracy przy pisaniu aplikacji i testach wydajnościowych. Polecam każdemu wypróbowanie Gatlinga do testów wydajnościowych. Mi narzędzie to bardzo mocno przypadło do gustu.
Podobne wpisy





